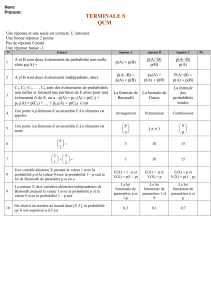
1 Lois et génération d`échantillons

Master 1 GSI - Mentions ACCIE et RIM - ULCO, La Citadelle, 2012/2013
Mesures et Analyses Statistiques de Données - Probabilités
TP 2 - Probabilités sous R
1 Lois et génération d’échantillons
1.1 Généralités
1. Génération d’échantillons aléatoires à partir d’un vecteur :
> vect<-seq(3,12) ; sample(vect,5)
fournit un échantillon aléatoire de 5 valeurs prises dans le vecteur donné, sans remise (la taille de l’échan-
tillon doit être inférieure à la taille du vecteur).
> sample(vect,5,replace=TRUE)
fournit un échantillon aléatoire de 5 valeurs prises dans le vecteur donné, mais avec remise.
> sample(vect)
fournit un échantillon aléatoire de length(vect) valeurs prises dans vect (c’est-à-dire une permutation).
> sample(10,5)
fournit un échantillon aléatoire de 5 valeurs parmi les 10 premiers entiers (i.e. parmi seq(1,10)).
> sample(seq(1,4),3,prob=c(0.1,0.2,0.3,0.4),replace=TRUE)
fournit un échantillon aléatoire de 3 valeurs prises parmi le vecteur donné, chaque valeur étant choisie
avec une probabilité proportionnelle aux valeurs données dans l’argument prob. La somme des poids n’a
pas besoin d’être 1.
2. Génération d’un échantillon gaussien :
> rnorm(100,0,1)
retourne un vecteur de 100 valeurs tirées d’une distribution gaussienne de moyenne 0 et d’écart-type 1.
> rnorm(100,mean=0,sd=1)
réalise la même chose.
> rnorm(1000,mean=c(0,3),sd=c(0.5,1))
permet d’obtenir une distribution de valeurs bimodale.
3. Génération d’un échantillon suivant une loi uniforme :
> runif(100,0,5)
retourne 100 valeurs issues d’une distribution uniforme entre 0 et 5.
> runif(100,min=0,max=5)
réalise la même chose.
1/9

> runif(100,c(0,1),c(5,7))
permet d’avoir la superposition de 2 distributions uniformes.
4. Tables de lois de probabilités : pour chaque loi (par exemple, la loi normale : norm), on a :
– La fonction de densité de probabilité, préfixe "d" : dnorm (la courbe en cloche).
– La fonction de probabilité qui varie entre 0 et 1, préfixe "p" : pnorm (pnorm(x) est la probabilité d’avoir
une valeur inférieur à x).
– La fonction quantile qui est l’inverse de la fonction de probabilité, préfixe "q" : qnorm (qnorm(y) est la
valeur pour laquelle la probabilité d’être inférieure à cette valeur est y, donc qnorm(pnorm(x))=x).
– La fonction de génération de nombres aléatoires, préfixe "r" : rnorm (génère des nombres aléatoires suivant
la loi). Le premier argument est la taille de l’échantillon souhaité.
5. Lois pour lesquelles les fonctions d, p, q et r sont disponibles :
Les d, p, q et r disponibles dans la distribution standard de Rsont donnés dans la table 1, ceux disponibles
dans le package SuppDists sont donnés dans la table 2.
dpqr
beta dbeta pbeta qbeta rbeta
binom dbinom pbinom qbinom rbinom
cauchy dcauchy pcauchy qcauchy rcauchy
chisq dchisq pchisq qchisq rchisq
exp dexp pexp qexp rexp
f df pf qf rf
gamma dgamma pgamma qgamma rgamma
geom dgeom pgeom qgeom rgeom
hyper dhyper phyper qhyper rhyper
lnorm dlnorm plnorm qlnorm rlnorm
logis dlogis plogis qlogis rlogis
nbinom dnbinom pnbinom qnbinom rnbinom
norm dnorm pnorm qnorm rnorm
pois dpois ppois qpois rpois
signrank dsignrank psignrank qsignrank rsignrank
t dt pt qt rt
unif dunif punif qunif runif
weibull dweibull pweibull qweibull rweibull
wilcox dwilcox pwilcox qwilcox rwilcox
Table 1 – Les lois de probabilité définies dans R
.
d p q r
Friedman dFriedman pFriedman qFriedman rFriedman
ghyper dghyper pghyper qghyper rghyper
invGauss dinvGauss pinvGauss qinvGauss rinvGauss
Johnson dJohnson pJohnson qJohnson rJohnson
Kendall dKendall pKendall qKendall rKendall
KruskalWallis dKruskalWallis pKruskalWallis qKruskalWallis rKruskalWallis
maxFratio dmaxFratio pmaxFratio qmaxFratio rmaxFratio
NormScore dNormScore pNormScore qNormScore rNormScore
Pearson dPearson pPearson qPearson rPearson
Spearman dSpearman pSpearman qSpearman rSpearman
Table 2 – Les lois de probabilité définies dans le package SuppDists
Précisons l’utilisation de ces fonctions dans les cas les plus fréquents :
–[dpqr]norm(x,mean=0,sd=1) : loi normale.
–[dpqr]unif(x,min=0,max=1) : loi uniforme.
–[dpqr]chisq(x,df,ncp=0) : loi du chi2.
2/9

–[dpqr]t(x,df) : loi tde Student.
–[dpqr]f(x,df1,df2,ncp) : loi F.
–[dpqr]exp(x,rate=1) : loi exponentielle.
–[dpqr]gamma(x,shape,rate=1,scale=1/rate) : loi gamma.
–[dpqr]binom(x,size,prob) : loi binomiale (x doit être entier pour dbinom, sinon le résultat est 0).
–[dpqr]dpois(x,lambda) : loi de Poisson (x doit être entier pour dpois, sinon le résultat est 0).
– Autres lois : beta, cauchy, geom (géométrique), hyper (hypergéométrique), lnorm (log-normale),
logis (logistique), nbinom (négative binomiale), weibull, wilcox.
6. Quantiles :
> vect=c(seq(1 :11))
> quantile(vect,probs=seq(0,1,0.1))
donne les 11 valeurs qui déterminent les intervalles de déciles (autant de valeurs renvoyées que de va-
leurs de probs).
> quantile(vect,probs=c(0,1))
équivalent simplement à range(vect) (min et max).
> quantile(vect,probs=c(0.5))
c’est simplement la médiane !
1.2 [dpqr]
Exercice 1
1. Donnez toutes les valeurs de la loi binomiale pour n= 10 et p= 1/3avec une précision de 10−7.
2. Même chose avec une précision de 10−4.
3. Quelle est la probabilité d’obtenir 1avec une loi binomiale pour n= 1 et p= 1/3?
4. Quelle est la probabilité d’obtenir plus de 45 et moins de 55 avec une loi binomiale pour n= 100 et p= 1/2?
(Aidez-vous de l’aide ?dbinom)
5. Quelle est la probabilité d’obtenir au plus 1 avec une loi binomiale pour n= 10 et p= 1/3?
On notera que ddonne les valeurs P(X=j)(densité, définie pour les valeurs possibles) et que pdonne les
valeurs P(X≤x)(fonction de répartition, définie pour tout x).
Exercice 2
1. Quelle est la probabilité de dépasser strictement 4 pour une loi de Poisson de paramètre 2,7?
2. Quelle est la probabilité de dépasser 1,96 pour une loi normale centrée réduite ?
3. Quelle est la valeur xtelle que P(X≤x)=0,975 pour une loi normale (quantile) ?
Exercice 3
1. Donnez un échantillon aléatoire simple de 10 valeurs d’une loi de Poisson de paramètre 2,7,
2. d’une loi normale réduite,
3. d’une loi Khi2 à 2 ddl,
4. d’une loi binomiale n= 100 et p= 1/2.
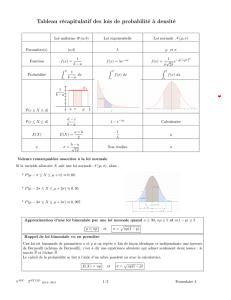
La Figure 1 illustre l’utilisation de [dpqr] dans le cas d’une loi binomiale avec n= 20 et p= 0,5et de son
approximation par une loi continue, la loi normale de paramètres m=np et σ=pnp(1 −p).ddonne la fonction de
densité de probabilité, c’est-à-dire les valeurs P(X=j). Notez la différence entre la loi discrète et la loi continue :
dans le cas de la loi discrète la fonction n’est définie que pour les valeurs possibles (0,1,2, . . . , n).pdonne la
fonction de répartion, c’est-à-dire P(X≤j). Elle est définie partout, aussi bien pour la loi discrète que pour la loi
continue. qdonne les quantiles, c’est la fonction réciproque de la fonction de répartition. rdonne un échantillon
pseudo-aléatoire.
3/9

Figure 1 – Illustration de dpqr
Exercice 4 Que font ces lignes de commande ? Indiquez ce que Rvous retourne.
> qnorm(0.975) ;
> dnorm(0)
> pnorm(1.96)
> rnorm(20)
> rnorm(10,mean=5,sd=0.5)
> x=seq(-3,3,0.1) ;pdf=dnorm(x) ;plot(x,pdf,type="l")
> runif(3)
> rt(5,10)
Remarque 1.1 1. On a écrit x=seq(-3,3,0.1). Ici xest un nom de variable. Les noms de variables sont
trèes flexibles. N’importe quelle variable peut stocker n’importe quelle valeur (il n’y a pas besoin de déclarer
les variables). Cependant, il faut savoir que :
– les noms de variables ne peuvent pas commencer par un chiffre ou un caractère spécial,
– les noms sont sensibles à la casse des caractères. Un caractère minuscule comme xest différent d’un
caractère majuscule comme X.
– quelques noms courants sont déjà utilisés par R, par exemple c, q, t, C, D, F, I, T et par conséquent
doivent être évités. La liste des noms prédéfinis dans la bibliothèque de base peut être consultée ainsi :
> noms <- ls("package :base")
> length(noms)
Combien y en a-t-il d’installés sur l’ordinateur avec lequel vous travaillez ? Si vous souhaitez les voir
apparaître à l’écran, tapez noms.
2. Dans cette liste de commandes, l’opérateur =a été utilisé. Comme la plupart des langages de programmation,
Ra des variables auxquelles on peut affecter une valeur. Pour cela, on utilise l’opérateur <- ou ->. L’opérateur
classique =marche aussi.
3. De plus dans cette liste de commandes, deux fonctions sont intervenues :
–seq()
–plot()
Vous remarquerez que les appels aux fonctions sous Rsont indiqués par la présence de parenthèses. De plus,
length() et ls() sont aussi des fonctions. Pour en savoir d’avantage sur ces fonctions, tapez ?sujet que
4/9

nous pouvons aussi écrire help(sujet). Toutes les fonctions de Ront une page d’aide. Quand vous connaissez
le nom de la fonction ou du sujet qui vous intéresse, c’est en général le meilleur moyen d’apprendre à l’utiliser.
Les pages d’aide sont généralement très détaillées. Elles contiennent souvent, entre autres :
– Une section See Also qui donne les pages d’aide sur des sujets apparentés.
– Une section Description de ce que fait la fonction.
– Une section Examples avec du code illustrant ce que fait la fonction documentée. Ces exemples peuvent
être exécutés directement en utilisant la fonction example(), essayez par exemple :
> example(plot)
4. La manière la plus simple de produire des graphiques sous R est d’utiliser la fonction plot().
> plot(weight∼height, data=women)
Les fonctions graphiques comportent de nombreuses options qui permettent de contrôler de façon très fine
les graphiques. Par exemple, les paramètres de la fonction plot() utilisées par défaut sont :
> args(plot.default)
function (x, y = NULL, type = "p", xlim = NULL, ylim = NULL,
log = "", main = NULL, sub = NULL, xlab = NULL, ylab = NULL,
ann = par("ann"), axes = TRUE, frame.plot = axes, panel.first =NULL,
panel.last = NULL, asp = NA, ...)
NULL
L’argument . . . signifie qu’il y a encore d’autres paramètres graphiques possibles. Ils sont contrôlés par la
fonction par().
> names(par())
[1] "xlog" "ylog" "adj" "ann" "ask" "bg"
[7] "bty" "cex" "cex.axis" "cex.lab" "cex.main" "cex.sub"
[13] "cin" "col" "col.axis" "col.lab" "col.main" "col.sub"
[19] "cra" "crt" "csi" "cxy" "din" "err"
[25] "family" "fg" "fig" "fin" "font" "font.axis"
[31] "font.lab" "font.main" "font.sub" "gamma" "lab" "las"
[37] "lend" "lheight" "ljoin" "lmitre" "lty" "lwd"
[43] "mai" "mar" "mex" "mfcol" "mfg" "mfrow"
[49] "mgp" "mkh" "new" "oma" "omd" "omi"
[55] "pch" "pin" "plt" "ps" "pty" "smo"
[61] "srt" "tck" "tcl" "usr" "xaxp" "xaxs"
[67] "xaxt" "xpd" "yaxp" "yaxs" "yaxt"
On donne ci-dessous un exemple de graphique utilisant quelques options :
> plot(weight height, pch=19, col="royalblue3",
+ las=1,main="Weight vs. height", xlab="Height",
+ ylab=Weight", data="women")
Il existe une autre fonction que plot() pour faire des graphiques. Cette fonction est la fonction curve().
2 Loi binomiale
Soit Xune variable aléatoire suivant une loi binomiale. La probabilité d’obtenir ksuccès pour nessais indé-
pendants avec une probabilité pde succèes est : P(X=k) = n
kpk(1 −p)n−k,0≤k≤n.
Si on pose m=np et σ2=np(1 −p), la loi binomiale normalisée est définie par :
φ•=ϕ•
0=0−m
σ,1−m
σ,...,n−m
σ,
et
5/9
 6
7
8
9
6
7
8
9
1
/
9
100%