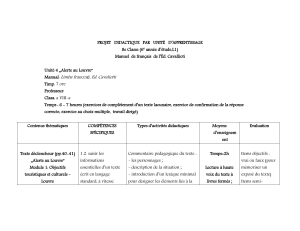
Comparaison des validités prédictives des mesures d`un

Dans son article très influent publié dans Journal
of Marketing Research, Churchill (1979, p. 66)
déclare la phrase suivante : « En somme, les marketers
sont beaucoup mieux servis par les mesures multi-
items que par les mesures mono-item de leurs
construits et ils seraient avisés de prendre le temps de
les développer. » En effectuant cette recommanda-
tion, Churchill suivait la tradition dominante issue de
la psychométrie concernant les mesures des capacités
et des traits (voir par exemple Guilford, 1954 ; et sur-
tout Nunnally, 1978). Dans les 28 années qui ont
suivi l’article de Churchill, les chercheurs ont de plus
en plus utilisé des échelles multi-items pour mesurer
les construits marketing. Plus précisément, ils ont
Recherche et Applications en Marketing, vol. 23, n° 1/2008
Comparaison des validités prédictives des mesures d’un même
construit des échelles mono-item et des échelles multi-items
Lars Bergkvist
Professeur visitant en marketing
Yonsei Graduate School of Business, Séoul
John R. Rossiter
Marketing Research Innovation Centre, Université de Wollongong, Australie
Rotterdam School of Management, Erasmus University, Pays-Bas
Cet article a été publié en mai 2007 dans Journal of Marketing Research, 44, 2, 175-184, traduit par Dina Rasolofoarison et reproduit avec la per-
mission de JMR et de l’American Marketing Association qui en détient le copyright. L’AMA ne pourra être tenue responsable d’éventuelles
erreurs survenues lors de la traduction.
Les auteurs remercient l’aide à la recherche de l’Association of Swedish Advertisers, de la Swedish Newspaper Publishers’ Association et de
l’Advertising Association of Sweden.
Ils peuvent être contactés aux adresses électroniques suivantes : [email protected] ; jrossite@uow.edu.au
SÉLECTION INTERNATIONALE
RÉSUMÉ
Cette recherche compare les validités prédictives des mesures mono-item et multi-items de l’attitude envers la publicité
(APub) et de l’attitude envers la marque (AMarq), qui font partie des construits les plus mesurés en marketing. Les auteurs évaluent
la capacité de APub à prédire AMarq dans des tests de quatre publicités presse concernant différents nouveaux produits. Aucune dif-
férence n’est trouvée dans les validités prédictives des mesures mono- et multi-items. Les auteurs concluent que, pour les
nombreux construits marketing constitués d’un objet concret unique et d’un attribut concret, tels que APub et AMarq, des
mesures mono-item doivent être utilisées.
Mots clés : Attitude vis-à-vis d’une publicité, attitude vis-à-vis d’une marque, mesures à un seul item comparées à plusieurs
items.
05•Bergkvist-Rossiter 13/03/08 11:07 Page 81

utilisé des échelles multi-items pour mesurer l’attribut
des construits (c’est-à-dire l’attitude, la qualité, l’ap-
préciation) qu’il faut différencier de l’objet du
construit (c’est-à-dire une entreprise, une marque,
une publicité). Dans sa procédure C-OAR-SE de
développement d’échelle, Rossiter (2002) conclut
que si un objet peut être conceptualisé de façon
concrète et unique, alors il ne requiert pas plusieurs
items pour être mesuré, pas plus qu’un attribut pouvant
être défini comme concret. Cependant, l’article de
Churchill, comme celui de Peter (1979) sur la fiabilité
des échelles multi-items également publié dans JMR,
ont influencé la mesure des construits marketing à tel
point qu’il est virtuellement impossible d’avoir un
article accepté en marketing si les concepts princi-
paux ne sont pas mesurés par des échelles multi-
items (encore une fois, les items multiples représentant
l’attribut du construit). L’utilisation de mesures
multi-items est également encouragée par la popularité
croissante de l’analyse en équations structurelles
(LISREL), un ensemble de techniques statistiques
pour lesquelles les mesures multi-items sont la
norme, quel que soit le type de construit mesuré
(voir par exemple, Anderson et Gerbing, 1988 ;
Baumgartner et Homburg, 1996).
Il est en revanche peu commun que les praticiens
du marketing utilisent, comme les chercheurs, des
échelles multi-items pour mesurer les mêmes
construits. Les praticiens semblent préférer les
mesures mono-item, non pas pour des raisons théo-
riques comme celles proposées par Rossiter (2002),
auxquelles les praticiens sont peu sensibles, mais
pour des raisons pratiques de minimisation des coûts et
des refus de la part des répondants. Parmi ces
construits communs, on peut trouver l’attitude envers
la publicité ou APub, que les praticiens appellent
l’« appréciation » de la publicité ou APPub, et l’atti-
tude envers la marque, que les praticiens et beaucoup
de chercheurs appellent « brand attitude », symbolisée
par AMarq ou parfois Am. Ces construits populaires
sont l’objet d’étude de la présente recherche.
Notre recherche utilise le critère le plus décisif du
point de vue de la prise de décision, à savoir la validité
prédictive (Aaker et alii, 2005) et démontre que des
mesures mono-item de ces construits sont tout aussi
valides que des mesures multi-items. Le fait que des
validités prédictives soient égales signifie que les
tests théoriques et les résultas empiriques seraient
similaires si des mesures mono-item étaient utilisées à
la place des habituelles mesures multi-items de ces
construits. Nous allons maintenant passer en revue
les arguments pour et contre les mesures multi-items
afin de développer nos hypothèses.
ARGUMENTS EN FAVEUR
DES MESURES MULTI-ITEMS
Pour quelles raisons le monde académique
estime-t-il que les mesures multi-items sont
meilleures que les mesures mono-item ? L’un des
arguments théoriques les plus populaires chez les
chercheurs trouve sa source dans l’article de
Churchill (1979), ainsi que dans celui de Peter
(1979), également publié dans JMR, sur la fiabilité :
les mesures multi-items seraient intrinsèquement
plus « fiables » car elles permettent des calculs de
corrélations entre les items qui, si elles sont positives et
génèrent une corrélation moyenne élevée (c’est-à-
dire un coefficient alpha élevé), indiquent la « cohé-
rence interne » de tous les items et représentent ainsi
l’attribut sous-jacent. Cet argument de la « fiabilité »
doit être explicité (voir Rossiter, 2002). Tout d’abord,
le coefficient alpha ne devrait jamais être utilisé sans
avoir au préalable étudié l’unidimensionnalité de
l’échelle (Cortina, 1993) ; cela peut être vérifié par
une analyse factorielle ou, plus sûrement, par le calcul
du coefficient bêta de Revelle (1979) qui constitue
un bon test d’unidimensionnalité. Une fois l’unidi-
mensionnalité vérifiée, le coefficient alpha n’est réel-
lement un indicateur de la validité de mesure par
l’ensemble des items que pour un certain type d’attri-
buts, les attributs élicitants (voir Rossiter, 2002). Les
meilleurs exemples en sont les traits de personnalité
(ainsi que les états de court terme correspondants) et
les capacités. Le coefficient alpha n’est pas appro-
prié pour les deux autres types d’attributs, les attri-
buts « concrets » (qui représentent le type d’attributs
utilisés dans la présente recherche dans les construits
APub et AMarq) et les attributs « formés », tels que la
classe sociale (qui est un attribut composé d’une
somme de notes sur des variables démographiques). Si
Lars Bergkvist, John R. Rossiter
82
05•Bergkvist-Rossiter 13/03/08 11:07 Page 82

l’attribut du construit est concret, le coefficient alpha
n’est pas un critère approprié de l’évaluation de la
mesure car il n’est pas nécessaire d’avoir plusieurs
items pour le mesurer. Un argument logique contre la
nécessité d’un coefficient alpha élevé est donné par
Gorsuch et McFarland (1972), qui mettent l’accent
sur le fait qu’une mesure non fiable ne peut pas former
une relation n’atteignant pas un haut degré de vali-
dité prédictive et qu’ainsi, une mesure mono-item qui
aurait une validité prédictive équivalente à une
mesure multi-items devrait être considérée comme
suffisamment fiable pour remplacer cette dernière.
Cronbach (1961, p. 128) dit également : « Si la validité
prédictive est satisfaisante, une faible fiabilité ne doit
pas nous décourager d’utiliser le test », qui signifie
ici la mesure prédictive. Sur la base de ces argu-
ments, nous concluons que la fiabilité ne doit pas
entrer en ligne de compte si la mesure mono-item
obtient une validité prédictive équivalente à la
mesure multi-items.
Un second argument théorique pour l’utilisation
d’une mesure multi-items est qu’elle capture davantage
d’information qu’une mesure mono-item. Cet argu-
ment doit être divisé en deux parties. Premièrement, on
considère qu’une mesure multi-items capture davan-
tage d’information qu’une mesure mono-item car
elle est « plus à même de capturer toutes les facettes du
construit étudié (Baumgartner et Homburg, 1996,
p. 143). Cependant, la présence de différences
facettes dans un attribut ou un objet signifie que ce
construit ne peut être considéré comme un attribut
concret d’un objet concret singulier dans la terminolo-
gie de Rossiter (2002). Ainsi, cet argument ne
concerne pas la présente recherche, étant donné que
nous étudions deux construits doublement concrets.
Deuxièmement, on considère qu’une mesure
multi-items capture davantage d’information qu’une
mesure mono-item car elle offre plus de catégories
de réponses. Il est nécessaire d’insister sur le fait que
ce n’est pas la multiplicité des items qui est impor-
tante ici mais plutôt le nombre de catégories dispo-
nibles, ou autrement dit, la « longueur » de l’échelle de
réponse. Une échelle multi-items fournit de facto une
échelle de réponse (potentiellement) plus discrimina-
toire qu’une mesure mono-item. Par exemple, une
mesure de APub composée de trois items (i) sur des
échelles de réponse en sept points (r) peut générer
343 (ri) réponses uniques différentes et 19 totaux
de scores différents (i×r−[i−1]). Ce nombre
relativement élevé de scores permet de « faire des
distinctions relativement fines entre les gens »
(Churchill, 1979, p. 66) ou, sur une même ligne, de
catégoriser les gens dans un grand nombre de
groupes (Nunally et Bernstein, 1994, p. 67). Cet
argument est valide tant que le répondant est capable
de discriminer un grand nombre de catégories d’un
même attribut (Viswanathan, Sudman et Johnson,
2004). Il s’ensuit qu’une mesure multi-items de la
variable prédictive devrait montrer une plus grande
corrélation avec la mesure de la variable dépendante,
soit une plus grande validité prédictive. De plus,
découlant du même argument, il s’ensuit que la corré-
lation entre une variable prédictive mono-item et une
variable dépendante multi-items devrait être plus
grande que si les deux sont des mesures mono-item, et
que la corrélation entre une variable prédictive multi-
items et une variable dépendante multi-items devrait
être la plus grande de toutes. Cette deuxième partie
de l’argument conduit à trois hypothèses.
H1: La corrélation entre une variable prédictive
multi-items et une variable dépendante mono-
item est supérieure à la corrélation entre une
variable prédictive mono-item et la même
variable dépendante.
H2: La corrélation entre une variable prédictive
mono-item et une variable dépendante multi-
items est supérieure à la corrélation entre la
même variable prédictive et une variable dépen-
dante mono-item.
H3: La corrélation entre une variable prédictive
multi-items et une variable dépendante multi-
items est supérieure à la corrélation entre deux
mesures mono-item.
ARGUMENTS EN FAVEUR
DES MESURES MONO-ITEM
La préférence des praticiens pour les mesures
mono-item n’est pas fondée sur des raisons théo-
riques mais sur des raisons pratiques : des mesures
mono-item minimisent le nombre de refus de la part
Comparaison des validités prédictives des mesures d’un même construit des échelles mono-item et des échelles multi-items 83
05•Bergkvist-Rossiter 13/03/08 11:07 Page 83

des répondants et réduisent les coûts de collecte et de
traitement des données. Le seul argument théorique
(vs empirique) en faveur de l’utilisation de mesures
mono-item a été proposé par Rossiter (2002) dans sa
procédure C-OAR-SE de développement d’échelle.
Rossiter avance qu’une mesure mono-item est suffi-
sante si le construit est, dans l’esprit des évaluateurs
(par exemple les répondants d’une enquête), tel que
(1) l’objet du construit est « singulier et concret », ce
qui signifie qu’il s’agit d’un objet pouvant être facile-
ment et uniformément imaginé, et (2) l’attribut du
construit est « concret », ce qui signifie également
qu’il peut être facilement et uniformément imaginé.
Dans les deux cas, « facilement et uniformément
imaginé » est un critère pris de la « théorie de
l’image » de Wittgenstein (1961). D’après des juge-
ments d’experts basés sur la procédure C-OAR-SE,
APub (ou APPub) et AMarq sont tous les deux de tels
construits.
Un argument empirique pour l’utilisation d’un
item unique peut être donné pour les mesures dans
lesquelles les multiples items représentant l’attribut
(dans la partie réponse de l’item) sont synonymes ou
ont pour but d’être synonymes (plus précisément,
quand ils sont des adjectifs synonymes). Un exemple
extrême est la mesure très connue de l’implication
personnelle de Zaichkowsky (1985) (qui, comme
construit, se réfère à l’implication personnelle envers
un objet, tel qu’une catégorie de produit ou une
publicité). Cette mesure utilise 20 paires bipolaires
d’adjectifs synonymes pour mesurer l’attribut de
« l’implication ». Deux autres exemples sont l’attri-
but « attitude » des construits APub et AMarq tels
qu’ils sont mesurés dans la recherche académique.
Sur la base d’une étude antérieure de Stuart, Shimp
et Engle (1987), Allen (2004) utilise huit paires d’ad-
jectifs synonymes pour mesurer APub. C’est un
nombre d’items exceptionnellement grand, il est plus
fréquent dans la recherche d’utiliser trois ou quatre
items synonymes pour mesurer APub ou AMarq car
c’est un nombre suffisant pour atteindre un coeffi-
cient alpha élevé. L’argument empirique en faveur de
l’utilisation d’un item unique dans de telles mesures
est apparu parce que Drolet et Morrison (2001) ont
trouvé que l’accroissement du nombre d’items syno-
nymes produit un problème fréquent : plus le nombre
d’items synonymes que le chercheur cherche à générer
est grand, plus il y a de chances d’inclure des items qui
ne sont pas de parfaits synonymes de l’attribut des-
criptif original. De plus, ceux qui ne sont pas syno-
nymes ont peu de chances d’être détectés. Drolet et
Morrison trouvent que, quand le nombre total
d’items augmente, les répondants sont plus enclins à
répondre de la même façon à un item qui ne serait
pas équivalent (non synonyme, et donc sans validité de
contenu) qu’aux autres items de l’échelle. Drolet et
Morrison incluent « non-familier/familier » comme
item non équivalent dans la batterie des items mesurant
APub et trouvent que la différence moyenne absolue
entre les notations des items équivalents et non-
équivalents diminue quand le nombre d’items est
augmenté de deux items à cinq puis à dix items (l’un
d’entre eux étant l’item non équivalent). La diffé-
rence moyenne entre le premier item et l’item non
équivalent diminue d’approximativement 20 % en
passant de deux items à cinq items et d’approximati-
vement 38 % en passant de deux items à dix items.
Ces résultats montrent que l’addition de nombreux
bons items cache la présence de mauvais items. Si les
mauvais items sont corrélés positivement aux bons
items, le coefficient alpha augmente, ce qui dissuade
généralement les chercheurs de rechercher les mau-
vais items. Paradoxalement, les mauvais items pour-
raient augmenter la validité prédictive d’une mesure
multi-items si la variation des scores des nouveaux
items est corrélée à la variation des scores de la
variable dépendante, ce qui est probable si le mau-
vais item est aussi une autre variable prédictive de la
variable dépendante. De plus, Drolet et Morrison
appliquent la technique de prévisions d’experts pour
estimer mathématiquement la valeur information-
nelle des items additionnels dans une échelle (voir
aussi Morrison et Schmittlein, 1991). En utilisant
l’hypothèse des erreurs modérément corrélées, ils
montrent que les items additionnels apportent peu
d’information ; deux items ayant une corrélation des
erreurs de 0,60 apportent l’équivalent de 1,25 item
indépendant, et une infinité d’items corrélés à 0,60
apportent autant d’information que 1,67 item indé-
pendant. Ils concluent qu’un ou deux bons items peu-
vent surpasser une échelle composée de multiples
items, si ces multiples items ont une corrélation
modérée ou forte de leurs erreurs, ce qui est probable
s’ils sont présentés ensemble. L’argument de Drolet
et Morrison est entièrement mathématique, ils ne tes-
tent pas empiriquement la valeur informationnelle
additionnelle des items d’un questionnaire. (Dans la
Lars Bergkvist, John R. Rossiter
84
05•Bergkvist-Rossiter 13/03/08 11:07 Page 84

présente recherche, nous étudions empiriquement la
valeur de l’information additionnelle en regardant si
des items multiples augmentent la validité prédictive.
Si des items multiples ajoutent de l’information, une
mesure multi-items d’une variable prédictive devrait
prédire les scores d’une variable dépendante avec de
plus faibles déviations, résultant ainsi en un ret un
R2plus élevés.) En raison des problèmes d’erreurs
systématiques dans les scores obtenus par des
mesures multi-items et de leur démonstration mathé-
matique qui montre que des items additionnels der-
rière le premier item n’améliorent pas la prédiction
des résultats, Drolet et Morrison recommandent l’uti-
lisation de mesures mono-item. Il faut cependant pré-
ciser que leur recommandation ne s’applique qu’aux
construits qui constituent les classifications les plus
basiques des objets et attributs, c’est-à-dire les objets et
attributs doublement concrets (Rossiter, 2002).
Un autre argument empirique en faveur des
mesures mono-item vient de la volonté d’éviter les
biais de similarité des méthodes. Les biais de similarité
des méthodes apparaissent quand la corrélation entre
deux construits ou plus est augmentée parce qu’ils
sont mesurés de la même façon (voir par exemple
Williams, Cote et Buckley, 1989). Les biais de simila-
rité des méthodes peuvent apparaître dans les nom-
breux items d’une mesure multi-items, et peuvent
ainsi venir accroître artificiellement son coefficient
alpha. Par exemple, la corrélation entre APub et AMarq
tendrait à augmenter si chaque construit était mesuré
avec plusieurs items de même format (par exemple
des items « sémantiques-différentiels ») plutôt
qu’avec un item unique de même format. Les biais
de similarité des méthodes peuvent aussi accroître la
corrélation entre deux mesures mono-item si un format
identique est utilisé pour les deux. Pour finir, les
biais de similarité des méthodes peuvent également
augmenter la corrélation entre deux mesures mono-
item si des attributs descriptifs similaires (vs diffé-
rents) sont utilisés (par exemple « bon/mauvais »
pour APub et « aime/aime pas » pour AMarq). Ainsi,
nous développons trois hypothèses concernant les
biais de similarité des méthodes.
H4: La corrélation entre deux construits est plus
grande si ces construits sont mesurés avec des
items multiples de formats identiques que s’ils
sont chacun mesurés avec un item unique de for-
mat identique.
H5: La corrélation entre deux construits est plus
grande si ces construits sont mesurés avec des
mesures mono-item de formats identiques que
s’ils sont mesurés avec des mesures mono-item
de formats différents.
H6: La corrélation entre deux construits est plus
grande si ces construits sont mesurés avec des
items uniques employant le même attribut des-
criptif que s’ils sont mesurés avec des items
uniques employant des attributs descriptifs diffé-
rents.
Le Tableau 1 résume les arguments pour et contre
les mesures multi-items et la façon de tester ces argu-
ments si elles existent. Il existe deux tests empiriques
importants pouvant être conduits (voir argument 3
dans les deux listes du Tableau 1). L’un des tests est
fondé sur l’argument de « discriminabilité » des
items multiples et est un test de validité prédictive
(H1,H
2et H3). L’autre test concerne les sources
potentielles des biais de similarité des méthodes (H4,
H5et H6).
Déterminer la validité
Comment un chercheur peut-il décider si une
mesure mono-item d’un construit donné est aussi
valide qu’une mesure multi-items du même construit ?
La procédure C-OAR-SE de Rossiter (2002) affirme
que c’est totalement une question de validité de
contenu des mesures alternatives. Bien que des entre-
tiens non directifs des consommateurs puissent être
nécessaires comme input, la validité de contenu est
au final déterminée par des jugements d’experts, et
non par des recherches quantitatives ou des tests sta-
tistiques, à l’exception du calcul de la concordance
entre les juges. Cependant, le jugement d’experts
n’est pas une option dans la présente recherche. En
effet, elle étudie des mesures existantes pour les-
quelles les jugements de validité de contenu faits
ex post n’offriraient pas plus qu’une validité faciale
qui n’est pas un type valide de validité car il ne
révèle pas les items qui ont été considérés ni ceux qui
ont été rejetés, et ainsi ne montre pas comment les
items valides ont été sélectionnés (Rossiter, 2002).
La méthode psychométrique habituelle de com-
paraison de validité consiste à examiner comment
chaque mesure prédit les mesures des résultats étu-
Comparaison des validités prédictives des mesures d’un même construit des échelles mono-item et des échelles multi-items 85
05•Bergkvist-Rossiter 13/03/08 11:07 Page 85
 6
7
8
9
10
11
12
13
14
15
16
17
6
7
8
9
10
11
12
13
14
15
16
17
1
/
17
100%