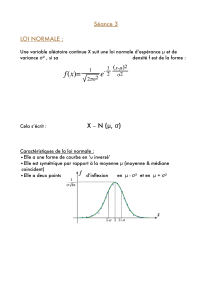
Variables à densité - Mathématiques en ECE 2

\
X
X FXR
∀x∈R, FX(x) = P(X≤x)
P(X=x) = P(X≤x)−P(X < x) = FX(x)−lim
y→x,y<x FX(y)
(X≤x)=(X < x)∪(X=x)
P(X≤x) = P(X < x) + P(X=x)P(X=x) = P(X≤x)−P(X < x)
(X < x) =
+∞
S
n=0 X≤x−1
n
P(X < x) = lim
n→+∞
PX≤x−1
n= lim
y→x,y<x FX(y)
P(X=x) = FX(x)−lim
y→x,y<x FX(y)
FXlim
y→x,y<x FX(y) = FX(x)P(X=x)=0
P(X∈]a;b]) = FX(b)−FX(a)
lim
x→−∞ FX(x) = 0 lim
x→+∞FX(x)=1

\
(X≤b)=(X≤a)∪(a<X≤b)
FXx≤y(X≤x)⊂(X≤y)
FX(x)≤FX(y)FX0≤FX(x)≤1
−∞ +∞
+∞
S
n=0
(X≤n) = R
P(X∈R) = 1 = lim
n→+∞
P(X≤n) = lim
n→+∞
FX(n) = lim
x→+∞
FX(x)
+∞
T
n=0
(X≤ −n) = ∅
P(X∈ ∅) = 0 = lim
n→+∞
P(X≤ −n) = lim
n→+∞
FX(−n) = lim
x→−∞
FX(x)
fXR
∀x∈R, FX(x) = Rx
−∞ fX(t)dt
fXX
X
R+∞
−∞ fX(t)dt = 1
FX(x) = Rx
−∞ fX(t)dt −−−−−→
x→+∞R+∞
−∞ fX(t)dt
X FX(x)−−−−−→
x→+∞1
f:R→R+
R+∞
−∞ f(t)dt = 1
X f X
f(t) = (0t≤0
e−tt > 00≥0e−t≥0R+
t→0t→e−t
R+∞
−∞ f(t)dt =R0
−∞ 0dt +R+∞
0e−tdt = 0 + R+∞
0e−tdt
Rx
0e−tdt = [−e−t]x
0= 1 −e−x−−−−−→
x→+∞1
g(t) = (0t < 1
2
t3t≥10≥02
t3≥0 [1; +∞[
t→0t→2
t3
R+∞
−∞ g(t)dt =R1
−∞ 0dt +R+∞
1
2
t3dt = 0 + R+∞
1
2
t3dt
Rx
1
2
t3dt =−1
t2x
1= 1 −1
x2−−−−−→
x→+∞1

\
h(t) =
0t≤ −1
|t| − 1< t < 1
0t≥1
R0≥0|t| ≥ 0−1
1
R+∞
−∞ h(t)dt =R−1
−∞ 0dt+R1
−1|t|dt+R+∞
10dt =R0
−1−t dt+R1
0t dt =h−x2
2i0
−1+hx2
2i1
0=1
2+1
2= 1
f g h
X fXX
XR+∞
−∞ tf(t)dt
E(X) = R+∞
−∞ tf(t)dt X
[0; +∞[tf(t)≥0
+∞]−∞; 0] tf(t)≤0
−∞ R−tf(t)Rtf(t)
f(t) = (e−tt≥0
0f
X
E(X) = R+∞
−∞ tf(t)dt =R0
−∞ 0dt +R+∞
0te−tdt =R+∞
0te−tdt
Rx
0te−tdt
u=t v =−e−tC1R[0; x]u0= 1 v0=e−t
Rx
0te−tdt =−te−tx
0+Rx
0e−tdt =−xe−x+0+−e−tx
0=−xe−x+ 1 −e−x−−−−−→
x→+∞1
f X
E(X) = 1
g(t) = (1
t2t≥1
0
R1
t2R+∞
−∞ g(t)dt =
R1
−∞ 0dt +R+∞
1
1
t2dt
Rx
1
1
t2dt =−1
tx
1= 1 −1
x−−−−−→
x→+∞1g
Y
E(Y) = R1
−∞ 0dt +R+∞
1
1
tdt =R+∞
1
1
tdt +∞α= 1
Y
E(X) = 0 X
X Y =X−E(X)

\
X fXg
g(X)
R+∞
−∞ g(t)fX(t)dt g(X)
E[g(X)] = R+∞
−∞ g(t)fX(t)dt
E(aX +b) = aE(X) + b X
g(t) = at +b aX +b=g(X)
R+∞
−∞ |g(t)fX(t)| |at +b|fX(t)≤ |a| |t|f(t) + |b|f(t)
RX
aX +b
E(aX +b) = R+∞
−∞ (at +b)fX(t)dt =aR+∞
−∞ tf(t)dt +bR+∞
−∞ fX(t)dt =aE(X) + b
r
r X
X r Xr
R+∞
−∞ trfX(t)dt
mr(X) = E(Xr) = R+∞
−∞ trfX(t)dt
r X
X r X r0r0≤r
tr0=o(tr) +∞tr0f(t) = o(trf(t)) +∞
−∞
X X X2
X
V(X) = E(X2)−[E(X)]2=E[X−E(X)]2
X
σ(X) = pV(X)
X

\
f(t) = (e−tt≥0
0X
E(X2) = R+∞
−∞ t2f(t)dt =R0
−∞ 0dt +R+∞
0t2e−tdt
Rx
0t2e−tdt
u=t2v=−e−tC1R[0; x]u0= 2t v0=e−t
Rx
0t2e−tdt =−t2e−tx
0+Rx
0te−tdt =−x2e−x+ 2 Rx
0te−tdt 2
−−−−−→
x→+∞R+∞
0te−tdt = 2
X V (X) = E(X2)−[E(X)]2= 2 −12= 1
g(t) = (2
t3t≥1
0Y
t≥1t2g(t) = 2
t+∞
Y
X E(X) = 0 V(X) = 1
X
X X∗=X−E(X)
σ(X)
 6
7
8
9
10
11
12
13
14
6
7
8
9
10
11
12
13
14
1
/
14
100%