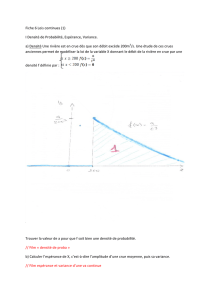
1.1 Définition : espace de probablité discret

Probabilité discrète
METHODE STATISTIQUES POUR L’INFORMATIQUE
CHAPITRE 1
LICENCE INFORMATIQUE – UNIVERSITE BORDEAUX 1 –
SEMESTRE 5 – ANNEE SCOLAIRE 2004/2005

1
1 GENERALITES
Exemple : on lance deux dés.
= DxD = { 1,1 ; 1,2 ; … ; 6,6 } = 36 éléments
Lorsque la distribution est uniforme, on a :
Tous les éléments de sont de même probabilité 1/36 ;
Tous les éléments de D sont de même probabilité 1/6.
1.1 DEFINITION : ESPACE DE PROBABLITE DISCRET
Un espace de probabilité discret est un couple (
, Pr), où
est un ensemble non vide, au plus dénombrable, et
Pr une application de
dans [0,1] telle que
w
Pr(w)=1 (somme des probabilités des éléments de
= 1).
: espace des évènements élémentaires
A : évènement
Pr : une loi (ou distribution) de probabilité sur
On prolonge Pr sur P() par : Pr(A)=wAPr(w), A , Pr(A) : probabilité de A.
1.1.1 Propositions
Pr()=0
Pr(/A)=1 – Pr(A)
Pr(UiI Ai) = iI Pr(Ai) pour toute famille au plus dénombrable Ai, i I d’éléments de P() deux à
deux disjoints.
1.1.2 Exemple
On peut adopter l’hypothèse non uniforme en posant :
Pr2(1)=Pr2(6)=1/4
Pr2(2)=Pr2(3)= Pr2(4)= Pr2(5)=1/8
Sur =DxD, on peut définir la distribution produite : Pr22(dd’)=Pr2(d)Pr2(d’). On a alors par exemple
Pr22(6,3)=1/4*1/8=1/32.
On démontrera facilement que Pr22 est bien une distribution de probabilité sur .
A titre d’exemple, on peut définir l’évènement double par : A={1,1 ; 2,2 ; … ; 6,6}. On a vu que
Pr(A)=wAPr(w), donc :
Dans le cas d’une distribution uniforme, cette probabilité vaut : 1/36+1/36+1/36+1/36+1/36+1/36=1/6
Pour Pr22, elle vaut : (1/4*1/4)+(1/8*1/8)+1/64+1/64+1/64+1/16=3/16.
1.2 DEFINITION : VARIABLE ALEATOIRE
Soit (
, Pr) un espace de probabilité discret et soit
’ un ensemble non vide au plus dénombrable. Une variable
aléatoire (v.a) X à valeurs dans
’ est une application de
dans
’. Nous prenons souvent pour
’ un sous
ensemble de N ou R. On pourra munir
’ d’une loi de probabilité PrX en posant
w’
’ : PrX(w’) = Pr(X-
1({w’})).
1.2.1 Propositions
PrX est une loi de probabilité sur
’
w’
’PrX(w’)=1.
Nous avons de plus, pour tout A’
’ : PrX(A’) = Pr(X-1(A’)).
Remarque : lorsqu’il n’y aura pas de confusion, PrX sera désigné par Pr.

2
1.2.2 Exemple
Soit S(w) la variable aléatoire qui est la somme des points de deux dés. Par exemple S(3,6)=3+6=9. Le tableau
ci-dessous caractérise la loi de probabilité pour la variable aléatoire S par rapport à chacune des distributions
(uniforme et biaisée) :
S
2
3
4
5
6
7
8
9
10
11
12
Pr11(S=s)
1/36
2/36
3/36
4/36
5/36
6/36
5/36
4/36
3/36
2/36
1/36
Pr22(S=s)
4/64
4/64
5/64
6/64
7/64
12/64
7/64
6/64
5/64
4/64
4/64
2 ESPERANCE MATHEMATIQUE ET VARIANCE
2.1 ESPERANCE
2.1.1 Définition : espérance
Une variable aléatoire admet un certain nombre de valeurs typiques. Nous considérons dans la suite les v.a à
valeurs dans R. En arithmétique usuelle, la valeur moyenne de n nombre est définie comme leur somme divisée
par n. En calcul de probabilité, l’espérance d’une variable aléatoire est définie comme la somme des valeurs
prises pondérées par les probabilités respectives c'est-à-dire EX=
x
X(
) x.Pr(X=x) lorsque cette somme
converge absolument.
(X(
) est l’ensemble des valeurs prises par la variable aléatoire X)
Sinon, on dit que X n’admet pas d’espérance.
2.1.2 Exemple
Revenons au cas de la v.a S désignant la somme de deux dés et calculons son espérance pour chacune des
distributions Pr11 et Pr22 :
E11S=2*1/36+3*2/36+ … = 7
E22S=2*4/64+3*4/64+ … = 7
Etant donné que l’espérance de la valeur aléatoire X désignant le point obtenu par un seul dé vaut :
E1X=1/6(1+2+…+6)=3.5 (pour un dé uniforme)
E2X=1/4*(1+6)+1/8*(2+3+4+5)=3.5 (pour un dé pipé)
On peut se demander s’il y a un lien entre l’espérance d’une somme de valeur aléatoire et la somme des
espérance.
2.1.3 Linéarité de l’espérance
Soient X1 et X2 deux v.a définies sur le même espace de probabilité discret (
, Pr) et admettant toutes deux une
espérance E. Soit
R alors :
E(
X1) =
.E(X1)
E(X1+X2)=E(X1)+E(X2)
Que peut-on dire sur l’espérance d’un produit de valeur aléatoire?

3
2.2 DISTRIBUTION CONJOINTE
2.2.1 Définition
On peut considérer plusieurs v.a sur le même espace probabilisé discret (
). Soient les v.a X et Y définies sur
(
, Pr). La loi (ou distribution conjointe) est la donnée de : PrXY=(X=x, Y=y)=Pr({w
/X(w)=x, Y(w)=y})
x,y.
X et Y sont dites indépendantes, si x, y on a PrXY(W=x,Y=y)=PrX(x).PrY(y).
Si X et Y sont deux valeurs indépendantes admettant une espérance, alors la valeur aléatoire produite XY admet
un espérance et E(XY)=E(X).E(Y).
2.2.2 Exemple
Soient X et Y les points obtenus en lançant deux dés (nous considérons le cas des dés uniformes et celui des dés
pipés). Les deux v.a son indépendantes (par définition de Pr11 et Pr22). Soient S=X+Y et P=XY. Nous avons :
ES=7/2+7/2=7
EP=7/2*7/2=49/4
Mais S et P ne sont pas indépendantes. Nous avons toutefois E(S+P)=ES+EP=7+49/4. Un calcul des probabilités
de valeurs SP permet d’obtenir ESP=637/6 dans le as des dés uniformes et 112 pour les dés pipés. Ce qui est
différent dans les deux cas de ES.EP=7*49/4=343/4.
2.3 VARIANCE
2.3.1 Définition
Un paramètre important qui vient tout de suite après l’espérance est la Variance. Elle mesure la dispertion
d’une valeur aléatoire. Si X est une v.a définie sur (
, Pr), sa variance est définie par VX=E((X-EX)²) lorsuqe
celle-ci existe.
Nous avons VX=E(X²) – E(X²).
Si X et Y sont 2 v.a indépendantes admettant chacune une variance, alors la v.a de X+Y admet une variance qui
est la somme des deux variances.
2.3.2 Exemple
La probabilité d’un gain égal à 100 millions € pour un billet de loterie est de 1/100. Nous disposons de deux
choix pour acheter les billets : soit 2 billets distincts, soit 2 billets quelconques. Les espérances dans les deux
alternatives sont égales et valent chacune 2 millions €. Comparons les en fonction de leur variance :
Dans la première alternative, on peut gagner 0 ou 100 millions avec les probabilités respectives 0.98 et
0.02.
Dans la deuxième on peut gagner 0, 100, 200 millions € avec les probabilités respectives 0.9801,
0.0198, et 0.0001
On calcule les variances :
Pour la première alternative on obtient donc la variance (en 1012€) : 0.98(0-2)²+0.02(100-2)²=196.
Et pour la deuxième : 0.9801(0-2)²+0.0198(100-2)²+0.0001(200-2)²=198
On en déduit que la seconde alternative est légèrement plus risquée que la première.
2.3.3 Exemple avec les dés
Nous avons vu que pour un dé uniforme : EX=1/6(1+2+3+4+5+6)=3.5.
Donc VX= 1/6(1-3.5)² + 1/6(2-3.5)² + 1/6(3-3.5)² + 1/6(4-3.5)² + 1/6(5-3.5)² + 1/6(6-3.5)²=2.2

4
2.3.4 Ecart type
La racine carrée de la variance est appelée écart type et est notée par
:
X=
(VX)
3 FONCTIONS GENERATRICES
3.1 DEFINITION
Lorsque les V.a prennent des valeurs dans N, l’utilisation des fonctions génératrices pour les suites des
probabilités et les techniques associées deviennent les outils favoris dans l’étude des distributions discrète. La
fonction génératrice d’une v.a X à valeurs dans N est définie par : GX(z) =
k
0 Pr(X=k).zk
Cette série entière en z contient toutes les informations sur la v.a. X. Elle est par ailleurs l’espérance de zX,
puisque : GX(z) = w Pr(w).zX(w).
3.1.1 Exemple
Soit A={a, b, c, d} un alphabet de quatre lettres. Appelons L l’ensemble des mots L={a, b, c}*d.
Supposons maintenant qu’on tire successivement une lettre dans A avec la même probabilité ¼, jusqu’à ce qu’on
obtienne la lettre d. L’ensemble des mots qui peuvent être obtenus par ces tirages est le même langage L
introduit précédemment.
On peut munir =L d’une distribution de probabilité en associant à chaque mots L la probabilité de son tirage.
Par exemple Pr(ababad)=1/4*1/4*1/4*1/4*1/4*1/4=1/46.
Soit X la v.a associant à chaque mot de L sa longueur. Il est facile de voir que
k
k
kX 4
3
)Pr( 1
.
La fonction génératrice de X est donc
1
1
34
.
4
3
)( k
k
k
k
Xz
z
zzG
3.2 PROPRIETES ELEMENTAIRES
Dans la suite nous retirons X de GX(z) lorsqu’il n’y a pas de danger de confusion. On peut retenir deux
propriétés élémentaires :
G(1)=1.
On peut obtenir l’espérance et la variance d’une variable aléatoire à partir de sa fonction génératrice
par :
o EX=G’(1) .
o VX=G’’(1)+G’(1) – [G’(1)]² .
3.2.1 Exemple
Reprenons le cas du langage L précédent, muni de la distribution qui associe à tout mot de longueur k une
probabilité égale à 1/4k. On peut alors calculer G’(1)=4 et G’’(1)=24. On a donc l’espérance EX=4 et la variance
VX = 24 + 4 – 4² = 12.
3.3 UNE AUTRE PROPRIETE IMPORTANTE
Une autre propriété caractéristique des fonctions génératrices est la suivante qui est très utile en calcul des
probabilités, lorsqu’on a affaire à la somme des valeurs aléatoires.
Soient X et Y deux v.a indépendantes. La fonction génératrice de la v.a X+Y est le produit des fonctions
génératrices de X et de Y : GX+Y(z)=GX(z). GY(z).
 6
7
8
9
10
11
12
13
6
7
8
9
10
11
12
13
1
/
13
100%