1 Cours - Statistiques - c0052 Statistiques L`étude d`une distribution

1
Cours - Statistiques - c0052
Statistiques
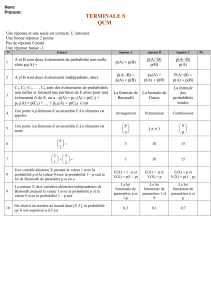
L’étude d’une distribution statistique suppose une population dont on analyse un caractère au travers d’un
échantillon prenant un nombre fini de valeurs , chacune de ces valeurs ayant un effectif donné.
Ainsi, pour étudier le nombre de voitures par famille dans la commune de Cléry en Vexin (95).
La population (ici confondue avec l’échantillon étudié) est l’ensemble des familles de la commune.
Le caractère étudié est le nombre de voitures par famille.
L’enquête menée a permis d’établir le tableau suivant :
Nbre Voitures 0 1 2 3
Effectif 12 65 45 8
Les valeurs du caractère sont ( 0 ; 1 ; 2 ; 3 ) , notées ( x1 ; x2 ; x3 ; x4 ) , nombre de voitures par familles.
Les effectifs relatifs à chaque valeur sont respectivement ( 12 ; 65 ; 45 ; 8 ) , notés ( n1 ; n2 ; n3 ; n4 ).
Fréquence de chaque valeur du caractère
Nbre voitures 0 1 2 3
Effectif 12 65 45 8
Fréquence 12/130 65/130 45/130 8/130
La fréquence d’une valeur du caractère est le pourcentage (probabilité) que représente l’effectif de cette
valeur par rapport à l’effectif total de l’échantillon étudié.
Calcul de la moyenne et de l’écart-type.
Une distribution statistique est connue par sa moyenne arithmétique (indicateur de valeur centrale ) qui donne
un point moyen représentatif de l’ensemble de l’échantillon, mais également par son écart-type (indicateur de
dispersion) qui exprime l’étalement de l’échantillon autour de sa moyenne.
Un élève qui a pour note (6 ; 12 ; 15) a une moyenne de 11 , tout comme un élève noté (10 ; 11 ; 12) , mais la
dispersion des notes du second élève est moindre que celle du premier.
Les deux informations (moyenne ; dispersion) sont nécessaires à la connaissance d’une distribution
statistique.

2
Soit un caractère X dont on veut étudier une répartition statistique :
Soient (x1 , x2 , x3 , ...... , xk ) les k valeurs possibles du caractère étudié.
Soient (n1 , n2 , n3 , ...... , nk) les k effectifs correspondant à chacune des valeurs du caractère.
La moyenne arithmétique pondérée du caractère X est égale à la somme des produits des diverses valeurs du
caractère par leur effectif propre S = n1 x1 + n2 x2 + n3 x3 + ...... + nk xk , cette somme étant ensuite divisée par
l’effectif total N = n1 + n2 + n3 + ...... + nk .
X=n1x1+n2x2+..... +nkxk
n1+n2+..... +n
k
Un savant calcul mathématique estime l’écart-type σ (sigma) , qui mesure la dispersion de l’échantillon autour
de sa moyenne , par la formule :
σ=V ou V=X2–(X)2 est appelée variance , formule dans laquelle X2=n1x1
2
+n2x2
2
+..... +nkxk
2
n1+n2+..... +nk
,
moyenne des carrés des valeurs , et où (X)
2
est le carré de la moyenne des valeurs vues précédemment.
On dit souvent σσ =
X
2–(
X
)2 = racine de la moyenne des carrés moins le carré de la moyenne)
xi ni ni xi ni xi 2
0 12 0 0
1 65 65 65
2 45 90 180
3 8 24 72
130 179 317
L’effectif total est N = ni=
Σ
i=1
4
130, d’où nixi=179
Σ
i=1
4
, d’où:
X=1
N(nixi)=179
130 =
Σ
i=1
4
1,38 voitures par famille
nixi
2=317
Σ
i=1
4
La moyenne des carrés est X2=1
N(nixi
2)=317
130 =
Σ
i=1
4
2,44
La variance : V = X2–(X)2=2,44 –(1,38 )2=0,536
L’écart-type : σ=V=0,536 =0,73
voiture
.

3
Comparaison de la dispersion de deux caractères statistiques dissemblables – Coefficient de Variation
Pour comparer la dispersion de deux caractères identiques dans deux populations différentes, il suffit de
comparer les écarts-type de ces deux populations.
Ainsi, dans l'exemple précédent : σ1 = 0,73 voiture à Cléry en Vexin , et σ2 = 0,81 voiture à Pontoise ,
permettent de conclure en termes de dispersion.
Par contre : Comparer les dispersions entre "le nombre de voitures par foyer" et "le nombre d'arbres par jardin"
ne peut se limiter à la consultation des écarts-type : σ1 = 0,73 voiture et σ2 = 1,23 arbres.
Pour comparer la dispersion de deux caractères différents, on utilise le Coefficient de Variation : CV = σ
X .
Le Coefficient de Variation est un nombre sans unité.
Nombre de voitures par foyer : X1 = 1,38 voitures , σ1 = 0,73 voiture ⇒ CV1 = σ1
X1
= 0,73
1,38 ≈ 0,529 .
Nombre d'arbres par jardin : X2 = 2,41 arbres , σ2 = 1,23 voiture ⇒ CV2 = σ2
X2
= 1,23
2,41 ≈ 0,510 .
Contrairement à ce que l'on pouvait penser, ce second caractère est le moins dispersé autour de sa moyenne.
Autres indicateurs de Valeur Centrale :
- Le Mode Mo : Valeur du caractère de plus forte fréquence (valeur à la mode)
Lorsque la population est rangée en classes, on parlera de Classe Modale .
- La Médiane Me : Valeur du caractère qui sépare la population en deux sous-populations de même effectif.
50% de la population telle que xi < Me et 50% de la population telle que xi > Me .
Pour déterminer graphiquement la Médiane , on trace le polygone des fréquences cumulées , La valeur de Me
correspondant à la valeur d'ordonnée de 0,50 = 50%.

4
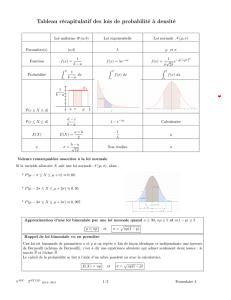
Cours – Evènements Incompatibles – Indépendants - Tirages de Bernouilli – Loi Binomiale - c0075
I – Formule fondamentale des Probabilités
Soient A et B deux évènements éventuellement réalisables dans une expérience E ,
On note A ∩ B l'événement ' réaliser simultanément A et B ',
On note A ∪ B l'événement ' réaliser au moins l'un des deux évènements A ou B ' ( ou non exclusif),
On sait que : p(A ∪∪ B) + p(A ∩∩ B) = p(A) + p(B) .
II – Cas Particulier : Evènements Incompatibles entre eux dans une expérience
A et B sont dits incompatibles entre eux dans une expérience E , s'ils ne peuvent se réaliser simultanément
dans cette expérience : A ∩ B = ∅ ⇔ p(A ∩ B) = 0
Conclusion : (à partir de la formule générale)
Si deux évènements sont incompatibles dans l'expérience E , alors p(A ∪∪ B) + p(A ∩∩ B) = p(A) + p(B) .
Conséquence : Théorème des Probabilités totales
Si l'événement A se décompose totalement en sous-évènements { A1 , A2 , … , An } incompatibles entre eux,
formant ainsi une partition de A , alors : p(A) = p(A1) + p(A2) + … + p(An) .
Conséquence : Probabilité de l'événement contraire
L'événement A et son contraire A , forment une partition de l'ensemble des éventualités de l'expérience E ,
noté Ω , lequel vérifie p(Ω) = 1 . (100% de chances de réaliser l'un des évènements de l'expérience E , en
tentant l'expérience E ….. ce qui paraît évident ! )
p(Ω) = p( A ∪ A) = p( A ) + p(A) = 1 , sachant A et A incompatibles ente eux,
d'où : p(A) = 1 – p ( A ) .
Si la probabilité de réussir un examen est de 70% , p = 0,7 , celle de le rater est de 30% ( 1 – p = 0,3 ).
III –Evènements se réalisant dans des expériences successives
Soit E une suite d'expériences (E1 , E2 , E3) .
Soit A l'évènement constitué de la suite d'évènements (A1 , A2 , A3) , chaque Ai se réalisant dans la sous-
expérience correspondante Ei ( 1 ≤ i ≤ 3 ) .
p(A) = p(A1 , A2 , A3) = p(A1) ´ p(A2/A1) ´ p(A3/A1,A2) .

5
Dans cette formule :
p(A1) est la probabilité de réaliser A1 dans l'expérience E1 ,
p(A2/A1) est la probabilité de réaliser A2 dans l'expérience E2 , sachant A1 déjà réalisé, donc en
tenant compte de ses conséquences,
p(A3/A1,A2) est la probabilité de réaliser A3 dans l'expérience E3 , sachant A1 et A2 déjà réalisés.
Exemple 2 :
On tire successivement trois cartes d'un jeu de 32 , sans remise entre chaque tirage :
Calculer la probabilité d'obtenir exactement 3 Dames ?
P(D1 , D2 , D3) = p(D1) × p(D2/D1) × p(D3/D1,D2) = 4
32 × 3
31 × 2
30 .
Remarque : Si l'on demande la probabilité d'obtenir au moins trois Dames :
Toujours décomposer en cas incompatibles :
exactement 1 Dame + exactement 2 Dames + exactement 3 Dames ,
ou éventuellement, utiliser l'événement contraire :
1 – exactement 4 Dames .
IV – Tirages de Bernouilli
On appelle Tirage de Bernouilli , la situation suivante :
- n expériences consécutives et identiques, indépendantes entre elles,
- un événement A de probabilité p dans chacune de ces n expériences,
- la variable aléatoire X qui mesure le nombre de réalisations de l'événement A dans la suite
des n expériences :
La probabilité pk de réaliser exactement k fois l'événement A dans les n expériences ( 0 ≤≤ k ≤≤ n ) , est :
pk = p(X = k) = Ck
n pk.(1 – pn – k ) .
Preuve :
Imposons aux k réalisations de A , de se produire lors des k premières expériences ( il faut donc imposer à
son événement contraire A de se produire lors des n – k dernières expériences).
p = p(A , A , .. k fois .., A,A, A, .. n – k fois .. , A) = p.p. .. k fois .. p.(1 – p)(1 – p) .. n – k fois .. (1 – p)
p = pk(1 – p)n – k .
Comme nous n'imposons pas de positionnement précis aux k réalisations de A , toutes les permutations de
l'ordre précédent sont recevables, soit n!
k!(n – k)! = Ck
n permutations, compte tenu des doublons .
On retrouve bien : pk = p(X = k) = Ck
n pk(1 – pn – k ) .
 6
6
1
/
6
100%