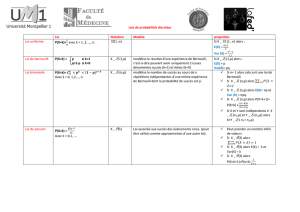
DEUX ANS DE PARIS AVEC UNE VARIABLE ALEATOIRE ETONNANTE

1
DEUX ANS DE PARIS AVEC UNE VARIABLE ALEATOIRE ETONNANTE
J F Kentzel – Enseignant au lycée Pardailhan à Auch (32) - jkentzel@ac-toulouse.fr
PARTIE A
Soit
n
un entier valant au moins 1. On réalise
n
expériences de Bernoulli identiques et indépendantes
dont les issues sont désignées par succès, de probabilité
p
,
10 p
, et échec.
On désigne par
)(p
n
L
la (célèbre( ?)) variable aléatoire : « longueur de « la » plus longue suite de
succès consécutifs obtenue à l’issue de la
n
ième expérience ».
PREAMBULE : QUELQUES NOTATIONS ET UNE FORMULE INDISPENSABLES
Pour tout
n
fixé, la loi de
)(p
n
L
peut être obtenue, mais pas explicitement !, grâce à la formule de
récurrence qui va suivre.
La question posée est : calculer
kLP p
n
)(
pour tout entier
k
entre 0 et
n
.
Le calcul simple
0
)(
p
n
LP
est à part :
np
npLP )1(0
)(
. Soit
k
un entier fixé,
1k
.
Pour tout entier
n
valant au moins 1, soit
)(k
n
s
)()( kp
n
s
la probabilité de l’événement {
kL p
n
)(
}.
La suite
n
k
n
s)( )(
est définie par ses
)1( k
valeurs initiales faciles à vérifier :
si
11 kn
,
0
)(
k
n
s
(cas évidemment exclu si
1k
) ;
kk
kps
)(
;
1)( 1)1(2
kkk
kppps
;
et par la relation de récurrence valable si
2 kn
:
)( 1
)( 1
)( 1)1( kkn
kk
n
k
nsppss
, plus lisible sous
la forme :
11 1)1( kn
k
nn sppss
.
C’est cette relation qui est essentielle. Voici le principe de sa preuve : soit on avait déjà une suite de
k
succès consécutifs à l’issue de la
)1( n
ème expérience, soit, en notant 1 pour le succès et 0 pour
l’échec, une telle suite apparaît pour la première fois à la
n
ème expérience sous la forme
(….
foisk
11...111110
).
Autrement dit, en désignant par
1
X
,
2
X
,…
n
X
les résultats (valant 0 ou 1) des expériences
successives, l’événement
kLn
est la réunion disjointe de
kLn
1
et de l’intersection
d’événements indépendants :
1...0 111 nnknknkn XXXXkL
.
A l’aide d’un tableur on a facilement représenté ci-contre
chacune des suites
501
)( )( n
k
n
s
pour
k
entre 2 et 10 dans le
cas
2/1p
.
Ces suites
n
k
n
s1
)( )(
sont (strictement) croissantes et
convergent vers 1.
Si
1k
,
kLP p
n
)(
)1()(
k
n
k
nss
car {
1
)( kL p
n
}
{
kL p
n
)(
}.
Par ailleurs
)1()( 1)1(0 n
np
nspLP
.
Pour simplifier les calculs on utilisera dans ce qui suit la suite définie par
)()( kp
n
q
)()( 1k
n
k
nsq
.
)(k
n
q
)()( kp
n
q
)( )( kLP p
n
vérifie si
2 kn
:
)( 1
)( 1
)( )1( kkn
kk
n
k
nqppqq
.
Si
1k
,
kLP p
n
)(
)()1( k
n
k
nqq
(et
)1()( )1(0 n
np
nqpLP
).
(un lapsus, expression « 1- » mal placée, a été modifié aux lignes 1 et 4 en partant de la fin )

2
a ) RÉSULTATS CONSÉCUTIFS IDENTIQUES DANS LE CAS OÙ
2
1
p
Soit
'
2
1
n
L
'
n
L
la variable aléatoire : longueur de «la» plus longue suite de résultats consécutifs
identiques obtenue à l’issue du
n
-ème lancer d’une pièce équilibrée.
Pour tout entier
1k
fixé, en notant
)(k
n
p
pour
)'( kLP n
, on prouve facilement que la suite
)(k
p
=
1
)( )( n
k
n
p
est définie par :
les valeurs initiales : si
1 kn
,
0
)(
k
n
p
;
1
)( 21
k
k
k
p
;
et la relation de récurrence: si
1 kn
,
)()( 1
)( 1
2
1kkn
k
k
n
k
nppp
.
Pour prouver cette relation, le raisonnement de la page précédente doit être un peu modifié. On
avait :
A
{ une suite de
k
succès consécutifs apparaît au
n
ième lancer } signifie :
(… « Rien »….
foisk
11...111110
) où le 0 est à la
ème
kn )(
place et où « Rien » signifie
kL kn
1
.
On avait donc
A
1...0 111 nnknknkn XXXXkL
,
est l’intersection de trois événements indépendants :
Ici, on s’intéresse à des résultats consécutifs identiques et « Rien »….0 peut donc ne pas être
« Rien ». Il faut donc « inclure le 0 dans ce « Rien » ». On a donc :
B
{ une suite de
k
résultats consécutifs identiques apparaît au
n
ième lancer }
contient l’intersection de trois événements non indépendants :
1...]0[ 11 nnknknkn XXXXkL
dont la probabilité est
k
knkn pXkLP ]0[
, qu’il faut bien sûr réunir, pour calculer
)(BP
, avec
0...]1[ 11 nnknknkn XXXXkL
dont la probabilité est
k
knkn pXkLP )1(]0[
. C’est ennuyeux si
pp 1
mais ici
pp 1
donc
k
knkn pXkLP ]0[
+
k
knkn pXkLP )1(]1[
=
k
kn kLP 2
1
.
.
On va voir plus loin (étape 6) que pour tous
n
et
k
,
)( 2
1kLP n
)1'( 1
kLP n
.
Pour une pièce bien équilibrée (
2/1p
), les lois de
'
n
L
et
2
1
n
L
sont définies par des suites
identiques à « un double décalage près ». Le présent paragraphe n’est donc pas hors-sujet. Il
n’est, à un double décalage près, que l’étude du cas particulier
2/1p
.
La représentation des suites
n
k
n
p1
)( )(
est du type vu à la page précédente : (strictement) croissantes
et convergentes vers 1.
.
)'( kLP n
)'( kLP n
)1'( kLP n
. On peut donc, par soustraction de colonnes si on a un
tableur, obtenir une représentation des suites
nn kLP )'(
.
C’est fait ci-dessous pour
2001 n
avec encore
k
entre 2 et 10.

3
Un résultat annoncé en 1978 est
965,0)6'( 200 LP
. On peut en déduire des activités à mener
en classe…(voir à la fin)
'
n
L
prend toutes les valeurs
k
entre 1 et
n
et on s’intéresse à
n
u
: Maximum sur
k
des
kLP n'
,
c’est à dire : la probabilité de la plus longue suite la plus probable en effectuant
n
lancers. Cette suite
)( n
u
est représentée ci-dessous sur deux intervalles différents.
On observe avec un tableur que l’ « arche » correspondant à « la plus longue suite la plus probable est
de longueur
k
» est obtenue, approximativement, pour
n
dans l’intervalle
1
2;2 kk
, autrement dit :
si
1
2;2
kk
n
, c'est-à-dire
21)(2 LnknLnLnk
, la valeur la plus probable de
'
n
L
est
2Ln nLn
Ent
.
Sur le dessin ci-dessus, on voit intervenir les valeurs 15, 31, 61…On va voir que « la » formule
donnant les abscisses des « pieds des arches » n’est pas
k
x2
mais est plutôt
)2.( k
CEntx
avec
96,0C
. Les feuilles de tableur sont sur le site [1].
Question : que se passe -t-il si
n
grandit ? Est-ce que le Maximum tend vers 0 ?
Deux réponses « oui » avec d’autres fonctions :
Maximum sur k des P ( { L_n = k } )
0,22
0,23
0,24
0,25
0,26
0,27
0,28
0,29
Nombre de lancers = n : 29 < n < 431
43030 n
: les quatre « arches » visibles
correspondent à
k
valant 5, 6 , 7 et 8.
Maximum sur k de s P ( { L_n = k } )
0,23
0,24
0,25
0,26
0,27
N o mb re d e lan cers = n : 30 < n < 3501
350030 n
: les quatre « arches » les plus à
droite correspondent à
k
valant 8, 9, 10 et 11.
0
0 ,1
0 ,2
0 ,3
0 ,4
0 ,5
0 ,6
116 31 46 61 76 91 106 121 1 3 6 151 166 181 196
N o m b re d e la n c e rs = n < 2 0 0
P ( L _ n = k )
k = 2
k = 3
k = 4
k = 5
k = 6
k = 7
k = 8
k = 9
k = 1 0

4
C’est une représentation graphique de
f
définie par
1,0
4,0
2
3,0
2
2cos
xLn
xLn
x
xf
.
Si
n
X
suit la loi binomiale
pnB ;
,
0
0
lim
kXP
nk
Max
nn
.
Il existe une formule exacte et explicite de la loi de
n
L
, provenant des formules de récurrence
définissant les suites (récurrentes et presque linéaires)
n
k
n
p)( )(
, par exemple pour tout
1n
1)2( 2/11
n
n
p
et
nn
n
p
451
.
555
451
.
555
1
)3(
, mais elle n’est que
théorique et semble a priori inutilisable à cause de la difficulté de la résolution de l’équation
caractéristique
0
2
1
1
k
kk xx
dès que
k
dépasse 5 (
2/1x
est toujours une solution).
On a aussi d’autres formules exactes (voir à la fin de ce paragraphe) mais elles sont peu pratiques et on
se contente de calculs approchés…
Etape 1 COMPTAGES APPROXIMATIFS DE TERMES DE
)(k
n
p
Notation :
k
étant un entier fixé valant au moins 2, pour tout
a
vérifiant
10 a
, on désigne par
)(agk
le plus petit entier
n
vérifiant
ap k
n
)(
.
Si
ap k
n
)(
,
)(agk
est le nombre de termes de (
)(k
n
p
) situés dans
a;0
.
Si
ap k
n
)(
,
)(agk
est ce nombre de termes augmenté de 1.
La méthode utilisée est très rudimentaire (et du coup la preuve obtenue est longue) : couper
l’intervalle [0 ;1[ en
A
intervalles de même longueur et encadrer le nombre de termes de (
)(k
n
p
) dans
chacun de ces intervalles.
On choisit évidemment l’entier
A
assez grand pour avoir une précision correcte, mais aussi assez petit
pour avoir au moins
k
termes de la suite (
)(k
n
p
) dans l’intervalle
A
r
A
r1
;
pour tout entier
r
tel que
Ar
(c’est vrai si on prend
k
Ak
2
).
Ceci permet d’encadrer le nombre de termes de cette suite (
)(k
n
p
) qui sont situés dans
A
r
A
r1
;
, on
obtient avec quelques calculs :
1
1
21
1
1
2
rAA
r
g
A
r
g
rA
k
kk
k
.

5
Ensuite, en sommant cette inégalité pour tout
r
entre 0 et
1s
, on encadre le nombre de termes de la
suite (
)(k
n
p
) qui sont situés dans
A
s
;0
et on obtient facilement :
k
étant un entier fixé valant au moins 2, pour tous entiers
A
et
s
vérifiant
k
As k
2
0
, on a
l’encadrement :
1
1
1
ln.21
2
2
ln.2
s
sAA
A
s
gs
sAAk
k
k
(1)
Il est mauvais mais dans les cas qui nous intéressent il concerne des grands nombres et il va suffire !
Etape 2 : UNE FORMULE D’APPROXIMATION DE
)(k
n
p
En prenant la demi-somme des bornes de (1) et en la simplifiant un peu, on obtient une valeur
approchée de
A
s
gk
:
sA
A
A
s
gk
kln.2
. On a alors une relation « inversible ».
On peut en déduire une expression approchée de
n
p
: pour
A
s
sAA
nkk
1
1
ln.2ln.2
, alors
A
s
pk
n
)(
, c’est à dire que
)
2
(exp
11)( kk
n
n
p
, soit :
k
n
k
nep 2
)( 1
.
Ainsi, avec
k
c
définie par
k
x
kexc 2
1:
,
)(nck
est une « bonne approximation » de
)(k
n
p
.
De même, avec
)()(: 1xcxcxd kkk
,
)(ndk
=
kk nn ee 22 1
est une (bonne) approximation de
)(k
n
p
)1(
k
n
p
=
.' kLP n
Ce sont ces fonctions
k
c
et
k
d
qui sont utilisées dans tous les dessins qui suivent.
Le mot « approximation » sera précisé !
Etape 3 : CONSEQUENCES DE CETTE FORMULE D’APPROXIMATION
Sur les deux dessins qui suivent,
'
n
L
est noté
n
L
.
On peut résoudre, pour tout
k
, l’équation, d’inconnue
x
,
)()( 1xdxd kk
, c'est-à-dire avoir une
valeur approchée des abscisses des « pieds des arches ».
En posant
1
2
k
x
eX
, on obtient l’équation
422 XXXX
puis
01
2 XX
d’où
1
2.
215 k
kLnxx
kkk CLn 2.962,02.2.
15
21
en désignant par
C
le nombre
))15/(2(.2 Ln
qui vaut environ 0,962.
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
6
7
8
9
10
11
12
13
14
15
16
17
18
19
1
/
19
100%