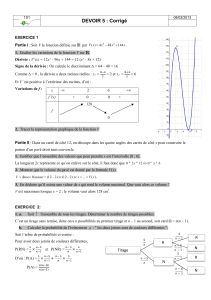
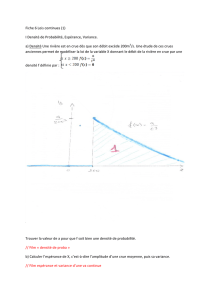
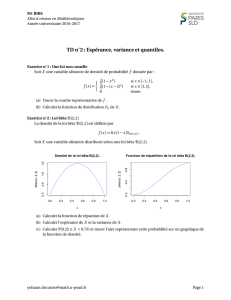
aléatoire probabilité -mesurée -partie -simulation alors

Résumé de notions de mathématiques
(Basé sur Wikipédia)
(traduit par Maurice Genoud)
1. Fonctions réelles et complexes de deux ou plusieurs variables
Une fonction est une relation binaire f qui associe à tout élément x de
l’ensemble de départ une et une seule image y.
f(x) = y
La notion de fonction peut être étendue à une application qui associe une et
une seule image y à une combinaison de deux (ou plus) variables.
f(x1,x2) = y
Exemple : f(x1, x2) = x1·x2 = y
Nous allons souvent rencontrer des fonctions réelles ou complexes à N
variables de la forme suivante : Ψ(r1,r2,r3,…,rN).
2. Théorie probabilistes : Distributions de probabilité et statistiques
La probabilité d'une variable aléatoire x (p.e. le numéro obtenu lors du lancer
d’un dé) est donnée par le quotient du nombre N(x) de réalisations de
l’évènement x par rapport au nombre total d’évènement Ntot.
()
tot
N
xN
xP )(
=
P(x) est appelé densité de probabilité de x. La probabilité que x soit dans un
intervalle entre a et b (a <x ≤ b) est donnée par la fonction de densité de
probabilité (ou distribution de probabilité).
∫
=
≤≤ b
a
bxa dxxPP )(
P(x) est toujours supérieure ou égale à zéro pour toutes les valeurs de x et la
probabilité totale est 1.
1)( == ∫
+∞
∞−
dxxPPtot
Une distribution est discrète si la variable aléatoire x peut seulement prendre
des valeurs discrètes. Si x peut prendre toutes les valeurs dans un intervalle
donné, la distribution est continue.

Exemple de distribution discrète : un dé à jouer
Variables aléatoires possibles: x1 = 1, x2 = 2, x3 = 3, x4 = 4, x5 = 5, x6 = 6
Probabilités associées : P(x1) = P(x2) = P(x3) = P(x4) = P(x5) = P(x6) = 1/6
Exemple de distribution continue : désintégration radioactive exponentielle
(discuté au chapitre 2.5.3) :
kt
e
N
tN −
=
0
)(
(Notez que dans ce cas nous avons approximé une distribution discrète
comprenant une grande quantité d’évènements par une distribution continue.)
Certaines propriétés de la distribution de probabilité sont particulièrement
importantes pour nous. Par exemple, l’espérance (aussi appelée premier
moment, ou moyenne) et la variance (deuxième moment).
L’espérance E(x) d'une variable aléatoire x est définie comme :
∫
+∞
∞−
=dxxxPxE )()(
Si x est une variable aléatoire discrète avec les valeurs x1, x2, ... et les
probabilités correspondantes p1, p2, ... dont la somme vaut 1, alors
l’espérance est la somme suivante :
∑
=iii xpxE )(
L’espérance d'une fonction arbitraire g(x) avec comme densité de probabilité
P(x) est donnée par :
∫
+∞
∞−
=dxxPxgxgE )()())((
La variance d'une variable aléatoire (ou d'une distribution de probabilité) est
une mesure de la dispersion de ses statistiques, indiquant la manière dont
ses valeurs possibles sont réparties autour de l’espérance. La racine carrée
de la variance, appelée écart-type, donne une indication de l’écart possible. Si
E(x) = μ est l’espérance de la variable aléatoire x, alors la variance est :
))(()var( 2
μ
−= xEx
∫
+∞
∞−
−= dxxPxx )()()var( 2
μ
C'est la moyenne du carré de l'écart entre x et sa propre espérance. Cela
signifie que la variance mesure la moyenne du carré de la distance de chaque

point de statistique à la moyenne de la variable aléatoire. On appelle cela
l'écart quadratique moyen.
Nous utiliserons aussi souvent la probabilité conjointe d'un événement A avec
une probabilité P(A) et d’un évènement B avec probabilité P(B). Si les deux
événements A et B sont indépendants, la probabilité conjointe P(A∩B) est
P(A∩B) = P(A)·P(B).
3. Fonctions trigonométriques
Les fonctions trigonométriques sont définies pour un triangle rectangle tel
que représenté ci-dessous (γ = 90◦). On a alors:
sin(α) = a/c; sin(β) =b/c
cos(α) = b/c; cos(β) = a/c
tan(
α
) = a/b; tan(β) = b/a
I.e. le sinus d’un angle est
définit comme le rapport entre
le coté oppose à l’angle et
l’hypoténuse. Le cosinus
d’un angle est définit comme
le rapport entre le coté
adjacent (mais pas
l’hypoténuse) à l’angle et
l’hypoténuse. La tangente
d’un angle est définie comme
le rapport entre le coté
opposé et le coté adjacent
(mais pas l’hypoténuse) à cet
angle.
Moyen mnémotechnique: SinOpHyp, CosAdHyp, TangOpAd
Les fonctions réciproques de ces fonctions sont appelées respectivement
arcsinus, arccosinus et arctangente. Les relations arithmétiques entre ces
fonctions sont connues sous le nom d’identités trigonométriques.
Avec ces fonctions, on peut répondre potentiellement à toutes les questions
sur des triangles arbitraires (pas forcément rectangles) en utilisant la loi des
sinus et la loi du cosinus.
4. Différentiation and intégration
Une dérivée est définie comme la variation instantanée d’une fonction. Le
processus de recherche de la dérivée est appelée différenciation ou
γ
α
β
a
b
c

dérivation. Le processus inverse est l'intégration. Pour les fonctions réelles à
une seule variable, la dérivée en un point donne la pente de la tangente à la
courbe représentative de la fonction en ce point.
La dérivée d’une fonction f(x) peut être construite via des sécantes :
La sécante à la courbe y= f(x) est déterminée par les points (x, f(x)) et (x+h,
f(x+h)). La pente de la droite passant par ces deux points est :
h
xfhxf )()( −+
La dérivée de f en x est la limite de la valeur de ce quotient lorsque l’écart h
entre les deux abscisses tend vers zéro :
h
xfhxf
xf h)()(
lim)(' 0
−+
=→
Le concept de dérivation peut être étendu aux fonctions de plus d’une
variable. La dérivation a une grande variété d’applications en chimie et en
physique. Par exemple, en physique, la dérivée de la position par rapport au

temps donne la vitesse, tandis que la deuxième dérivation donne
l’accélération.
Exemple : La trajectoire d’un corps à travers l’espace est décrite avec une
fonction s(t). Alors la vitesse moyenne du corps entre deux points A et B est :
AB
AB
AB tt
tsts
v−
−
=>< )()(
La vitesse instantanée est :
dt
ds
v=
On utilise plusieurs notations. Par exemple, la notation de Lagrange utilise
des le signe « ` » :
f’(x) : première dérivée de f par rapport à x
f”(x) : dérivée seconde de f par rapport à x
La dérivée de f(x) est notée comme suit si on utilise la notation de Leibniz :
dx
xfd ))((
Et la dérivée seconde :
2
2))((
dx
xfd
Des listes de dérivées usuelles sont disponibles dans des tables de dérivées.
Le processus inverse de la dérivation est l’intégration. L’intégrale d’une
fonction f d’une variable réelle x dans l’intervalle [a, b] est égale à l’air entre la
courbe de f et l’axe des x d’une part et entre les droites x = a et x = b d’autre
part. L’intégration est le processus visant à trouver l’intégrale. L’intégrale de
f(x) entre a et b est notée ainsi :
∫
b
adxxf )(
Le signe marque l’intégrale, a et b sont les bornes de l’intégrale, f(x) est la
fonction à intégrer et dx est une indication montrant la variable selon laquelle
on intègre.
Pour une liste des intégrales usuelles, voir une table d'intégrales.
 6
7
6
7
1
/
7
100%