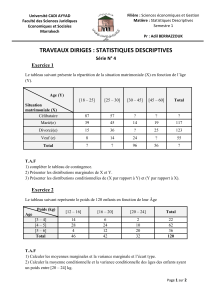
Statistiques - Ajustement de courbes

Statistiques - Ajustement de courbes
1 Rappels de Statistiques
1.1 Moyenne, variance, écart-type
Soit une série statistique : x1, x2,···xn(nvaleurs)
Moyenne
¯x=1
n
n
X
i=1
xi
Somme des carrés des écarts à la moyenne (sum of squares, SS)
SS =
n
X
i=1
(xi−¯x)2
Nombre de degrés de liberté (ddl)
ddl = nombre total de valeurs - nombre de valeurs estimées
Pour la somme précédente, on a estimé la moyenne, donc ddl = n- 1
Variance (estimée)
Var(x) = SS
ddl =1
n−1
n
X
i=1
(xi−¯x)2
Ecart-type
σ(x) = qVar(x)
1

Figure 1 – Histogramme et densité de probabilité
1.2 Histogramme
Si l’on dispose d’un grand nombre de valeurs on peut les regrouper en
classes.
Pour chaque classe ]xi, xi+1], on définit :
– l’effectif ni(nombre de valeurs dans la classe)
– l’amplitude ai=xi+1 −xi
– la fréquence fi=ni/N (N = effectif total)
– la densité de fréquence di=fi/ai
L’histogramme peut être tracé en portant la densité de fréquence en fonc-
tion des limites de classes (Fig. 1). Dans ces conditions :
– la surface de chaque barre est proportionnelle à la fréquence
– l’unité des ordonnées est l’inverse de celle des abscisses
– l’histogramme peut être approché par une courbe continue (densité de
probabilité)
2

1.3 Lois de probabilités
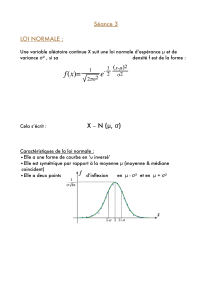
1.3.1 Loi normale (courbe de Gauss)
Caractérisée par sa moyenne µet son écart-type σ:N(µ, σ).
La densité de probabilité est donnée par :
f(x) = 1
σ√2πexp "−1
2x−µ
σ2#
La probabilité pour que la variable xsoit comprise entre deux valeurs a
et best donnée par l’intégrale (aire sous la courbe) :
Prob(a<x<b) = Zb
af(x)dx
Exemples :
Prob(µ−2σ < x < µ + 2σ)≈0,95
Prob(µ−3σ < x < µ + 3σ)≈0,99
La probabilité totale est égale à 1 :
Prob(−∞ <x<+∞) = 1
Cas particulier : loi normale réduite : N(0,1) (Fig. 1)
1.3.2 Loi de Student
Dépend du nombre de degrés de liberté (ddl)
La courbe ressemble à celle de la loi normale mais d’autant plus élargie
que le ddl est faible (Fig. 2)
Pour ddl ≥30 on retrouve pratiquement la loi normale réduite.
1.3.3 Loi de Fisher-Snedecor
Correspond à la distribution d’un rapport de variances.
Caractérisée par deux ddl
La courbe est bornée à 0 et n’est pas symétrique (Fig. 3)
3

Figure 2 – Loi de Student : ddl = 30 (trait plein), 5 (tirets), 2 (pointillés)
-6 -3 0 3 6
x
0
0.1
0.2
0.3
0.4
f(x)
Figure 3 – Loi de Fisher-Snedecor : ddl1= 10, ddl2= 5
0 2 4 6
x
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
f(x)
4

2 Régression linéaire
2.1 Ajustement d’une droite
Le problème consiste à déterminer l’équation de la droite qui passe le plus
près possible d’un ensemble de points.
Le modèle est défini par l’équation :
y=β0+β1x
–xest la variable indépendante (ou « explicative »), supposée connue
sans erreur
–yest la variable dépendante (ou « expliquée »), entachée d’une erreur
de mesure σ
–β0et β1sont les paramètres du modèle (valeurs théoriques)
Supposons que les npoints (x1, y1),(x2, y2),···(xn, yn)soient parfaite-
ment alignés (Fig. 1A), de sorte que chacun d’eux vérifie l’équation de la
droite :
y1=β0+β1x1
y2=β0+β1x2
··· ··· ·········
yn=β0+β1xn
ou, sous forme matricielle :
y=Xβ
avec :
y=
y1
y2
···
yn
X=
1x1
1x2
··· ···
1xn
β="β0
β1#
5
 6
7
8
9
10
11
12
13
14
6
7
8
9
10
11
12
13
14
1
/
14
100%