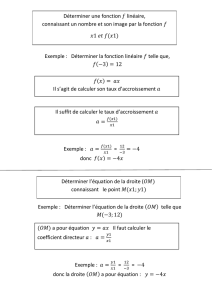
Volume n° MATHS STMG

Volume n°
MATHS STMG
Géraud Sarrebourse de la Guillonnière
12 novembre 2014

Table des matières
1 Variable statistique 3
1.1 Sériestatistiqueàdeuxvariables ........................................... 3
1.2 Nuagedepoints..................................................... 4
1.3 Pointmoyen....................................................... 4
1.4 Nuagedepointsavecuntableur ........................................... 5
2 Ajustement affine 6
2.1 Méthodegraphiqueaujugé .............................................. 7
2.2 MéthodedeMayer ................................................... 8
2.3 Méthodedesmoindrescarrés ............................................. 9
2.4 Estimationetprévision ................................................ 12
3 Conditionnement 13
3.1 Probabilité ....................................................... 13
3.1.1 Expériencealéatoire .............................................. 13
3.1.2 Évènement ................................................... 13
3.1.3 Opérationssurlesévènements ........................................ 15
3.1.4 Probabilités................................................... 16
3.2 Probabilitésconditionnelles .............................................. 17
3.2.1 Définition.................................................... 18
3.2.2 Utilisationd’unarbre ............................................. 18
3.2.3 Évènementsindépendants........................................... 19
3.3 Probabilitéstotales................................................... 19
4 Dérivation 21
4.1 Dérivées d’une fonction polynôme de degré 2ou 3.................................. 21
4.1.1 Polynôme de degré 2ou 3........................................... 21
4.1.2 Tableau des fonctions dérivées de monômes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.1.3 Dérivées de fonctions de la forme u+v................................... 22
4.1.4 Dérivées des fonctions de la forme ku .................................... 23
4.1.5 Dérivées de fonctions de la forme uv ..................................... 23
4.2 Dérivéesd’unefonctionrationnelle .......................................... 23
4.2.1 Définition d’une fonction rationnelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4.2.2 Dérivées de fonctions de la forme u
v...................................... 24
4.3 Application ....................................................... 24
4.3.1 Equation de la tangente à une courbe en un point . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4.3.2 Sens de variation d’une fonction et extremum . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
5 Échantillonnage-Estimation 27
5.1 Populationetéchantillon ............................................... 27
5.2 Echantillonnage : intervalle de fluctuation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
5.3 Prisededécision .................................................... 29
5.4 Estimation:intervalledeconfiance.......................................... 30
5.5 Tailleminimaled’unéchantillon............................................ 31
6 Indice-Taux moyen 32
6.1 Pourcentage....................................................... 32
6.2 Coefficientmultiplicateur ............................................... 33
6.3 Tauxd’évolution .................................................... 33
6.3.1 Définition.................................................... 33
6.3.2 Relation entre coefficient multiplicateur et taux d’évolution . . . . . . . . . . . . . . . . . . . . . . . . 34
1

6.4 Indice simple de base 100 ............................................... 34
6.4.1 Définition.................................................... 34
6.4.2 Relation entre indice et coefficient multiplicateur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
6.4.3 Relation entre indice et taux d’évolution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
7 Racines 37
7.1 Racinen-ièmed’unnombrepositif .......................................... 37
7.2 Racinen-ièmeaveclacalculatrice........................................... 38
7.3 Racinen-ièmeavecuntableur............................................. 39
7.4 Propriétés........................................................ 39
8 Taux d’évolution globale 40
8.1 Coefficientmultiplicteurglobal ............................................ 40
8.2 Tauxd’évolutionglobal ................................................ 41
8.3 Tauxd’évolutionmoyen ................................................ 43
9 Loi normale 45
9.1 Loinormale....................................................... 45
9.2 Utilisationd’unetable................................................. 47
9.3 Aveclacalculatrice................................................... 48
9.4 Intervalledefluctuation ................................................ 49
10 Suites numériques 50
10.1Suitesnumériques ................................................... 51
10.1.1 Définition.................................................... 51
10.1.2 Suiteexplicite.................................................. 51
10.1.3 Suiterécurrente................................................. 51
10.2Suiteavecuntableur.................................................. 52
10.3Suiteremarquable ................................................... 53
10.4Suitearithmétique ................................................... 53
10.4.1 Suitegéométrique ............................................... 54
10.5 Somme des termes consécutifs d’une suite . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
10.5.1 Nombredetermesd’unesuite......................................... 55
10.5.2 Sommedestermesd’unesuite ........................................ 55
10.5.3 Somme des termes d’une suite avec un tableur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
10.6 Comparaison des suites arithmétiques et géométriques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
10.6.1 Intérêtssimples................................................. 56
10.6.2 Intérêtscomposés................................................ 56
10.6.3 Comparaison de deux suites géométriques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
10.6.4 Comparaison suites arithmétiques et géométriques . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
Mail: [email protected] Tous droits réservés Page no2 sur 60

Chapitre
1
Variable statistique
Supposons que nous ayons à relever le prix de l’essence E10 (super+10% d’éthanol) des stations services de France.
La population est l’ensemble des stations services du pays. Dans notre cas nous pourrions avoir un échantillon de 20 stations.
Le caractère ou variable statistique étudié est alors le prix de l’E10 en euros. Le résultat de la mesure (le prix) est un nombre
réel. Dit autrement le caractère étudié est quantitatif (c’est-à-dire mesure une quantité). Si nous avions relevé la couleur de
la pompe à essence nous aurions parlé de caractère (la couleur) qualitatif.
Le caractère étudié est noté xou Xet les valeurs prises par ce caractère lors des mesures sont notées xi. lorsque l’on écrit
bout à bout dans un tableau les valeurs xion obtient une série (suite de nombres xi) statistique à une variable.
Nous allons dans ce chapitre travailler avec deux séries statistiques résumées dans un tableau, que l’on représentera gra-
phiquement par un nuage de points. La fiche suivante (Ajustement affine) nous permettre de mettre en valeur un lien, une
corrélation entre ces deux variables statistiques.
1.1 Série statistique à deux variables
On appelle série statistique à deux variables ou série statistique double une série statistique où 2caractères
quantitatifs (notés xet y) sont étudiés en même temps (simultanément).
Si une population contient nindividus, on note xiet yipour 1≤i≤nles valeurs prises par les 2caractères
quantitatifs xet y, ce que l’on résume dans un tableau :
Définition 1.
Remarque : Si l’un des caractères quantitatifs étudiés est une mesure du temps (secondes, heure, année...) on dira que la
série statistique à 2variables est une série chronologique.
Exemple 1.1.1 Soit le tableau qui donne la part en %consacré au logement dans le budget d’un foyer.
Il y a un caractère statistique (noté x) qui mesure les années. Il s’agit d’un caractère quantitatif. L’autre caractère (noté y)
mesure quand à lui la part en %. A nouveau il s’agit d’un caractère quantitatif. Le tableau précédent est une série statistique
à2variables ou série statistique double. Comme xmesure du temps, ce tableau est aussi une série chronologique.
3

CHAPITRE 1. VARIABLE STATISTIQUE
1.2 Nuage de points
Un repère orthogonal (O,~
i,~
j)est un repère où les 2axes se coupent à angle droit et où l’unité de l’abscisse et
de l’ordonnée ne sont pas de même mesure.
Définition 2.
Remarque : Dans le cas où la mesure de l’unité est identique pour les deux axes on parlera de repère orthonormal ou
repère orthonormé.
On se place dans un repère orthogonal bien choisi. L’ensemble des points Mide coordonnées (xi, yi)notés
Mi(xi, yi)pour 1≤i≤nforme dans ce repère un nuage de points associé à la série statistique à 2variables.
Définition 3.
Exemple 1.2.1 Avec la série statistique :
Les points du nuage ont pour coordonnées M1(1978; 4,4) M2(1984; 5,2) M3(1992; 4,3) M4(1994; 3,2) M5(2000; 3,3) et M6(2004; 2,8)
Nous obtiendrons dans un repère orthogonal (Axe des abscisses à partir de 1978) avec l’échelle 1cm →2ans sur (Ox)
1cm →0,5% sur (Oy)le
nuage de points suivant :
BAC : Dans de nombreux cas afin de donner un nuage de points plus lisible, l’intersection de l’abscisse et de l’ordonnée n’est
pas forcement le point d’origine du repère.
1.3 Point moyen
Le point moyen d’un nuage de points est le point Gde coordonnées (¯x, ¯y)où
¯x=x1+... +xn
n(moyenne des valeurs xi) et ¯y=y1+... +yn
n(moyenne des valeurs yi)
Définition 4.
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
1
/
61
100%