1 Notions de base -Le cas équiprobable : dénom- brement 2

1 Notions de base -Le cas équiprobable : dénom-
brement
2 Interprétation ensembliste des événements - Ax-
iomes des probabilités
3 Probabilité conditionnelle -Probabilités totales -
Théorème de Bayse
4 Indépendance
5 Variables aléatoire
Une variable aléatoire est simplement une fonction X: ! R:
Une réalisation d’une variable aléatoire est donc X(!):la partie
"aléatoire" provient de !, qui est une réalisation de l’expérience con-
sidérée. Une variable aléatoire correspond a une mesure (numérique)
e¤ectuée lors de cette expérience.
L’événement "la variable aléatoire Xdonne comme résultat a" est
noté
fX=ag=f!2 : X(!) = ag=X1(a)
et l’événement "la variable aléatoire Xdonne comme résultat dans
A" est
fX2Ag=f!2 : X(!)2Ag=X1(A):
Ce n’est donc ni plus ni moins que la préimage de Apar l’application
X.
Exemple : Si l’expérience consiste a choisir une personne au hasard
alors son âge, sa taille, son nombre de dents sont des variables aléatoires
mais pas son sexe (car le résultat n’est pas numérique). Pour que le
sexe devienne une variable aléatoire il faudrait associer au sexe féminin
la valeur 1et au sexe masculin la valeur 0par exemple.
On associe à chaque variable aléatoire sa fonction de répartition
FX(x)qui associe à chaque valeur x2Rla probabilité de l’événement
fXxg. c’est-à-dire
1

FX(x) = P(Xx) = P(f!2 : X(!)xg):
Propriétés de la fonction de répartition :
La fonction de répartition de toute variable aléatoire est dé…nie
pour tout x2R.
Elle est croissante, continue par morceaux (càdlàg : continue à droite
et admet un limite à gauche, pour être précis) et véri…e
lim
x!1FX(x) = 0 et lim
x!+1FX(x) = 1 :
En particulier, FX(X)2[0;1] pour tout x:
La fonction de répartition caractérise totalement la loi de la variable
aléatoire Xen donnant la probabilité des événements de type fX2]1; x]g:
En e¤et, par exemple
P(X > a) = 1 P(Xa) = 1 FX(a)
P(X < a) = lim
x!a
P(Xa) = lim
x!aFX(x) = FX(a)
P(aXb) = P(Xb)P(X < a) = FX(b)FX(a)
P(X=a) = P(Xa)P(X < a) = FX(a)FX(a)
5.1 Variables aléatoires discrètes
Une variable aléatoire est dite discrète si elle ne prends qu’un nombre
…ni ou dénombrable de valeurs.
Exemple : Si l’expérience consiste a choisir une personne au hasard,
alors son nombre de dents est une variable aléatoire discrète mais pas sa
taille (mesurée avec précision absolue).
On peut alors dé…nir sa fonction de densité discrète (ou fonction
de fréquence) noté fX(x); ou plus souvent p(x), telle que
p:R! [0;1]
x7! p(x) = P(X=x)
Propriétés de la fonction de fréquence :
La fonction de fréquence de toute variable aléatoire est dé…nie pour
tout x2Rmais est non-nulle seulement pour un nombre …ni ou dénom-
brable de point.
Elle n’est ni croissante, ni continue par morceaux, ni comprise entre
0et 1.
En revanche elle véri…e
p(x) = FX(x)FX(x) = FX(x)lim
h!0+FX(xh):
2

Aussi, on a donc
p(x) = P(Xx) = X
yx
P(X=y) = X
yx
p(y):
Exemple : Jet d’un dé. = f!1; !2; !3; !4; !5; !6g,X: !
Rtelle que X(!j) = j(la face du dé).
On dé…ni l’espérance de la variable aléatoire Xpar
=E(X) = X
i
xiP(X=xi) = X
i
xip(xi)
(si Pijxijp(xi)<1).
De même, l’espérance d’une fonction d’une variable aléatoire
est dé…nie par (si Pig(xi)p(xi)<1)
E(g(X)) = X
i
g(xi)P(X=xi) = X
i
g(xi)p(xi):
C’est la moyenne pondérée des valeurs que peuvent prendre la vari-
able aléatoire pondérée par le poids de la probabilité de chaque valeur.
En termes physiques, c’est le barycentre de la densité discrète.
On dé…nit le moment d’ordre kde la variable aléatoire Xpar
EXk=X
i
xkP(X=x):
On dé…ni la variance d’une variable aléatoire Xpar
2=V ar (X) = E(XE(X))2=EX2(E(X))2=X
i
x2
ip(xi) X
i
xip(xi)!2
:
et son écart-type par la racine carrée de la variance X=pV ar(X).
C’est une mesure de l’écart moyen par rapport à l’espérance E(X).
Exemple :
Pour la variable aléatoire du résultat d’un jet de dé, l’espérance vaut
E(X) = P6
i=1 kp(k) = P6
i=1 k1
6=1
6(21) = 3:5:
Pour une variable aléatoire qui vaut 1si l’événement Ase produit et
0sinon.
l’espérance est 1:P(A)+0:P(Ac) = P(A).
3

5.2 Variables aléatoires classiques
Quelques variables aléatoires discrètes
Nom paramètres Fonction de fréquence p(k)E(X)V ar (X)
Bernoulli 0p1P(X= 1) = p
P(X= 0) = 1 pp p (1 p)
Binomiale n2N
0p1
Ck
npk(1 p)nk
pour k2 f0; :::; ngnp np (1 p)
Géométrique 0p1p(1 p)k1
pour k2N
1
p
1p
p2
Poisson > 0ek
k!
pour k2N
Binomiale négative n2N; n > 1;
0p1
Cn1
k1pn(1 p)kn
pour k2 fn; n + 1; :::g
n
pn1
p21
p
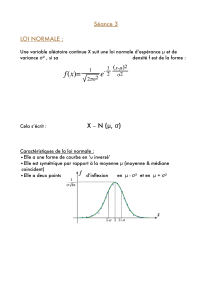
5.3 Variables aléatoires continues - Loi normale
5.3.1 Variables aléatoires continues
Une variable aléatoire qui n’est pas discrète est dite continue. Elle
prends donc ses valeurs dans un continuum.
Exemple : Si l’expérience consiste a choisir une personne au hasard,
alors son âge ou sa taille (mesurées avec précision absolue) son des vari-
ables aléatoires continues mais pas son nombre de dents (variable aléa-
toire discrète).
On dé…nit sa fonction de densité comme étant la fonction fX:
R!Rtelle que, pour tout x2R
P(Xx) = FX(x) = Zx
1
fX(u)du:
Attention : La fonction de densité n’est pas une probabiltié, elle peut
donc être plus grande que 1!
Propriétés de la fonction de densité :
La fonction de densité de toute variable aléatoire est dé…nie pour
tout x2R, mais n’est pas nécessairement dans [0; 1].
Elle est continue par morceaux telle que
fX(x)0pour tout x2Ret Z+1
1
fX(x)dx = 1:
De plus,
4

P(X2A) = ZA
fX(x)dx et P(aXb) = Zb
a
fX(x)dx:
et, si FXest dérivable en x(ou si fXest continue en x),
fX(x) = F0
X(x) = lim
h!0
FX(x+h)FX(xh)
h:
En fait, on peut dé…nir une variable aléatoire comme étant continue
si une telle fonction de densité fXexiste.
Remarque : Pour une variable aléatoire continue on a donc P(X=x) = Rx
xfX(x)dx =0
pour tout xpuisqu’on intègre sur un seul point...
Exemple : Variable aléatoire exponentielle.
Soit la variable aléatorie de densité fX(x) = exp (x)si x0et 0
sinon.
Sa fonction de répartition est donc la primitive de fX, cíest-à-dire
FX(x) = Zx
1
fX(u)du = 1 exp (x)si x0et 0sinon:
On dé…nit l’espérance d’une variable aléatoire continue Xcomme
E(X) = Z+1
1
xfX(x)dx
(si R+1
1 jxjfX(x)dx < 1).
De même, l’espérance d’une fonction d’une variable aléatoire
est dé…nie par (si R+1
1 jg(x)jfX(x)dx < 1)
E(g(X)) = Z+1
1
g(x)fX(x)dx:
On dé…nit le moment d’ordre kde la variable aléatoire Xpar
k=EXk=Z+1
1
xkfX(x)dx:
En…n, on dé…ni la variance d’une variable aléatoire continue Xpar
2=V ar (X) = E(XE(X))2=EX2(E(X))2
=Z+1
1
x2fX(x)dx Z+1
1
xfX(x)dx2
:
5
 6
7
8
9
10
11
12
13
14
15
16
6
7
8
9
10
11
12
13
14
15
16
1
/
16
100%