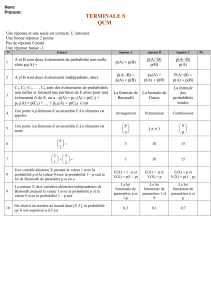
Mais à quoi peut servir la distribution binomiale

Mais à quoi peut servir la distribution binomiale ?
Daniel Justens
Dans les applications, la distribution binomiale est très souvent approchée par la distribution
normale (théorème de Moivre) ou par celle de Poisson (théorème de Poisson). Alors quelle est son
utilité ? Sert-elle exclusivement à mortifier des générations de potaches en les plaçant devant des
produits de factorielles et d'exponentielles dont le résultat a tout de l'indétermination zéro fois
l'infini ? L'utilisation de cette distribution demande une bonne compréhension des raisonnements
sous-tendant la résolution des cas dans lesquels elle est appliquée, même si numériquement, les
approximations normales et Poisson sont souvent préférables. C'est ce qui fait qu'elle est
indispensable. Elle peut aussi être utilisée directement pour la valorisation de produits financiers
sophistiqués dont elle fournit à son tour, par un juste retour des choses, une bonne approximation.
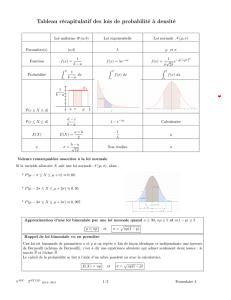
Construction de la distribution binomiale
Les distribution de probabilité sont des structures de probabilité dépendant d'un ou de plusieurs
paramètres, construites a priori et adaptables à toute une gamme de situations. Le contexte qui
nous occupe pour la distribution binomiale est celui de la la répétition de n d'expériences aléatoires
identiques à deux issues possibles, réalisées de manière indépendante, que l'on note (arbitrairement)
réussite (R) ou échec (E). Le contexte est qualitatif et non quantitatif. Le passage au quantitatif se
fait en comptant le nombre de « réussites », ce qui est un bon exemple de variable aléatoire :
association d'une valeur numérique à chaque événement élémentaire de
Ω
. À titre d'exemple, nous
regarderons l'évolution du cours d'une action en bourse qui peut tous les mois soit augmenter (R),
soit diminuer (E) de valeur. L'augmentation se fait avec probabilité p, la décroissance se faisant
alors avec la probabilité complémentaire (1–p).
Cet exemple montre comment passer de la probabilisation d'événements à celle de variables
aléatoires. Dans le cas où l'on effectue une seule expérience, l'ensemble fondamental est :
Ω
= { R,
E }. Dans un souci de simplification, on choisit de faire coïncider l'indice des probabilités et des
valeurs de la variable avec le nombre de réussites :
X(E) = 0 = x0 ; P[x0 ] = 1 - p = p0
X(R) = 1 = x1 ; P[x1 ] = p = p1
Dans le cas où l'on procède à deux expériences, l'ensemble fondamental devient
Ω
= {RR, RE, ER,
EE}. Le passage à la variable aléatoire montre que deux événements élémentaires distincts (RE et
ER) donnent la même valeur numérique (1). Les deux expériences sont supposées indépendantes.
Ce qui signifie que pour toute paire de résultats successifs, la probabilité de réalisation simultanée
(intersection), est égale au produit des probabilités : P[RE]= P[ER] = p(1 – p). Les événements RE
et ER étant disjoints, la probabilité à leur union est égale à la somme des probabilités : P[{RE, ER}]
= 2p(1 – p). En passant à la variable aléatoire « nombre de réussites » :
X(EE) = 0 = x0 ; P[x0]= (1-p)2 = p0
X(RE)= X(ER) = 1 = x1 ; P[x1] = 2p(1 - p) = p1
X(RR) = 2 = x2 ; P[x2] = p2 = p2
Le cardinal de Ω augmente exponentiellement avec n :
# Ω
= 2n. Avant de généraliser, calculons
moyenne et variance dans le cas de deux expériences :
E[X] = 2 ( p2 ) + 1 . (2 p(1-p)) + 0 . (1-p)2 = 2 p2 + 2 p - 2 p2 = 2p
V[X] = 22 ( p2 ) + 12 . (2 p(1-p)) + 02 . (1-p)2 - (2p)2 = 4 p2 + 2 p(1-p) - 4 p2 = 2p(1-p)

Généralisation
On note B(n, p) la distribution binomiale qui correspond à la réalisation de n expériences identiques
et indépendantes, de probabilité de réussite p. Calculons la probabilité d'observer très exactement k
réussites parmi les n expériences réalisées. Cette probabilité doit être associée à un sous-ensemble
Ak de
Ω
dont le cardinal doit être calculé. Ce sous-ensemble est constitué de toutes les suites
différentes comprenant exactement k fois la modalité « R » et (n-k) fois « E ». Son cardinal est donc
une combinaison avec répétition, soit :
(
n
k
)
=Cn
k=
n
!
k !(nk)!
qui utilise la notion de « factorielle » notée « ! » avec n ! = n.(n-1).(n-2). ... . 3 . 2 . 1. Attention au
danger de l'utilisation de la factorielle : elle conduit très vite à des valeurs extrêmement grandes
difficilement manipulables même pour un ordinateur performant. On effectue souvent des sondages
« pour » ou « contre » quelque chose auprès de plusieurs milliers de personnes. Le calcul de
(2000 !) pose problème. Continuons notre calcul : la probabilité associée à l'une des suites
comprenant exactement k « R » et (n-k) « E » est égale au produit des probabilités associées à
chaque résultat, étant donné l'hypothèse d'indépendance : pk (1-p)(n-k). Chacune des réalisation des
successions R et E des éléments de Ak a même probabilité (les expériences sont identiques) et
constitue relativement aux autres des événements disjoints. La probabilité associée à Ak est donc la
somme de ces probabilités, ce qui nous donne donc :
P[Ak]= pk=
n
!
k !(nk)!pk(1p)nk
On se rend compte ici aussi de l'extrême difficulté de calcul de produits de ce type lorsque le
nombre d'expériences devient très grand comme c'est la cas lors d'un sondage effectué entre deux
tours de présidentielle auprès de 2000 personnes. Chaque individu sondé peut choisir de voter pour
un candidat D (de droite) ou un candidat G (de gauche). Nous laissons au lecteur le soin de définir
ce qu'il appelle réussite ou échec. Dans une situation équilibrée, les deux valeurs p et (1-p) sont
proches de 0,5. Le produit des deux exponentielles donne donc environ (0,5)2000 soit en première
approximation à 10-20 près : 0. On comprend dès lors la nécessité des théorèmes d'approximation.
Les formules de calcul de moyennes et de variance se généralisent très facilement. En effet, la
moyenne d'une somme étant égale à la somme des moyennes, nous donne : E[X] = np. La variance
d'une somme de variables indépendantes vaut également la somme des variances des variables de la
somme, ce qui conduit à : V[X] = np(1-p)
Une application en finance stochastique
Par un curieux renversement de situation, cette distribution binomiale peut également s'avérer un
moyen aisé d'approcher simplement les valeurs de marché de produits financiers extrêmement
sophistiqués. Une option « call » européenne est le droit d'acheter une action déterminée à un prix
déterminé à un moment déterminé. Comment valoriser un droit ? C'est à cette question que les
mathématiciens Fisher Black et Myron Scholes ont répondu dans un article publié en 1973, qui leur
a valu le prix Nobel d'économie en 1997. La complexité des calculs et des raisonnements mis en
œuvre a fait qu'il a fallu attendre 1979 et une présentation simplifiée du système utilisant les
distributions binomiales, pour convaincre les marchés du bien fondé de la démarche des deux
chercheurs américains. Voyons tout cela numériquement. Soit une action cotée 50 euro aujourd'hui.
Je désire l'acheter dans 3 mois à un certain prix K : le prix d'exercice. Lorsque K<50, on est
d'emblée en situation de bénéfice et l'on dit que l'on est « in the money ». Lorsque K = 50, on est en
situation d'équilibre ou « at the money ». Pour K>50, on est en situation spéculative où l'on attend

une forte et rapide augmentation de l'action. On est « out of the money ». Que va-t-il se passer
durant les trois mois qui vont s'écouler ? On va supposer que tous les mois, l'action peut se
comporter de deux façons : croître ou décroître. Comme rien ne permet d'anticiper une hausse ou
une baisse, on va supposer que les deux éventualités sont équiprobables : p = (1- p) = 0,5. En
univers aléatoire, les actifs sont caractérisés par ce que l'on appelle la volatilité σ, c'est-à-dire
l'écart-type annuel de variations relativement à la tendance. On montre qu'en univers aléatoire,
l'écart-type des variations observées sur une période t est égale à la racine carrée du temps que
multiplie cette volatilité : σ
√
t
. On montre aussi que les produits financiers sont de type
multiplicatif. Les hausses sur un intervalle t seront donc caractérisées par une multiplication par
e
σ
√
t, les baisses par multiplication par l'inverse de manière à produire un arbre recombinant qui
va permettre l'utilisation de la distribution binomiale. Pour σ = 0,20, ce qui n'est pas rare pour les
actions constituant le CAC 40, on trouve un écart-type mensuel valant
0,2
∗
√
1
/
12
=
0,0577...
.
Les facteurs de multiplication mensuels sont égaux à
e
0,0577..=
1,0594...
. On décrit l'évolution de
l'action pendant trois mois selon un arbre binomial :
Notre modèle simplifié nous propose 4 valeurs à termes pour l'actif qui nous intéresse. Introduisons
une nouvelle variable aléatoire Y décrivant le bénéfice à terme associé à chacune des situations
possibles pour la possession d'une option « call ». Cette variable aléatoire dépend des valeurs de K.
Si je peux acheter à terme l'actif pour K = 50, seules les deux premières situations génèrent des
bénéfices. Lorsque l'actif a une valeur inférieure à son prix d'exercice, il est clair que l'on n'exerce
pas l'option qui prend une valeur nulle. En arrondissant au centime près, notre variable aléatoire
prend donc les valeurs 9,46 euro (59,46 euro, valeur à terme, moins 50 euro, valeur à laquelle on
peut acheter l'action) avec la probabilité 0,125 et 2,97 euro avec probabilité 0,375. Les probabilités
sont calculées comme exposé plus haut. Les autres cas de figure (probabilité 0,5) génèrent un
bénéfice identiquement nul. L'espérance mathématique de cette variable aléatoire Y vaut donc :
E[Y] = 9,46 * 0,125 +
2,97 * 0,375 = 2,30
euro. La très
sophistiquée formule de
Black et Scholes donne
2,18 euro pour la même
option. L'ordre de
grandeur n'est donc pas
très différent. En faisant
varier K dans la
fourchette [47, 53], au
voisinage de la valeur
actuelle de l'action sous-
jacente à l'option, on
arrive au graphique ci-
contre dans lequel les
valeurs de la formule
B&S suivent la courbe
46 47 48 49 50 51 52 53 54
0
0,5
1
1,5
2
2,5
3
3,5
4
4,5
1er mois 2e mois 3e mois Probabilités
59,455497182 0,125
56,120045122
52,971711848 52,971711848 0,375
50 50
47,19500112 47,19500112 0,375
44,547362614
42,04825657 0,125

rouge et l'approximation binomiale la courbe bleue. Pas trop mal pour une distribution élémentaire !
Ce d'autant plus que l'estimation de la volatilité d'une action est très arbitraire, les résultats passés
n'étant en aucune manière une garantie des résultats futurs. Une phrase fondamentale que les
banquiers émetteurs de produits à risque mentionnent toujours en très petits caractères dans leurs
prospectus publicitaires...
1
/
4
100%