Exam2016bis Fichier

Modèle linéaire – HMMA201
Examen 2ème session
Documents et calculatrice autorisés.
Durée : 2 heures.
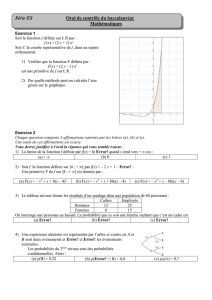
Exercice 1. Dans le modèle linéaire simple (yi=β1+β2xi+i), on considère
ici que les erreurs i, i = 1,· · · , n, ne sont pas gaussiennes mais suivent une
loi de densité
f(t) = 1
π(1 + t2), t ∈R.
1) Montrer que la fonction fest bien une densité de probabilité. Quelle est
l’espérance de i?
2) Exprimer la vraisemblance des observations L(β1, β2). En déduire que les
estimateurs du maximum de vraisemblance de β1et β2sont les réels ˜
β1et
˜
β2minimisant n
Y
i=1
(1 + ˆ2
i).
Exercice 2. On examine l’évolution d’une variable Yen fonction de deux
variables xet z. On dispose de nobservations de ces variables. On note
X= (11 x z)où 11 est le vecteur constant et x, z sont les vecteurs des variables
explicatives. Nous avons obtenu les résultats suivants :
X0X=
30 20 0
20 20 0
0 0 10
,
X0Y= (15,20,10)0et Y0Y= 59.5.
1) Vérifier que ˆ
β= (−1/2,3/2,1)0sans inverser de matrice.
2) Calculer les coefficients de corrélation linéaire ρ(x, y),ρ(x, z)et ρ(y, z).
3) Calculer la somme des carrés totaux : SCT =Pn
i=1(yi−¯y)2.
4) Calculer la somme des carrés expliqués par le modèle complet :
SCE =Pn
i=1(ˆyi−¯y)2.
5) En déduire le R2du modèle complet.
6) Doit-on supprimer la variable xou la variable zdu modèle de régression ?
Exercice 3. Soit le jeu de données suivant :
sexe F M F F M M M M
niveau études +++− − +− −
revenu 14 17 13 10 8 9 11 6
où +désigne les personnes ayant un niveau supérieur ou égal au bac.
1) Combien a-t-on de facteurs ? Combien de modalités prennent-ils ?
2) Que peut-on dire du plan d’expérience ?
3) On cherche à minimiser les erreurs en valeur absolue. Donner une esti-
mation du revenu d’une femme bachelière et d’une personne n’ayant pas son
bac.

Exercice 4. On dispose de deux vecteurs xet ydécrivant les valeurs prises
par 2 variables Xet Y.
Les instructions effectuées sur R ainsi que les sorties sont données ci-dessous :
> mod1=lm(y~x)
> summary(mod1)
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-0.47094 -0.25211 -0.05736 0.23325 0.48702
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.02088 0.07030 -0.297 0.7698
x 0.17161 0.06703 2.560 0.0197 *
---
Signif. codes: 0 *** 0.001 ** 0.01 * 0.05 . 0.1 1
Residual standard error: 0.3102 on 18 degrees of freedom
Multiple R-squared: 0.2669, Adjusted R-squared: 0.2262
F-statistic: 6.555 on 1 and 18 DF, p-value: 0.01967
> mod2=lm(y~x-1)
> summary(mod2)
Call:
lm(formula = y ~ x - 1)
Residuals:
Min 1Q Median 3Q Max
-0.48607 -0.27308 -0.08198 0.21265 0.46651
Coefficients:
Estimate Std. Error t value Pr(>|t|)
x 0.17485 0.06453 2.709 0.0139 *
---
Signif. codes: 0 *** 0.001 ** 0.01 * 0.05 . 0.1 1
Residual standard error: 0.3027 on 19 degrees of freedom
Multiple R-squared: 0.2787, Adjusted R-squared: 0.2407
F-statistic: 7.341 on 1 and 19 DF, p-value: 0.01390
a) Quelle est la différence entre le premier et le deuxième modèle ? Donner
les équations des deux droites de régression estimées.
b) On s’intéresse au premier modèle. Que dire de la significativité des coef-
ficients ? Justifier.
c) Rappeler quelles sont les hypothèses faites sur les erreurs qui mènent à
cette interprétation.
1
/
2
100%