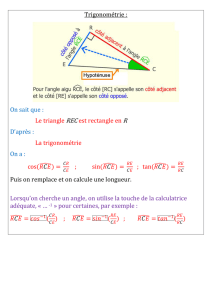
Sur lnestimation des paramètres de la loi Lévy$stable

République Algérienne Démocratique et Populaire
Ministère de l’Enseignement Supérieur et de la Recherche Scienti…que
UNIVERSITÉ MOHAMED KHIDER, BISKRA
FACULTÉ DES SCIENCES EXACTES ET SCIENCES DE LA NATURE
ET LA VIE
DÉPARTEMENT DE MATHÉMATIQUES
Mémoire Présenté En Vue De L’obtention Du
DIPLÔME DE MAGISTER
EN MATHEMATIQUES
Option : Analyse et Modélisation Aléatoire
Par
Nassima BERROUIS
Titre
Sur l’estimation des paramètres de la loi Lévy-stable
Membres du comité d’examination
Abdelhakim NECIR Professeur UMKB Président
Djamel MERAGHNI MCA UMKB Rapporteur
Brahim MEZERDI Professeur UMKB Examinateur
Boubakeur LABED MCA UMKB Examinateur
Juin 2012

Dédicace
A mes parents,
A mes frères et soeurs,
A tous ceux qui me sont chers.
i

Remerciements
Au nom de DIEU Le Plus Clément et Le Plus Miséricordieux.
Je tiens a témoigner publiquement au Docteur Mr Djamel MERAGHNI, nom Di-
recteur de mémoire, toute la raiconnaissance que je lui dois. Ce dernier a suscité,
développé puis accompagné mes premiers pas dans la domaine de statistique avec une
grande patience et avec une pédagogie extraordinaire. Sincérement Merci.
Je suis très honoré que les professeurs : Abdelhakim NECIR et Brahim MEZERDI
et le docteur Boubakeur LABEDaient accepté de rapporter cette mémoire. Je leur suis
reconnaissant pour l’intérêt qu’ils ont accordé à mon travail, d’avoir apporté de très
judicieuses remarques et de m’avoir aidé à améliorer la qualité de la présentation.
Je tiens aussi à remercier tout mes amis et mes collègues.qui ont partagé avec moi
leur contexte humain.
En…n, je me permets également de remercier toute ma famille qui a supporté toutes
les di¢ cultés pour me soutenir tout au long de mes études.
ii

Table des matières
Dédicace i
Remerciements ii
Table des matières iii
Liste des …gures v
Liste des tableaux vii
Introduction 1
1 Lois stables 3
1.1 Historique.................................. 3
1.2 Variable aléatoire stables........................ 5
1.3 Lois indé…niment divisibles . . . . . . . . . . . . . . . . . . . . . . . . . 5
1.4 Dé…nitions equivalentes . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.5 Interprétation des paramètres . . . . . . . . . . . . . . . . . . . . . . . 10
1.6 Propriétés diverses . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
1.6.1 Densité ............................... 13
1.6.2 Stabilité............................... 17
1.6.3 Comportement Queues lourdes . . . . . . . . . . . . . . . . . . 17
1.6.4 Calcul des moments . . . . . . . . . . . . . . . . . . . . . . . . . 19
1.6.5 Propriétés algébriques . . . . . . . . . . . . . . . . . . . . . . . 21
1.7 Représentation en série de Lepage d’une variable aléatoire stable . . 23
1.8 Générateur de variables aléatoires stables . . . . . . . . . . . . . . . . . 25
1.8.1 Algorithme de Chambers, Mallows et Stuck . . . . . . . . . . . 25
1.8.2 L’algorithme de Weron et Weron . . . . . . . . . . . . . . . . . 30
1.9 Statistique sur les Lois Stables . . . . . . . . . . . . . . . . . . . . . . . 30
2 Estimation des paramètres stables 32
2.1 Estimation du maximum de vraisemblance . . . . . . . . . . . . . . . . 32
2.2 Méthode de recuit simulée par chaine de Markov de Monte Carlo . . . 33
2.3 Méthode basées sur les quantiles . . . . . . . . . . . . . . . . . . . . . . 35
iii

Table des matières
2.3.1 Méthode de Fama et Roll . . . . . . . . . . . . . . . . . . . . . 35
2.3.2 Méthode de McCulloch . . . . . . . . . . . . . . . . . . . . . . . 36
2.3.3 Méthode de L-Moments . . . . . . . . . . . . . . . . . . . . . . 39
2.4 Méthode basées sur la fonction caractéristique . . . . . . . . . . . . . . 45
2.4.1 Méthodes de minimum de distance . . . . . . . . . . . . . . . . 45
2.4.2 Méthode des moments . . . . . . . . . . . . . . . . . . . . . . . 46
2.4.3 Méthode basée sur la régression . . . . . . . . . . . . . . . . . . 48
2.4.4 Méthode de Régression Itérative . . . . . . . . . . . . . . . . . . 50
2.5 Méthode de Régression de Queue . . . . . . . . . . . . . . . . . . . . . 51
2.6 Méthodes basées sur la théorie des valeurs extrêmes . . . . . . . . . . . 51
2.6.1 Estimateur de Hill . . . . . . . . . . . . . . . . . . . . . . . . . 53
2.6.2 L’estimation de .......................... 56
2.6.3 L’estimation de .......................... 57
3 Modélisation des données …nancières 59
3.1 Les indices boursiers . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
3.2 Tauxdechange............................... 60
3.3 Ajustement stable contre ajustement normal . . . . . . . . . . . . . . . 61
Conclusion 74
Bibliographie 76
Annexe : Abréviations et Notations 80
iv
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
1
/
90
100%