Chapitre 26 : Variables aléatoires réelles à densité

ECS3 Carnot Chapitre 26 — Variables aléatoires réelles à densité. 2013/2014
Chapitre 26 : Variables aléatoires réelles
à densité
Dans tout ce chapitre (Ω,A, P )est un espace probabilisé.
1 Généralités
1.1 Densité
Définition 1.1.1
On dit qu’une variable aléatoire réelle Xest à densité lorsque sa fonction de répartition
FXest continue sur Ret de classe C1sur Rsauf en un nombre fini de points.
Toute fonction fà valeurs positives qui ne diffère de F′qu’en un nombre fini de
points est appelée une densité de f.
Remarque. 1. Il faut être précis. Xest à densité ssi FX∈ C0(R)et il existe {x0,...,xn}
un ensemble fini de points tel que FXest de classe C1sur R r {x0,...,xn}. Mais elle
est continue partout.
2. Bien entendu on ne peut donc définir F′
Xqu’à un nombre fini de points prêt c’est
pourquoi il y a plusieurs densités possibles.
3. Et il est clair, pour des raison de continuité, qu’une variable aléatoire discrète n’est
pas à densité !
4. La loi de Xest bien déterminée si on connait sa fonction de répartition.
Exemple. Soit Xla variable aléatoire de fonction de répartition FX:x7→
0 si x60
xsi x∈]0,1[
1 si x>1
.
Vérifions que FXest bien une fonction de répartition : elle est bien croissante, de limite
nulle en −∞, de limite 1 en +∞. Vérifions la continuité : sur ]− ∞,0[, sur ]0,1[ et sur
]1,+∞[, c’est clair car ce sont des fonctions classiques.
En 0, la limite à gauche est 0 et à droite lim
x→0+x= 0 donc FXest continue en 0.
En 1 la limite à droite est 1 et à gauche lim
x→1−
x= 1.
FXest donc une fonction de répartition (croissante, continue à droite, limite à gauche
et limites en ±∞ qui correspondent) continue. Elles est de plus clairement de classe C1sur
R r {0,1}.
Ainsi Xest bien une variable aléatoire réelle à densité (c’est une loi classique, c.f. ci-
dessous). Une densité est donnée par exemple par la fonction x7→ 0 si x∈]− ∞,0] ∪[1,+∞[
1 sinon .
Mais on peut changer la valeur d’un nombre fini de points sans changer la propriété « être
une densité de X».
Théorème 1.1.1
Soit Xune variable aléatoire réelle à densité, de fonction de répartition F:R→R. Si
fest une densité de X, alors pour tout x∈RF(x) = Rx
−∞ f(t)dt.
J. Gärtner. 1

ECS3 Carnot Chapitre 26 — Variables aléatoires réelles à densité. 2013/2014
Démonstration : La seule difficulté (comme souvent dans ce chapitre) est de gérer les points
« à problèmes » : soit a1< a2···< a −nles points où F′n’est pas définie ou en lesquels f
diffère de F′. Pour être plus pratique, on ajoute a0=−∞ et an+1 = +∞. Soit x∈R. On
doit montrer que Rx
−∞ f(t)dtconverge et vaut F(x).
Si x < a1alors Fest une primitive de fsur ]− ∞, a1[avec lim
t→−∞ F(t) = 0. Ainsi
l’intégrale Rx
−∞ f(t)dtconverge et vaut F(x).
Si x>a1, il existe un unique ptel que ap6x < ap+1. On peut quand même utiliser
Fqui est maintenant une primitive de fsur tous les ]ak, ak+1[avec k∈[[ 0 ; p]]. Comme
Fest continue par hypothèse, lim
t→y−
F(t) = lim
t→y+F(t) = F(y)ce qui montre que pour
k∈[[ 1 ; n−1 ]], l’intégrales Rak+1
akf(t)dtconverge et vaut F(ak+1)−F(ak). Comme dans
le cas précédent, Ra1
−∞ f(t)dtconverge et vaut F(a1)et enfin Rx
apf(t)dtconverge et vaut
F(x)−F(ap).
Bref par définition de l’intégrale d’une fonction continue sauf en un nombre fini de
points, on a Rx
−∞ f(t)dtqui converge et sa valeur, à savoir
p−1
P
k=0 Rak+1
akf(t)dt+Rx
apf(t)dt=
F(a1) +
p−1
P
k=1
F(ak+1)−F(ak) + F(x)−F(ap) = F(x).
Théorème 1.1.2
Soit fune fonction définie sur R. Alors fest une densité de probabilité ssi
1. fest continue sur Rsauf éventuellement en un nombre fini de points.
2. ∀x∈R, f(x)>0.
3. R+∞
−∞ f(t)dtconverge et vaut 1.
Démonstration : Si fest une densité, toutes ces propriétés ont déjà été montrées. La réci-
proque est admise, car nécessite des manipulation fines sur Ω...
Exemple. Soit fla fonction définie sur Rpar f(x) = (cos xsi x∈[0,π
2]
0 sinon .fest conti-
nue sur R∗, positive, et R+∞
−∞ f(t)dtconverge et vaut 1. C’est une densité de probabilité
pour une variable Xde fonction de répartition x7→ Rx
−∞ f(t)dt=
0 si x60
sin xsi x∈]0,π
2]
1 si x > π
2
.
Proposition 1.1.1
Soit Xune variable aléatoire réelle de densité f. Alors
1. ∀a∈R, P (X=a) = 0
2. Pour tout a, b ∈Rtels que a6bon a
P(a < X < b) = P(a < X 6b) = P(a6X < b) = P(a6X6b) = Zb
a
f(t)dt.
3. Pour tout a, b ∈R,
P(X < a) = P(X6a) = Za
−∞
f(t)dt
P(X > b) = P(X>b) = Z+∞
b
f(t)dt
J. Gärtner. 2

ECS3 Carnot Chapitre 26 — Variables aléatoires réelles à densité. 2013/2014
Démonstration : Soit Fla fonction de répartition de X
1. Cette propriété, appelée "absence d’atomes" montre qu’une variable à densité est à
l’opposé d’une variable discrète.
Soit a∈Ret n∈N. Alors 06P(X=a)6P(a−1
n< X 6a) = F(a)−F(a−1
n).
Le membre de droite converge vers 0 par continuité de F, donc P(X=a) = 0 (il y a
un lien avec le théorème de la limite monotone, lequel ?)
2. On a P(a < X 6b) = Rb
−∞ f(t)dt−Ra
−∞ f(t)dt=Rb
af(t)dtet comme P(X=a) =
P(X=b) = 0 on en déduit que toutes les autres probabilités proposées sont égales.
3. De même, évident.
Proposition 1.1.2
Si fest nulle en dehors de [a, b], alors P(X < a) = P(X > b) = 0 et Xest à valeurs
dans [a, b]presque sûrement.
1.2 Transferts, exemples
L’exemple le plus important de transfert, à bien comprendre, est le transfert affine.
Soit Xune variable aléatoire réelle à densité, de fonction de répartition FX. Soit a, b ∈R
avec a6= 0. On pose Y=aX +bqui est bien une variable aléatoire réelle, et on note FY
sa fonction de répartition. Alors
∀x∈R, FY(x) = P(Y6x) = P(aX +b6x)
Autrement dit si a > 0on a
FY(x) = P(X6x−b
a) = FX(x−b
a)
et si a < 0
FY(x) = P(X>x−b
a) = 1 −FX(x−b
a)
Par composition, x7→ x−b
aest de classe C1sur Rdonc FYest de classe C1sur Rsauf
en un certain nombre de point. Il est important de préciser que ce "certain nombre" est
fini car FXest de classe C1sauf en un nombre fini de points et x7→ x−b
aest bijective
(et donc le "certain nombre" de points où FYn’est pas C1est le même que pour FX). Bref
Yest une variable aléatoire réelle à densité, et en tout point où FYest dérivable on a
Si a > 0
F′
Y(x) = 1
af(x−b
a)
Si a < 0
F′
Y(x) = −1
af(x−b
a)
Bref dans tous les cas, une densité de Yest donnée par la fonction
x7→ 1
|a|fx−b
a.
Les autres exemples peuvent être intéressants, mais ne sont pas au programme de
première année. En général un transfert bijectif se gère bien, de même que le cas de X2.
J. Gärtner. 3

ECS3 Carnot Chapitre 26 — Variables aléatoires réelles à densité. 2013/2014
Exercice. Soit Xune variable aléatoire réelle à densité, de fonction de répartition FX, de
densité fX.
1. Soit Y=X2. Montrer que Yest une variable aléatoire réelle à densité, préciser FY
et une densité fY.
2. Soit ϕ:R→Rune fonction de classe C1sur R, de dérivée strictement positive sur
R. Montrer que Z=ϕ(X)est une variable aléatoire réelle à densité, préciser FZet
une densité de Z.
1.3 Espérance
Définition 1.3.1
Soit Xune variable aléatoire réelle à densité, et fune densité de X. On dit que X
admet une espérance lorsque l’intégrale R+∞
−∞ xf(x)dxest absolument convergente.
Dans ce cas on appelle espérance de Xle réel E(X) = R+∞
−∞ xf(x)dx.
Remarque. La définition ci-dessus est indépendante du choix d’une densité de Xpuisque
deux densités ne diffèrent que d’un nombre fini de points.
Exemple. 1. Soit Xla variable aléatoire de fonction de répartition FX:x7→
0 si x60
xsi x∈]0,1[
1 si x>1
.
Alors Xadmet une espérance, qui vaut 1
2.
2. Soit Xla variable aléatoire de densité f(x) = (cos xsi x∈[0,π
2]
0 sinon . Alors R0
−∞ xf(x)dx=
0et R+∞
0xf(x)dx=R
π
2
0xcos xdxest absolument convergente et vaut (après intégra-
tion par parties) π
2−1. Bref Xa une espérance, et E(X) = π
2−1.
3. Soit f:x7→ 1
π(1 + x2). C’est une fonction continue sur R, positive sur Ret
R+∞
−∞ f(x)dxconverge et vaut 1. Bref fest densité d’une variable aléatoire X. Pour-
tant pour tout x∈R, on a xf (x) = x
π(1 + x2)∼x→1
1
πx >0et R+∞
1
dx
xdiverge. On
en déduit que R+∞
−∞ |x|f(x)dxdiverge. Autrement dit, on a un exemple de variable
aléatoire à densité qui n’admet pas d’espérance.
Remarque. On voit au passage que pour montrer que Xa une espérance, on doit étudier
la convergence absolue de R+∞
−∞ xf(x)dxce qu’on peut faire en découpant en 0 : c’est la
convergence absolue de R0
−∞ xf(x)dxet de R+∞
0xf(x)dx. Mais comme f>0, on s’est
ramené à l’étude de la convergence d’intégrales de fonction de signe constant.
Proposition 1.3.1 (Positivité)
Soit Xune variable aléatoire à densité, admettant une espérance. Si X>0p.s., alors
E(X)>0.
Démonstration : Pour tout x < 0on a 06P(X6x)6P(X < 0) = 0 donc FXest nulle sur
R−∗ et F′y est nulle. Xadmet donc une densité nulle sur R−∗ et E(X) = R+∞
0xf(x)dx>0
puisque ∀x>0, xf(x)>0.
J. Gärtner. 4

ECS3 Carnot Chapitre 26 — Variables aléatoires réelles à densité. 2013/2014
Proposition 1.3.2 (Linéarité faible)
Soit Xune variable aléatoire réelle à densité admettant une espérance, soit a, b deux
réels avec a6= 0. Alors la variable aléatoire aX +badmet une espérance et E(aX +b) =
aE(X) + b.
Démonstration : PRECISER
Soit fXune densité de Xet Y=aX +b. On a vu que Yétait une variable aléatoire à
densité, et qu’une densité de Yétait donnée par fY:x7→ 1
|a|fx−b
a. On en déduit que
Yadmet une espérance ssi l’intégrale R+∞
−∞ |x|
|a|fx−b
adxconverge. Soit A6Bdeux
réels.
Supposons par exemple a > 0. On a, à l’aide du changement de variables y=x−b
a
(Attention, c’est ici que le signe de aa de l’importance !)
ZB
A
|x|
afx−b
adx=ZB−b
a
A−b
a|ay +b|f(y)dy6ZB−b
a
A−b
a
a|y|f(y)dy+|b|ZB−b
a
A−b
a
f(y)dy
Où l’inégalité découle de l’inégalité triangulaire, sachant que les intégrales convergent par
hypothèse. On en déduit la majoration
ZB
A
|x|
afx−b
adx6aE(|X|) + b
D’après le théorème de majoration des intégrales de fonctions positives, R+∞
−∞ |x|fY(x)dx
converge, donc Yadmet une espérance et le même changement de variable donne E(Y) =
aE(X) + b.
Définition 1.3.2
Soit Xune variable aléatoire réelle à densité admettant une espérance. On dit que X
est centrée lorsque E(X) = 0. Sinon, on peut s’interesser à la variable X−E(X)qui
est la variable centrée associée à X.
En effet E(X−E(X)) = E(X)−E(X) = 0 !
Par exemple si Xadmet une densité paire et une espérance, Xest centrée.
1.4 Variance (HP de première année)
2 Lois classiques
2.1 Loi uniforme
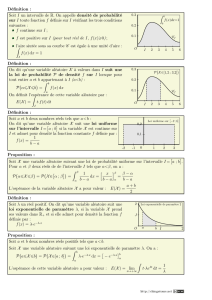
Définition 2.1.1
On dit que Xsuit la loi uniforme sur [a, b]lorsque Xadmet pour densité la fonction
f:x7→
1
b−asi x∈[a, b]
0 sinon
. On note X ֒→ U([a, b]).
Comme Xest à densité, P(X=x) = 0 pour tout xet la loi uniforme sur [a, b]est la
même que sur [a, b[,]a, b]ou ]a, b[.
Vérifions que c’est bien une densité de probabilité : fest continue sur Rr{a, b}, positive
et R+∞
−∞ f(t)dt=Ra
−∞ 0dt+Rb
a
dt
b−a+R+∞
b0dt= 1 (et est convergente...)
J. Gärtner. 5
 6
7
8
9
6
7
8
9
1
/
9
100%