VAR à densité

LOIS DE PROBABILITES CONTINUES
Le plan est muni d’un repère orthonormé.
1 Densité de probabilité
Dans tout ce qui suit, Idésigne un intervalle quelconque de R.
Définitions :
•Soit fune fonction continue sur un intervalle de la forme [a; +∞[, sauf éventuellement en un nombre fini de
points.
Si la fonction x7→ Zx
a
f(t)dt possède une limite finie Lquand xtend vers +∞, on pose alors :
L=Z+∞
a
f(t)dt = lim
x→+∞Zx
a
f(t)dt.
•Soit fune fonction continue sur un intervalle de la forme ] − ∞;a], sauf éventuellement en un nombre fini de
points.
Si la fonction x7→ Za
x
f(t)dt possède une limite finie L′quand xtend vers −∞, on pose alors :
L′=Za
−∞
f(t)dt = lim
x→−∞ Za
x
f(t)dt.
Exemples
•f(t) = 1 si t∈[−1; 1]
0 sinon Alors : Z+∞
−∞
f(t)dt = 2.
Notation et définition : f=1[−1;1] est la fonction indicatrice, ou caractéristique de [-1 ;1].
•f(t) = e−tsi t>0
0 sinon Alors : Z+∞
−∞
f(t)dt = 1.
Remarque :f(t) = e−t1R+(t).
•f(t) = 1R+e−t+1R−et. Alors : Z+∞
−∞
f(t)dt = 2.
Définition Une fonction fest une densité de probabilité sur Isi :
•fest continue sur I, sauf éventuellement en un nombre fini de points de cet intervalle
•fest positive sur I:∀t∈I, f(t)>0
•Z+∞
−∞
f(t)dt = 1.
Exemples
•La fonction fdéfinie par f(t) = e−tsi t>0
0 sinon est une densité de probabilité sur Rcar :
1) fest continue sur R∗
2) fest positive sur R
3) Z+∞
−∞
f(t)dt = 1.
Remarque :fest aussi une densité de probabilité sur R+car ZR+
f(t)dt = 1.
•La fonction f définie par f(t) = (1
2si t∈[−1; 1]
0 sinon est une densité sur R, mais aussi sur [−1; 1].
Exercice :
ndésigne un entier naturel non nul. Trouver la valeur du réel apour que la fonction f définie par
f(t) = (a
tnsi t>1
0 sinon soit une densité de probabilité sur R.
1

2 Loi de probabilité
2.1 Définition
Définition
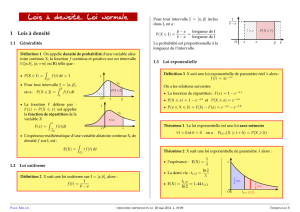
Soit fune densité de probabilité sur I. Soit Xune variable aléatoire à valeurs dans I.
Xsuit une loi de probabilité de densité fsur Isi pour tout intervalle Jinclus dans I:
P(X∈J) = ZJ
f(t)dt.
0.5
1.0
1.5
2.0
0.5 1.0−0.5−1.0−1.5
x=ax=b
P(a6X6b)
c
0.5
1.0
1.5
2.0
2.5
−0.5
0.5 1.0 1.5 2.0−0.5−1.0−1.5−2.0
x=a
P(a6X)
Exemples
•La fonction fdéfinie par f(t) = 4t3si t∈[0; 1]
0 sinon est une densité de probabilité sur Ret :
P(−26X63) = 1.
∀[a;b]⊂[0; 1], P (a6X6b) = b4−a4.
•Soit Xune variable aléatoire de densité fX(t) = e−tsi t>0
0 sinon
∀[a;b]⊂R+, P (a6X6b) = e−a−e−b.
Remarques importantes :
•Soient fet gdeux densités de probabilités sur Ine différant qu’en un nombre fini de points.
Si fest une densité de probabilité d’une variable aléatoire X, alors il en est de même pour g.
Le cours d’intégration assure en effet que :
∀J⊂I, ZJ
f(t)dt =ZJ
g(t)dt.
•Deux variables aléatoires ayant la même loi ne sont pas forcément égales.
2

2.2 Propriétés
Théorème
Soit Xune variable aléatoire à densité sur I. Soient Jet Kdeux intervalles inclus dans I.
•P(X∈I) = 1.
• ∀x∈I, P (X=x) = 0
• ∀[a;b]⊂I, P (a < X < b) = P(a6X6b) = P(a < X 6b) = P(a6X < b).
• ∀a∈R, P (X>a) = P(X > a).
•Si P(X∈J)6= 0, alors :
P(X∈J)(X∈K) = P[(X∈J)∩(X∈K)]
P(X∈J)·
•P[(X∈J)∪(X∈K)] = P(X∈J) + P(X∈K)−P[(X∈J)∩(X∈K)].
•Si de plus, Jet Ksont disjoints :
P[(X∈J)∪(X∈K)] = P(X∈J) + P(X∈K).
2.3 Fonction de répartition d’une variable aléatoire à densité
Définition
Soit Xune variable aléatoire à densité sur I.
La fonction de répartition de Xest la fonction F définie sur Rpar :
∀x∈R, F (x) = P(X6x).
Autrement dit : F(x) = Zx
−∞
f(t)dt.
Propriétés
i) F est croissante sur R.
ii) lim
x→+∞F(x) = 1 et lim
x→−∞ F(x) = 0.
Démonstration
Propriété : La relation de Chasles est encore licite pour une fonction continue sur I, sauf éventuellement en un
nombre fini de valeurs.
i) Soit ] − ∞;x]⊂]− ∞;y].
F(x) = Zx
−∞
f(t)dt 6Zx
−∞
f(t)dt +Zy
x
f(t)dt 6Zy
−∞
f(t)dt 6F(y).
F est donc croissante sur R.
ii) Par définition :
lim
x→+∞Zx
−∞
f(t)dt = 1,
ce qui se réécrit :
lim
x→+∞F(x) = 1.
D’autre part, soit xun réel quelconque donné. La relation de Chasles nous permet d’écrire :
Z+∞
−∞
f(t)dt =Zx
−∞
f(t)dt +Z+∞
x
f(t)dt = 1.Soit :
Zx
−∞
f(t)dt = 1 −Z+∞
x
f(t)dt.
En faisant tendre xvers −∞, nous obtenons :
lim
x→−∞ F(x) = 0.
Théorème
∀(a;b)∈R2, a 6b, P (a6X6b) = F(b)−F(a).
3

Démonstration
F(b)−F(a) = Zb
−∞
f(t)dt −Za
−∞
f(t)dt =Za
−∞
f(t)dt +Zb
a
f(t)dt −Za
−∞
f(t)dt =Zb
a
f(t)dt.
Théorème
Soit Xune variable aléatoire à densité de probabilité la fonction fsur I. Soit Fsa fonction de répartition.
Alors pour tout xoù fest continue, Fest dérivable en xet :
F′(x) = f(x).
2.4 Densité de αX +β
Exemples
•Uest une variable aléatoire ayant pour densité : fX(t) = 1 si t∈[0; 1]
0 sinon
On définit la variable aléatoire Ypar Y= 2U−3.
Les valeurs prises par Ysont les réels de l’intervalle [−3; −1].En effet, Uest à valeurs dans [0 ;1] et l’application
t7→ 2t−3 réalise une bijection de [0 ;1] dans [−3; −1].
Soit [a;b] un intervalle inclus dans [−3; −1].Nous avons :
P(a6Y6b) = P(a62U−36b) = P(a+ 3 62U6b+ 3) = P(a+ 3
26U6b+ 3
2) = Z
b+3
2
a+3
2
1dt =b−a
2·
Ceci montrer que Ya pour densité la fonction fY(t) = (1
2si t∈[−3; −1]
0 sinon
•Xest une variable aléatoire de densité : fX(t) = e−tsi t>0
0 sinon
Soit Yla variable aléatoire définie par Y=−X.
Xest à valeurs positives, donc Yest à valeurs négatives.
Donc :
◮Si [a;b] est inclus dans R+, alors P(Y∈[a;b]) = 0.
◮Si [a;b] est inclus dans R−, alors P(Y∈[a;b]) = P(X∈[−b;−a]) = Z−a
−b
e−tdt. Via le changement de
variable u=−tdans cette dernière intégrale, nous obtenons :
P(Y∈[a;b]) = Zb
a
eudu.
Ya donc pour densité fY(t) = etsi t60
0 sinon Ceci permet donc d’écrire : ∀t∈R, fY(t) = fX(−t).
Théorème
Soit Xune variable aléatoire à densité fXsur I. Soient (α;β) élément de R∗×R.La variable aléatoire Y=αX+β
est une variable à densité admettant pour densité la fonction gdéfinie par :
∀y∈R, g(y) = 1
|α|fy−β
α·
Démonstration
Supposons α > 0.
∀y∈R, Y 6y⇔αX +β6y⇔X6y−β
α·
Par conséquent : ∀y∈R, FY(y) = FXy−β
α·
Si fXest continue en y, alors FXl’est en y−β
αet dans ce cas :
F′
Y(y) = 1
αF′
Xy−β
α·F′
Xcoïncide avec fXsur Iprivé des points pour lesquels fXn’est pas continue et qui
sont en nombre fini.
De plus, y7→ 1
αfXy−β
αest à valeurs positives. Il s’agit donc d’une densité de Y.
Supposons maintenant que α < 0.
4

∀y∈R, P (Y6y)⇔P(αX +β6y)⇔PX>y−β
α·
On en déduit donc que : ∀y∈R, FY(y) = 1 −FXy−β
α·
Un raisonnement analogue au cas précédent permet de conclure qu’une densité de Yest la fonction :
fY:y7→=−1
αfXy−β
α=1
|α|fXy−β
α·
3 Espérance mathématique. Variance. Ecart-type
3.1 Espérance mathématique
Définition Soit Xune variable aléatoire continue de densité de probabilité fsur I. L’espérance mathématique
de X, notée E(X) ou µ, est, s’il existe, le réel défini par :
E(X) = ZI
tf(t)dt.
Remarque : En toute rigueur, il faut s’assurer que l’intégrale généralisée ZI|tf(t)|dt est convergente, ce qui
le cas lorsque Iest un segment et dans le cas des lois usuelles que nous étudierons cette année. Pour ceux que
cela intéresse, vous pourrez rechercher des renseignements sur la loi de Cauchy, qui ne possède pas d’espérance
mathématique.
Exemple
Soient a et b deux réels tels que : a < b. Soit fla fonction définie par :
f:(t7→ 1
b−asi t∈[a;b]
0 sinon
.
E(X) = Zb
a
t
b−adt =a+b
2·
Définition Une variable aléatoire Xest dite centrée si E(X) = 0.
Théorème : Linéarité de l’espérance.
Soient Xet Ydeux variables aléatoires à densité. Soient λet µdeux réels donnés.
Si les variables X,Ypossèdent une espérance, alors il en est de même pour λX +µY et :
E(λX +µY ) = λE(X) + µE(Y).
Démonstration : Admise
Théorème : Théorème de transfert.
Soit φune fonction continue sur I, changeant un nombre fini de fois sur I.
Soit fune fonction de densité sur I.
Sous couvert d’existence de l’intégrale ci-dessous, l’espérance de la variable φ(X) est donnée par :
E(φ(X)) = ZI
φ(t)f(t).
Exemple
E(X2) = ZI
t2f(t).
3.2 Variance. Ecart-type
Définition Soit Xune variable aléatoire continue possédant une espérance.
On dit que Xpossède une variance, notée V(X), si et seulement si la variable aléatoire (X−E(X))2possède
une espérance. On a dans ce cas :
V(X) = E[(X−E(X))2].
Théorème admis : V(X)>0.
5
 6
7
8
9
10
11
12
6
7
8
9
10
11
12
1
/
12
100%