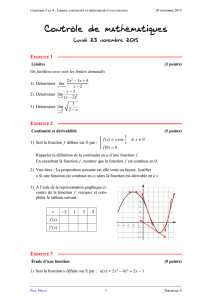
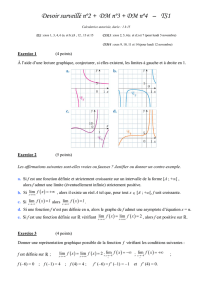
Le 15/03/2020
Résumé de cours d’analyse et probabilités MP
A.CHABCHI
Contents
I Espaces vectoriels normés 3
ANormes ................................... 3
BNorme équivalente ............................ 3
CMajoration dans un evn ......................... 4
D Voisinage - Ouvert - Fermé ........................ 4
EAdhérence et intérieur ......................... 5
FDensité ................................... 5
GValeur d’adhérence ........................... 5
HCompact ................................... 5
IContinuité des applications ....................... 6
JConvergence des suites .......................... 6
KConnexité par arcs ............................ 6
II Les séries de nombres ou de vecteurs 7
ALes connaissanes de base : ....................... 7
BLes critères de convergence : ...................... 8
CSommation de relation de comparaison ............... 9
DSommabilité ................................ 10
III Suites et séries de fonctions 11
ASuites de fonctions ............................ 11
1Modes de convergence : ...................... 11
2Propriètés de la limite : ...................... 12
BSéries de fonctions ............................ 12
1Modes de convergence : ...................... 12
2Propriètés de la somme : ..................... 13
IV Séries Entières 13
ARayon de convergence : ......................... 13
BModes de convergences ......................... 14
CPropriètés de la somme : ........................ 14
V Intégration : 15
AIntégrale impropre ou généralisée : ................. 15
BIntégrabilité : critères .......................... 16
CThéorème de la sommation L1:.................... 17
DEchange limite et intégrale ...................... 18
EIntégrale dépendant d’un paramètre : ................ 18
1

VI Dérivation et di¤érentiabilité : 19
ADérivation : ................................. 19
BDi¤érentiabilité .............................. 20
CDérivations des fonctions complexes : holomorphie (CNC) . . . 24
VII Equations di¤érentielle 24
ALes ABC de la MPSI ........................... 24
BEquation scalaire d’ordre 2 : ...................... 25
C Systèmes di¤érentiels linéaires . . . . . . . . . . . . . . . . . . . . . . . 25
D Equation di¤érentielle non linéaire (CNC) . . . . . . . . . . . . . . . . . 26
E Courbe paramétrée . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
VIII Probabilité 27
AEspace de probabilité ........................... 27
BProbabilité conditionnelle ........................ 29
CIndépendance ............................... 30
DVariable aléatoire ............................. 30
E Espérance : cas discret . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
FMoment - variance ............................ 32
GFonction génératrice ........................... 33
HApproximation et limite ......................... 33
IVariable à densité (CNC) ........................ 33
JConvergence ................................ 35
Abstract
Ce résumé est illustré par de nombreux exemples pour faciliter son usage. Les exem-
ples utilisent toutes les notions du programme et peuvent-être laissé à une seconde lecture
en cas de di¢ culté.
Bon courage
2

I. Espaces vectoriels normés
A. Normes
1. Norme = Toute application N:E! R+véri…ant :
(a) N(x) = 0 () x= 0
(b) N(x) = jjN(x)
(c) N(x+y)N(x) + N(y)a
2. Exemples :
(a) Dans Kn:kxk1= max
1knjxkj;et kxk1=
n
X
k=1 jxkj;où x= (x1; :::; xn):
(b) Dans E=C0([a; b];K);kfk1=Zb
ajf(t)jdt et kfk1= max
atbjf(t)j:
3. Une classe de norme très importante est celle des normes issues d’un
produit scalaire : Si h:; :iun produit scalaire sur E; alors kxk=phx; xiest une
norme. En plus de l’inégalité triangulaire, cette norme véri…e aussi l’inégalité de
Cauchy-Schwarz : jhx; yij kxkkyk, avec égalité ssi (x; y)liée.
(a) Dans Rn:kxk=v
u
u
t
n
X
k=1 jxkj2=tXX est la norme euclidienne usuelle associée
à : hx; yi=
n
X
i=1
xiyi=tXY: , Cauchy-Schwarz donne :
n
X
k=1
xkykv
u
u
t
n
X
k=1 jxkj2v
u
u
t
n
X
k=1 jykj2avec égalité ssi (x; y)liés.
et kx+yk=kxk+kykssi (x; y)positivement liés
(b) Dans Mn(R) : kMk=v
u
u
t
n
X
i=1
n
X
j=1 jmij j2=pT race (tM M); associée à hM; Ni=
T race (tM N):
(c) Dans E=C0([a; b];R);kfk2=sZb
ajf(t)j2dt;associée à hf; gi=Zb
a
f(t)g(t)dt:
Cauchy-Schwarz : Zb
a
f(t)g(t)dtsZb
ajf(t)j2dtsZb
ajg(t)j2dt avec égal-
ité ssi (f; g)liés:
(d) Dans E=L2
C(I; R);kfk2=rZIjf(t)j2dt;associée à hf; gi=ZI
f(t)g(t)dt:
Cauchy-Schwarz : ZI
f(t)g(t)dtrZIjf(t)j2dtrZIjg(t)j2dt avec égalite
ssi fet g:sont liés.
Restent valables pour K=Cen remplaçant dans h:; :i:xpar son conjugué
xdans (a),Mpar Mdans (b)et fpar fdans (c):on obtient alors :
hx; yi=
n
X
i=1
xiyi=tXY dans Cn;hM; Ni=T race tMNdans Mn(C)et
hf; gi=Zb
a
f(t)g(t)dt dans C0([a; b];C):
4. Norme de matrice ou d’endomorphisme : Lorsqu’on travaille dans une algèbre
comme Mn(K)ou L(E) : il est pratique de choisir des normes d’algèbre (sous-
multiplicatives) : kABk kAkkBkou kuvk kukkvk:Ces normes véri…ent
kApk kAkp:
B. Norme équivalente
1. N1N2() la convergence au sens de N2entraîne la convergence au sens de N1:
2. Deux normes N1et N2sont équivalentes s’il existe ; 0; N1N2N1.
3. Deux normes équivalentes dé…nissent la même topologie : même suite convergente,
même ouverts, même fermé, même ....
3

4. Equivalence des normes : En dimension …nie, toutes les normes sont équiva-
lentes : Toutes les notions topologiques sont alors indépendantes de la norme, vous
choisissez la norme la mieux adaptée.
Exemple : Montrer que la série de matrice X
k0
A2k
(2k)! est convergente. Vu l’équivalence
des normes en dimension …nie, on choisit une norme d’algèbre, donc
A2k
(2k)!
kAk2k
(2k)! ;or la série de nombre X
k0
kAk2k
(2k)! converge selon le ctritère de
D’Alembert, donc la série de matrice X
k0
A2k
(2k)! converge absolument, donc converge.
C. Majoration dans un evn
1. Inégalité triangulaire :
(a) Pour 2 éléments : kx+yk kxk+kyk:
(b) Pour un nombre …ni :
n
X
k=1
xk
n
X
k=1 kxkk
(c) Pour une série Absolument Cv :
+1
X
k=0
xk
+1
X
k=0 kxkk
2. Minoration : kx+yk kxkkyk
D. Voisinage - Ouvert - Fermé
1. V2 V (x)() 9 r > 0; B (x; r)V: Les réunions quelconque et les intersections
…nies de voisinages sont des voisinages
2. Ouvert = voisinage de tous ses point et Fermé = Complémentaire d’ouvert
3. Ffermé () 8 (un)2FN;avec lim un=l; alors l2F: Pour montrer Ffermé,
prendre une suite convergente d’éléments de Fet montrer que sa limite est dans F:
Exemples:
(a) F=(x; y)2R2= xy 0fermé car si 8n; xnyn0alors lim
nxnlim
nyn
0:
(b) L’ensemble des matrices diagonales est fermé car la limite d’une suite de ma-
trices diagonales est aussi diagonale.
(c) L’ensemble des matrices triangulaires sup est fermé car la limite d’une suite de
matrices triangulaires sup est aussi triangulaire sup.
4. Ffermé (relatif) de E() F=f1(ferme simple de E0);avec f:E!E0
continue sur E:
Exemples :
(a) F=(x; y)2R2= xy 1=f1([1;+1[), où f(x; y) = xy continue car
polynômiale et [1;+1[fermé.
(b) La sphére unité S(0;1) = fx2E = kxk= 1g=f1(f1g);où f(x) = kxk
continue et f1gfermé.
(c) Le groupe orthogonale On(R) = f1(fIng)est un fermé de Mn(R);où
f(M) = tMM continue sur Mn(R)car à composante polynômiale des coef-
…cients de M:
5. Oouvert (relatif) de E() O=f1(Ouvert simple de E0);avec f:f:E!E0
continue sur E:
Exemples :
(a) GLn(K) = fM2 Mn(K)=det (M)6= 0g= det1(K);det continue car
polynômiale et Kouvert.
(b) O=(x; y)2R2= xy > 1=f1(]1;+1[), où f(x; y) = xy continue car
polynômiale et ]1;+1[ouvert.
4

E. Adhérence et intérieur
1. x2
Asi 8r > 0; B (x; r)\A6=?et x2
Asi 9r > 0; B (x; r)A
2. F r (A) =
An
A
3. d(x; A) = 0 () x2
A
4. Théorème :
(a)
Aest l’ensemble des limites des suites convergentes d’éléments de A: C’est aussi
le plus petit fermé contenant Aet
A=Assi Afermé
(b)
Aest le plus grand ouvert de Econtenu dans Aet
A=Assi Aouvert
F. Densité
1. Aest dense dans Esi
A=E: Tout élément de Eest limite d’une suite d’élément
de Aou encore toute boule de rayon non nul contient un point de A:
2. Deux fonctions continues coincidant sur une partie dense sont partout égales.
3. Pour établir une propriété, on pourra commencer par l’établir sur une sous partie
dense.
Exemple : GLn(K)est un ouvert dense de Mn(K);et comme application par
exemple les produits MN et NM ont le même polynôme caractéristique.
G. Valeur d’adhérence
1. lest valeur d’adhérence de (xn)nssi lest la limite d’une suite extraite de (xn):
2. Une suite convergente admet une seule valeur d’adhérence qui est sa limite. Une
suite ayant au moins 2 valeurs d’adhérence est divergente.
3. Bolzano-Weierstrass : En dimension …nie, toute suite bornée admet au moins
une valeur d’adhérence. Et toute suite bornée ayant une seule valeur d’adhérence
est convergente.
H. Compact
1. Acompact si toute suite de Aadmet une valeur d’adhérence dans A:
2. Compact =)fermé-borné
3. En dimension …nie : Compact = fermé et borné.
4. Un produit cartésien …ni de compact est compact
5. L’image continue d’un compact est un compact.
6. Théorème des bornes atteintes : Toute fonction continue sur un compact
est bornée et atteint ses bornes. Pour montrer qu’une fonction est bornée ou
atteint ses bornes penser à utiliser ce résultat.
Exemples :
(a) f2C0([a; b];R);alors 9c2[a; b]; f (c) = sup
atb
f(t), car fest continue sur
le compact [a; b]:
(b) A2 Mn(K);alors 9Y2 Mn;1(K);kYk= 1 et kAY k= sup
kXk=1 kAXk;car
X7! AX est continue sur la sphère unité qui est compact.
(c) La distance à un compact (non vide) est atteinte : Si Acompact, 8x2E;
9a2A:d(x; A) = kxak
5
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
1
/
36
100%