introduction a l` apprentissage automatique

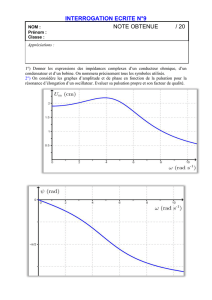
Apprentissage automatique et
traitement du langage
(chapitre 18 AIMA, pp.531-544
Tom Mitchell Machine Learning)

Un des principaux défis en TAL consiste à fournir aux ordinateurs
les connaissances linguistiques nécessaires pour effectuer avec
succés des tâches langagières.
Solution au problème de l’acquisition des connaissances
langagières
A la place d’un expert qui fournit à l’ordinateur des informations sur
le langage, le programme apprend lui-même à partir des données
textuelles.
Rappel

Avantages des méthodes empiriques
Acquisition
Couverture
Robustesse
Extensibilité
Evaluation
Rappel

Rappresentation: probabiliste, symbolique, reseaux de neurones
Entreinement: supervisé ou non-supervisé
Tâches:
reconnaissance de la parole;
analyse syntaxique (parsing)/desambiguisation;
acquisition lexicale: sous-catégorisation, structure argumentale,
attachement du PP;
desambiguisation du sense des mots;
traduction automatique.
Différentes méthodes empiriques

Définition
On dit qu'un programme informatique apprend à partir d’une
expérience empirique E par rapport à une tâche T et par rapport à
une mésure de performance P, si sa performance P à la tâche T
s’améliore à la suite de E.
Exemple
Tâche T: classer des verbes anglais dans des classes prédéfinies
Mésure de performance P : % de verbes classés correctement par
rapport à une classification définie par des experts (gold standard)
Experiénce d’entreinement E: base de données de couples de
verbes (et leurs proprietés) et classe correcte
Apprentissage: définition
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
1
/
30
100%