Méthode de Wilks : Utilisation Incorrecte en Sûreté

Siège social et bureaux : 111, Faubourg Saint Honoré, 75008 Paris. Tel : 01 42 89 10 89. Fax : 01 42 89 10 69. www.scmsa.eu
Société Anonyme au capital de 56 200 Euros. RCS : Paris B 399 991 041. SIRET : 399 991 041 00035. APE : 7219Z
La Méthode de Wilks :
Utilisation incorrecte pour les études de sûreté
par Bernard Beauzamy
Janvier 2016
Abstract
La "méthode de Wilks" consiste en un énoncé probabiliste extrêmement simple (niveau Termi-
nale) : étant donné un phénomène aléatoire quelconque, si on se fixe des boîtes d'égale proba-
bilité, on finira certainement par tomber dans chacune d'entre elles, au bout d'un nombre suf-
fisant de "runs" ou d'expérimentations. Cette méthode est souvent utilisée dans les études
probabilistes de sûreté, parce qu'elle permet de déterminer le nombre minimum de runs né-
cessaires (pour une expérience, pour un code de calcul), afin d'évaluer un risque avec un ni-
veau de sécurité jugé suffisant.
Mais l'utilisation qui en est faite est fondamentalement incorrecte : les ingénieurs l'appliquent
aux différentes lois qu'ils ont arbitrairement introduites sur les paramètres d'entrée du code,
alors qu'il faudrait l'appliquer à la loi de sortie du code. L'utilisation de cette méthode pour les
études probabilistes de sûreté est absolument à proscrire.
Utiliser, de manière aveugle, quelques milliers de runs d'un code de calcul qui dépend de di-
zaines de paramètres complexes, en espérant que Dieu, dans sa bienveillance, aura la gentil-
lesse de les guider vers les situations à risque, permettant ainsi de les identifier, relève de la
naïveté, de l'aveuglement, de la paresse. Un aveugle ivre, jetant au hasard une fléchette en
espérant qu'elle franchira une porte à peine entrebâillée, aurait des milliards de fois plus de
chances de succès.
Nous donnons ci-dessous un exemple très clair et complètement indiscutable, qui montre
pourquoi la méthode de Wilks est utilisée de manière fautive. Mais, au-delà de cette méthode,
c'est l'utilisation des probabilités en général, pour les approches de sûreté, qui est à re-
prendre : il est fondamentalement absurde de s'en remettre au hasard pour l'investigation
d'un phénomène que nous ne comprenons pas.
Société de Calcul Mathématique SA
Outils d'aide à la décision
depuis 1995

2
BB Wilks 2016/01
I. Présentation générale de la méthode
La méthode est présentée dans de nombreux articles. Retenons l'un d'eux : "Estimation d'un
quantile concourant à la maîtrise d'un dimensionnement", présenté lors du 16ème Congrès de
Maîtrise des Risques et de Sûreté de Fonctionnement - Avignon 6-10 octobre 2008, communi-
cation 1Z-2 pages 1-6, par André Cabarbaye (CNES/CAB Innovation) et Roland Laulheret
(CNES)
http://cabinnovation.drupalgardens.com/sites/cabinnovation.drupalgardens.com/files/fichiers/LBD16_1.pdf
La méthode de Wilks [1] est la méthode la plus employée à ce jour en thermo-hydraulique nu-
cléaire pour estimer un quantile. Elle permet de déterminer le nombre minimum N de simula-
tions nécessaires à l’obtention d’un majorant de la valeur d’un quantile
,.T
Ce nombre est donné par la formule de Wilks, qui résulte directement de l’expression de
l’intervalle de confiance d’une loi binomiale :
1
11
NNi
i
i N r
Npp
i
p
est la probabilité qu’une simulation quelconque aboutisse à un résultat satisfaisant (infé-
rieur à la valeur critique), et
r
est le rang des pires cas obtenus durant toutes les simulations.
L’estimation du quantile T95,95 est donnée par la valeur pire cas obtenue au cours de N simu-
lations (r = 1) avec N donné par l’expression :
1,
N
soit
1,
N
ou
1Ln
NLn
0,05 / 0,95 58.4039748n LnNL
. Soit
59.N
Ce même quantile T95,95 peut être estimé par la pire des valeurs obtenue à l’exclusion du pire
cas (r = 2) avec N donné par l’expression :
1 1 ,
NN
N
soit
93,N
ou par la pire des valeurs obtenue à l’exclusion des 2 valeurs pires cas (r = 3) soit
124.N
II. Analyse mathématique de la formule
Nous nous intéressons ici à l'estimation du quantile T95,95 donnée par la valeur pire cas ob-
tenue au cours de N simulations (
1r
), où
N
est donné par l’expression
1.
N
p
Voyons
d'où vient cette formule : avant d'en critiquer l'usage, il faut bien comprendre le contenu.
La "Méthode de Wilks" consiste en un énoncé probabiliste extrêmement simple :

3
BB Wilks 2016/01
Soit
X
une variable aléatoire à valeurs réelles. Divisons l'ensemble des valeurs prises par
X
(peu importe en quoi elles consistent) en
n
sous-ensembles de même probabilité (en anglais
"bins", souvent traduit par "boîtes"). Evidemment, la probabilité de chaque boîte est
1
pn
.
Désignons par
1,..., n
BB
ces boîtes. Choisissons l'une d'entre elles, par exemple la dernière,
.
n
B
Supposons que nous fassions
N
tirages indépendants de la variable
X
(peu importe quelle est
la loi de cette variable). Alors la probabilité de ne jamais tomber dans
n
B
au cours de ces
N
tirages est :
1N
qp
Ce résultat est évident : la probabilité de ne pas tomber dans
n
B
lors d'un tirage est
1p
et
donc la probabilité de ne jamais y tomber en
N
tirages est
1N
p
, puisque les tirages sont
indépendants.
Comme
10
N
p
lorsque
N
, nous sommes de plus en plus sûrs de toucher toutes les
boîtes, lorsque le nombre de tests augmente. Fixons-nous un seuil
,
traditionnellement 95% ;
nous constatons que notre probabilité de toucher la dernière boîte en
N
runs dépasse ce seuil
dès que :
11
N
p
On retrouve la notation de l'article cité au paragraphe précédent en posant
1p
. Avec les
valeurs numériques prises ici, à savoir
1
20
p
, on a
0.95
, et avec
0.95,
on trouve ef-
fectivement
59.N
III. Application de la méthode à l'analyse de sûreté
Celle-ci est généralement faite sous la forme suivante.
On dispose d'un code de calcul, supposé représenter un phénomène complexe. Nous prendrons
l'exemple du code de thermohydraulique "CATHARE" (Code Avancé de THermohydraulique
pour les Accidents des Reacteurs à Eau, http://www-cathare.cea.fr, développé par Areva, le
CEA, EDF et l'IRSN). Ce code décrit le comportement d'un réacteur en cas de grosse brèche
dans le circuit réfrigérant primaire ; il retourne une température en fonction du temps et dé-
pend d'un nombre très élevé de paramètres (40 ou davantage, selon les versions). C'est un code
extrêmement complexe, qui a requis des dizaines d'années de développement. Le code est ac-
cepté par les Autorités de Sûreté, comme élément de validation.

4
BB Wilks 2016/01
Dans le livre Zeydina-Beauzamy "Probabilistic Information Transfer" [PIT], nous prenons
l'exemple de ce code pour montrer comment "propager" l'information, de manière probabiliste,
à partir de situations où les runs ont été faits à des situations où aucune information n'est
connue.
Une autre situation pourrait être celle où l'on fait une vraie expérience physique, dépendant
d'un grand nombre de paramètres. Pour des raisons de temps, de coût, de sécurité, on ne peut
pas répéter l'expérience aussi souvent qu'on le voudrait.
La question fondamentale, pour les analyses de sûreté, est donc celle-ci : on dispose d'un petit
nombre de runs (du code, de l'expérience), mettons 1 000 pour fixer les idées, et on voudrait en
déduire une réponse à une question liée à la sûreté. Par exemple, pour CATHARE, un seuil est
fixé arbitrairement à 1 200°C ; admettons que nos 1 000 runs aient tous donné des tempéra-
tures inférieures, voire bien inférieures, cela prouve quoi ? Que pouvons-nous remettre aux
Autorités de Sûreté ?
La méthode de Wilks est utilisée, pour répondre à cette question, de la manière suivante :
Nous avons nos 40 paramètres. Sur chacun d'entre eux, nous choisissons arbitrairement une
loi de probabilité. Par exemple, sur le premier, nous choisirons une loi uniforme sur tel inter-
valle ; pour le second nous choisirons une loi de Gauss de moyenne tant et de variance tant, et
ainsi de suite jusqu'au 40ème.
Par exemple, pour le paramètre X16 "pression accu", on retient une loi uniforme entre
4137m
kbars et
4 385M
kbars. Ceci n'a rien de choquant : cela signifie que, les experts
ne connaissant pas la valeur exacte que peut prendre le paramètre X16, lui attribuent n'im-
porte quelle valeur entre ces bornes, avec égale probabilité. Cela reflète l'ignorance du phéno-
mène précis.
Ces lois sont établies "à dire d'expert", c'est-à-dire que les experts considèrent que, en cas d'ac-
cident, le premier paramètre sera effectivement compris entre
a
et
,b
que le second sera plu-
tôt concentré autour d'une certaine valeur, etc. Ces affirmations sont assurément discutables,
mais elles ne sont pas absurdes et elles peuvent servir de base au raisonnement. Notre cri-
tique ne porte pas sur ce point.
Après quoi, on procède à des tirages aléatoires de chaque paramètre selon sa loi propre ; si
pour le premier, on a choisi une loi uniforme, on fait un tirage selon une loi uniforme. Si pour
le second on a choisi une loi de Gauss, on fait un tirage selon une loi de Gauss, et ainsi de suite
pour les 40 paramètres. On répète l'ensemble de la procédure par exemple 1 000 fois (cela fait
donc au total 40 000 tirages). On dispose ainsi de 1 000 "runs", chacun correspondant à une
situation de fonctionnement du code (une situation de fonctionnement requiert 40 para-
mètres). Pour chaque run, le code fonctionne et retourne une température.
Les experts prétendent alors que, puisque on a fait plus de 59 runs choisis aléatoirement, la
méthode de Wilks nous dit que nous avons plus de 95 chances sur 100 d'avoir détecté le quan-
tile 95 des températures les plus élevées. Autrement dit, que nous sommes quasiment certains
de la représentativité de nos essais : nos runs vont révéler la température la plus élevée.

5
BB Wilks 2016/01
Cette affirmation est entièrement fausse. L'erreur commise est celle-ci : il faudrait appliquer
la méthode de Wilks à la réponse du code (qui n'est pas connue), et non aux lois d'entrée, qui
sont fixées arbitrairement sur chaque paramètre.
IV. Où l'erreur se situe-t-elle ?
Nous allons bien expliquer ceci, sur des exemples de complexité croissante. Nous commençons
par le cas où le code ne dépend que d'un seul paramètre. Il s'agit ici de revenir aux fondamen-
taux des probabilités. Ce n'est pas le code qui est en cause, ni la méthode de Wilks, mais la
manière dont on l'applique, par ignorance des règles fondamentales des probabilités.
A. Cas d'un seul paramètre
Imaginons d'abord pour simplifier que le code dépende du seul paramètre X16 ; tous les autres
sont oubliés, ou fixés à une valeur particulière.
On renormalise le paramètre X16 pour qu'il varie entre 0 et 1. Ceci est toujours possible, sans
perte de généralité. On aura la température 1 000 pour
0X
et la température 1 500°C pour
1.X
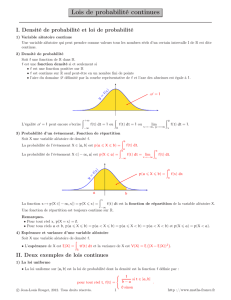
Considérons d'abord un cas très simple :
– Cas 1 : la réponse du code est linéaire
Cela signifie que la température est fonction linéaire du paramètre X16, et qu'on a une équa-
tion de la forme :
500 1000CT x
Voyons en ce cas quelle est la loi de probabilité sur
CT
déduite de la loi uniforme sur
.x
Pour tout
,
1000 1500
, on a :
500 1000
1000
500
1000
500
P CT P x
Px
puisque la loi sur
x
est uniforme. Par dérivation, on obtient la densité de probabilité de CT :
1
500
CT
f
si
1000 1500
, 0 ailleurs : nous sommes donc en présence d'une loi uni-
forme. Nous constatons que si la réponse du code est linéaire, la loi uniforme sur le paramètre
 6
7
8
9
6
7
8
9
1
/
9
100%