6 - AMPCfusion

UE11 Parcours spécifique 1 –
Clinical research – Cours n°6
02/12/2015
Mehdi BENCHOUFI
RT :Laure N’GOM et Lilia OUCHIHA
RL : Antoine CARLI
BIOSTATISTICS BASICS
Formulating a study question
Practice with R & RStudio
Plan :
I. Random variable
A- Discrete variables
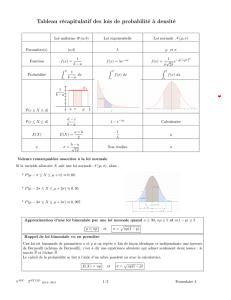
1) Probability mass function
2) Expectation value
3) Variance
4) Usual Random Variable
B- Continuous variables and density
1) Distribution function
2) Expectation value
3) Variance
4) Uniform RV
II. Practice

I. Random variable
What is a random variable?
Let’s consider a random experiment. Any output of the experiment is called
an “outcome event”.
On s’intéresse à une donnée : la variable aléatoire (ex : la taille des élèves de
la classe).
X : Ω R
X : variable aléatoire. Dans notre exemple, une fonction donne à chaque
individu sa taille, la variable aléatoire qui lui correspond.
Ω : l’univers des possibles. Dans notre exemple l’univers c’est la classe.
R : les réels
Il existe deux types de VA : les discrètes, représentées par une fonction
discontinue, constituée de points seulement ; et les continues, qui forment
un même trait sur un repère orthonormé.
The experience :
- Flip a coin 1 time.
Here Ω={H,T} (H : heads, T : tails).
A trivial example of random variable X is to set X ({H})=1 and X ({T})=0.
On gagne si on fait pile, on perd si on tombe sur face.
- Now flip a coin n times.
Here Ω={H,T}n.
We can take for X the number of heads obtained when flipping the coin n
times.
Probability calculus:
Suppose you toss three fair coins. What is the probability of getting exactly
one heads?
- 3 pièces qu’on tire successivement
- 8 sorties également réparties en terme de probabilité : HHH, HHT, HTT..
- 3 combinaisons ont un seul côté pile:
E = {HTT, THT, TTH}

Et donc
P(E)=
et X : {HHH, HHT,…, TTT) R
A – Discrete variables
X prend des valeurs ponctuelles : 1 si une seule face pile est tombée sur les
3 lancés, 0 si il y en plus de 1 ou pas du tout.
If we take X to be a real valued random variable, whose target space E is any
countable set (N, Z, Q), the X is said to be discrete. The examples shown
below are discret RV.
1) Probability mass function
A discret random variable X has countably many values (xi) iϵN.
We set for any I ϵ N (les naturels).
p(xi)=P(X=xi)
La fonction de masse associe à une valeur possible sa probabilité.
This function (from X(Ω) to [0 ;1]) is called the probability mass function of
X.
Avec l’exemple utilisé au début, on a calculé que P(X=1).
2) Expectation value
The mean value, also called expectation, average, or expected value of
discrete RV X is
E(X) =
To generate RV for one X, you can take any function f:RR and then
consider f ∘ X : ΩR
so
E(f(X)) =
Remark : the mean value is often denoted µ.
3) Variance (V)
The Variance is a way to estimate the distance or dispersion of X values
from its mean, so if we note µ the mean, we are interested in the value of
E(X-µ), or more precisely the absolute value ∣E(X-µ)∣, since we consider a

value µ+xi and a value µ-xi as equidistant from the mean. In order to
prevent from using these absolute values (and for other “metric” reason),
we consider to estimate this dispersion with the variance defined as
var(X) = E [(X- µ)²]
4) Usual Random Variable
- Uniform discrete RV
C’est une VA avec des valeurs allant de 1 à n, avec chacune une
equiprobabilité de
n.
This is simply the random choice of one number among n numbers.
E(X) =
and Var(X) =
- E(X)²
- Bernouilli random variable
Two complementary event A and B, and A has probability p. Then take X
to be RV equal to 1 on {A} and 0 otherwise
Then E(X) = p
and Var(X) = p(1-p)
Quand p=1/2, cela veut dire que le dé est non truqué, chaque sortie à la
même probabilité.
- Binomial RV
Consider X to be the RV counting the number of successes in n
independent trials, each of which is a success with probability p.
Then E(X) = np
and Var(X) = np(1-p)
The Binomial law is a generalization of the Bernouilli law
- Poisson RV
A Poisson random variable with parameter λ>0, is a discrete RV given
by, for any iϵN

P(X=i)
E(X) = λ
Var(X) = λ
B – Continuous variables and density
La fonction densité :
X est continue s’il existe une fonction f telle que pour tout A ∈ à R :
P(X∈A)=
f est alors appelée fonction densité de X
Cette variable vérifie que la somme des probabilités de toutes les issues
possibles vaut 1, telle que :
1) La fonction de distribution :
Pour toute variable continue, on définit une fonction de distribution F telle
que :
F(a)= P(X≤a) =
Remarque : F’(x)= f(x) avec f la fonction densité définie ci-dessus.
Autrement dit, la fonction de densité est la dérivée de la fonction de
distribution.
2) Expectation value
Comparaison d’une variable continue et discrète via le calcul de
l’espérance :
L’espérance notée E est une moyenne telle que :
- Pour une variable discrète :
E(x)= Σ xi p(X=xi)
 6
7
8
9
10
11
12
6
7
8
9
10
11
12
1
/
12
100%