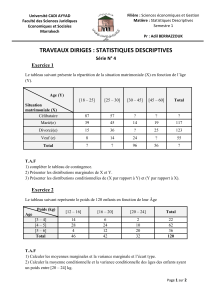
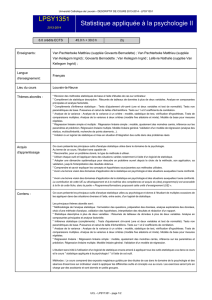
Télécharger - Annales partiels ENSTBB

Statistiques appliquées
Les statistiques permettent de dégager les significations des données. Il faut :
Décrire les données (graphe, moyenne…)
Faire un test statistique adapté
Interpréter et discuter
Il existe deux sortes de variables : quantitatives (rendement, poids, taille…) et qualitative (sexe, variété…). La variable
peut prendre différentes modalités (valeurs).
Variable quantitative :
Indicateur utiles : moyenne (mean), écart-type (sd), coefficient de variation (CV). Il est possible d’analyser une
variable en formant des modalités (i.e. des groupes).
Graph des moyennes : donne les moyennes de deux modalités. Barres d’erreurs sont soit écart type, soit un
intervalle de confiance (si 95%, alors 95% des échantillons auront une moyenne comprise dans cet
intervalle). Si les barres d’erreur de l’IC ne se chevauchent pas, les modalités sont significativement
différentes.
Boite à moustache / boxplot : montre la répartition des valeurs de la variable en quartiles. On a max et mini.
Histogramme : représentation graphique des valeurs de la variable.
Centrage et réduction :
Transforme une variable pour donner une moyenne nulle et un écart type de 1. Permet de normaliser les données et
de s’affranchir d’un effet d’échelle. Par exemple, pour une dégustation de vin on va normaliser les notes données
par chaque membre du jury.
On peut obtenir de variables centrées réduites mais on peut aussi :
Pondérer par rapport à une mesure (choisi une référence)
Pondérer par la somme totale des mesures
Pondérer une valeur par ce qui la produit (métabolite pondérer par rapport à la qté de son précurseur)
La notation des descripteurs :
Population
Echantillon
Effectif
N
Effectif
n
Moyenne arithmétique
µ
Estimateur de la moyenne
𝑥̅
Variance
σ²
Estimateur de la variance
S²
Ecart-type
σ
Estimateur de l’écart-type
S
Choisir le test :
Données qualitatives : Tests d’effectifs de khi²
Variables quantitatives considérées en même temps :
Une : analyse univariée
Deux : analyse bivariée i.e. corrélation
Plus : analyse multivariée
Bilatéral ou unilatéral :
Dans le doute prendre bilatéral
Unilatéral si on est certain du sens de la différence avant la collecte de résultats (ex : dépollution)

Les deux familles de tests :
Statistiques paramétriques : suit une loi de distribution (loi normale…)
Statistiques non-paramétriques : aucune hypothèse de distribution
Tests non-paramétriques :
Utilise les groupes pour
déterminer qui est différent
H0 est : la différence est significative.
Soit la p-value la probabilité de commettre une erreur de
première espèce (rejeter à tort). Si la p-value est inférieure à
α (souvent 5%) les différences sont significative.
One puissance de 90% (β = 10%) signifie qu’on donne 90
chances sur 100 de mettre en évidence une différence.
Bilan sur les tests non-paramétriques :
Pas d’exigence sur les distributions/variances.
Pas possible d’analyser 2 facteurs et leurs interactions.
Tests paramétriques :
Il y a des conditions à vérifier avant et après le test !!
Généralement si la répartition suit une loi normale et
l’homogénéité des variances (homoscédasticité).
Il ne faut pas que la variance augmente avec les valeurs des
variables.

ANOVA : tests sur les résidus à
faire après l’ANOVA.
Adjusted R-squared donne la part de variance expliquée par le modèle.
Pour tester la normalité des résidus, le diagramme quantile-quantile (Q-Q plot)
donne une représentation de ce que devrait suivre les points.
Pour le test ANOVA, on fait un test de comparaison multiple. On obtient les
intervalles de confiances : si cet intervalle contient 0, ce n’est pas significatif.
Sinon on utilise les classes de tukey qui utilise les groupes.
ANOVA a deux facteurs : on effectue un test de Leven en prenant les deux
facteurs. On peut en déduire différentes interactions grâce au graph des
effets.
Transformation des données :
Si les résidus ne suivent pas une loi normale on peut essayer de transformer les données (log, inverse, carré…).
Les corrélations :
La corrélation permet de quantifier la liaison mathématique entre deux variables quantitatives. On visualise les
données grâce à un graph nuage de points.
Il existe 3 tests de corrélation :
Pearson (paramétrique, vérifier la normalité de chaque variable avant)
Spearman (non-paramétrique) à préférer
Kendall (non-paramétrique)
On obtient un coefficient de corrélation qui varie entre -1 et 1.
Quand on a plusieurs variables on peut faire une matrice de corrélation pour voir qui est corrélé avec qui. Il faut
prendre en compte l’effet « tests multiples ». On utilise la corrélation de Holms par défaut.

Les analyses multivariées :
On s’intéresse à la distribution conjointe de plusieurs variables. Sous Rcmdr on
fait des ACP. C’est une méthode descriptive qui représente sous forme
graphique l’essentiel de l’information contenue dans un tableau de données
quantitatives. Fournit des plans factoriels qui déforment la réalité.
On a le % de variance expliqué par les deux axes et on peut voir se former des
groupes.
Il est aussi possible de faire de la classification hiérarchique (arbre
phylogénétique).
On peut également faire un Manova : il faut que les groupes suivent une loi normale, homoscédasticité des groupes
pour chaque variable, l’homogénéité des covariances et des échantillons assez larges : 20 individus/groupes.
Le heatmap, souvent associé un clustering hiérarchique, permet de
visualmiser chaque variable dans chaque modalités (ex : différentes
protéines dans différents individus).
Tests d’effectifs de données qualitatives :
Distribution suivant une loi : test de conformité à une loi
Distribution ne suivant pas une loi particulière : test khi²
Test de conformité, par exemple test de triangulation : 3 échantillons dont 1 différents des 2 autres. Par hasard on
s’attend à ce que 1/3 des participants désignent le produit différent. On test significativité avec une loi binomiale.
Test khi² doit remplir plusieurs critères. Chaque classe doit avoir une valeur théorique non nulle, 80% des classes
doivent avoir une valeur théorique supérieure ou égale à 5.
La régression :
Il y a plusieurs types de régression :
Régression linéaire : 𝐲 = 𝐚𝐱 + 𝐛
Régression linéaire multiple : 𝐲 = 𝐚𝟏𝐱𝟏+ 𝐚𝟐𝐱𝟐
Régression polynomiale : 𝐲 = 𝐚𝟏𝐱𝟏
𝟑+ 𝐚𝟐𝐱𝟐
𝟐+ 𝐚𝟑𝐱𝟑
Et bien plus…
La régression permet de quantifier la force d’une relation. Cela permet également de faire de l’analyse de prédiction.
Il existe différentes méthodes, donc la méthode des moindres carrés, moindres carrés partiels, le maximum de
vraisemblance... Ces méthodes diffèrent sur leur algorithme, leur sensibilité et les hypothèses vérifiées.
On fait une régression linéaire sur les deux variables. On obtient une équation. Pour que le modèle soit valide, il faut
que les résidus se répartissent de façon aléatoire autour de zéro. Si ce n’est pas le cas, il est possible de transformer
les données.
Régression linéaire multiple :
Quels sont les facteurs corrélés à la grandeur étudiée ? On fait une matrice de nuage de points pour visualiser les
effets. On fait ensuite une régression linéaire multiple et on obtient les différents coefficients en fonction des
facteurs, ainsi que leur significativité. Si la P-value est supérieure à 5% il n’est pas utile de mettre le facteur dans
l’équation. On va ainsi cherche le modèle le plus représentatif de la réalité, en éliminant les facteurs non
significativement corrélés.

Cas des données cinétiques :
Il faut transformer les données en paramètres d’intérêts (par exemple absorbance maximale). On va soit ajuster soit
lisser les cinétiques étudier sur un modèle pour obtenir ces paramètres.
Fitting versus smoothing :
Le lissage (smoothing) va réduire la distance entre les points successifs pour
lisser la courbe. La force du lissage dépend de l’expérimentateur. Il ne faut
pas que le lissage soit trop fort pour coller aux données.
L’ajustement sur modèle (fitting) nécessite un modèle qui colle aux courbes. Si le modèle est bon, l’ajustement peut
être pertinent même sur un nombre de valeurs limité. Il est possible d’ajuster des modèles par portions (morceaux).
La variabilité :
Les plans d’expériences cherchent à minimiser la variabilité non contrôlée (bruit de fond). C’est un phénomène
naturel qui ne peut être supprimé, mais il faut le prendre en compte pour seulement considérer la variabilité liée aux
facteurs qui nous intéressent.
Une mesure peut être juste et/ou répétable. Si elle est répétable elle fournit des résultats similaires dans des
conditions précises. Une méthode est reproductible si elle fournit des résultats similaires dans plusieurs conditions
opératoires. On peut parler de mesures directes ou indirectes.
Le plan d’expérience :
Les effets de bords/de position :
La température n’est pas homogène partout, la croissance dépend
plus de la position que de ce qui est dans le puit.
Les effets blocs aléatoires
Si on a une expérience qui demande deux plaques, une entière
pour un milieu et la deuxième pour un autre milieu, il ne faut pas
faire un milieu par plaque. Il faut randomiser.
Les effets blocs avec dérive
Lorsqu’une expérience demande des répétitions qui se font dans la durée, il peut y avoir une dérive à cause d’un
antibiotique qui se dégrade au cours du temps et donc les souches poussent mieux, ou alors des différences
d’humidité ou de température en fonction du jour de manipulation…
Il existe des méthodes de correction s’il y a une dérive. L’effet bloc peut être pris en compte par l’ANOVA pour ne
pas être confondu avec un facteur d’intérêt.
Il faut qu’il y ait une adéquation entre le plan qui est proposé et la méthode utilisé. Sinon, on peut avoir une
méthode qui est efficace mais ne jamais trouver de résultats significatifs. Il faut aussi choisir le nombre de
répétitions qui est utile. Pas la peine d’en faire trop si ce n’est pas nécessaire.
Plan factoriel complet et explosion combinatoire :
On veut tester l’impact de 17 composés sur la croissance d’une levure. Si on veut prendre trois valeurs par composé,
il faut faire 129 140 163 essais : explosion combinatoire. Il existe des méthodes pour réduire le nombre d’essais :
Matrices de Hadamard : plan d’expériences sans interactions, 2 modalités par facteur.
Plan factoriel 2k fractionnaire : k facteurs étudiés avec 2 modalités, interactions calculées.
Plans de Tagushi : 2 modalités mais sans les interactions.
 6
6
1
/
6
100%