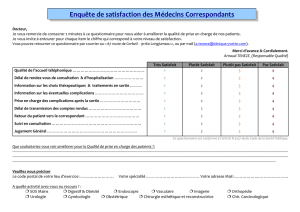
Cours #2

Statistique 51-601-02
Cours #2 et #3
Avons-nous des conditions
gagnantes?
Prise de décision à partir d’inférence

2
Bien souvent, une décision se prend à la suite
d’une analyse quantitative de certains
paramètres.
Exemples:
Deux concepts publicitaires vous sont proposés
pour lancer un nouveau produit. Vous choisirez
celui qui obtiendra le meilleur score d’efficacité
dans votre marché cible.
Si la résistance ou durabilité moyenne d’un
nouveau produit est significativement plus
grande que celle du meilleur produit concurrent,
vous mettrez ce produit sur le marché.
Si les « conditions gagnantes » sont réunies et
que plus de 50% des Québécois votaient oui à
un référendum sur la souveraineté, alors Bernard
Landry prendrait la décision d ’en faire un.

3
En général, les paramètres qui nous
intéressent sont estimés à l ’aide d ’un
échantillon et notre décision sera prise à la
suite d’un test d’hypothèse.
Exemple:
On demande à 1000 Québécois,
choisit au hasard et ayant le droit de
vote, s ’ ils voteraient oui,
aujourd’hui, à un référendum sur la
souveraineté du Québec.

4
Que fait Bernard Landry si:
432 électeurs votaient oui?
(432/1000 = 43,2%)
il ne fait définitivement pas un référendum.
517 électeurs votaient oui?
(517/1000 = 51,7%)
est-ce que 51,7 % est significativement plus grand que 50%?
612 électeurs votaient oui?
(612/1000 = 61,2%)
61.2% est fort probablement significativement plus grand que
50%. Donc il prend la décision de faire un référendum sur la
souveraineté du Québec.

5
Notions de base des tests
d’hypothèses
Pour nous aider à prendre une décision (surtout
dans le cas 2 de la diapositive précédente), nous
essayerons de quantifier le terme
«significativement différent », statistiquement
parlant, en y associant une probabilité d’erreur.
En d’autres termes, nous voulons savoir, à partir
des résultats obtenus dans l ’échantillon, quelle est
la probabilité que le Premier Ministre a de se
tromper en prenant la décision de faire un
référendum sur la souveraineté.
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
1
/
76
100%