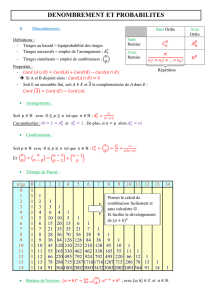
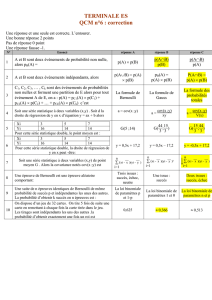
Réseaux de réactions : de l`analyse probabiliste à la réfutation

R´eseaux de r´eactions : de l’analyse probabiliste `a la
r´efutation
Vincent Picard
To cite this version:
Vincent Picard. R´eseaux de r´eactions : de l’analyse probabiliste `a la r´efutation. Bio-
informatique [q-bio.QM]. Universit´e Rennes 1, 2015. Fran¸cais. .
HAL Id: tel-01246180
https://tel.archives-ouvertes.fr/tel-01246180v2
Submitted on 18 Apr 2016
HAL is a multi-disciplinary open access
archive for the deposit and dissemination of sci-
entific research documents, whether they are pub-
lished or not. The documents may come from
teaching and research institutions in France or
abroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, est
destin´ee au d´epˆot et `a la diffusion de documents
scientifiques de niveau recherche, publi´es ou non,
´emanant des ´etablissements d’enseignement et de
recherche fran¸cais ou ´etrangers, des laboratoires
publics ou priv´es.

THÈSE / UNIVERSITÉ DE RENNES 1
sous le sceau de l’Université Européenne de Bretagne
pour le grade de
DOCTEUR DE L’UNIVERSITÉ DE RENNES 1
Mention : Informatique
École doctorale Matisse
présentée par
Vincent PICARD
préparée à l’unité de recherche IRISA – UMR6074
Institut de Recherche en Informatique et Systèmes Aléatoires
ISTIC - UFR Informatique - Électronique
Réseaux de réac-
tions : de l’analyse
probabiliste à la ré-
futation
Thèse soutenue à Rennes
le 16 décembre 2015
devant le jury composé de :
Frédérique BASSINO
Professeure à l’Université Paris 13 /Rapporteure
Vincent DANOS
Directeur de recherche au CNRS /Rapporteur
Paolo BALLARINI
Maître de conférence à l’École Centrale de Paris /
Examinateur
Madalena CHAVES
Chargée de recherche à INRIA /Examinatrice
Olivier RIDOUX
Professeur à l’Université de Rennes 1 /Examinateur
Anne SIEGEL
Directrice de recherche au CNRS /Directrice de thèse
Jérémie BOURDON
Professeur à l’Université de Nantes /
Co-directeur de thèse
ANNÉE 2015


松尾 芭蕉 Matsuo Bashō (1644-1694)
Comme il est admirable
Celui qui ne pense pas "la vie est éphémère"
En voyant un éclair
稲
妻
に
悟
ら
ぬ
人
の
尊
さ
よ
Inazuma ni
Satoranu hito no
Toutosa yo

 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
1
/
149
100%