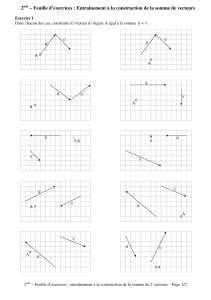
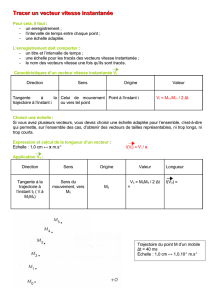
Indexation et Recherche d`Images par Contenu dans les Grands

Présenté par :
BENKRAMA Soumia
Intitulé
Indexation et Recherche d’Images par Contenu dans les Grands
Corpus d’Images
Faculté : Mathématique et d’informatique
Département : Informatique
Domaine : MI
Filière : Informatique
Intitulé de la Formation : Ingénierie des Systèmes d’Information
Année Universitaire : 2016-2017
Membres de Jury Grade Qualité Domiciliation
Mme BELBACHIR Hafida PROFESSEUR Président USTO-MB
Mme ZAOUI Lynda DOCTEUR Encadrant USTO-MB
Mme BABA HAMED Latifa PROFESSEUR
Examinateurs
Université d’Oran
Mr BENYETTOU Abdekader PROFESSEUR USTO-MB
Mme NAIT BAHLOUL Safia PROFESSEUR Université d’Oran
SOUTENUE LE : 09/ 02 / 2017
Devant le Jury Composé de :

Thèse réalisée au Département d’informatique
Faculté des Mathématiques et Informatique
Université des Sciences et de la Technologie d’Oran
- Mohamed Boudiaf (U.S.T.O-MB)
BP 1505 El M’Naouar Bir el Djir 31000
Oran, 31000, Algérie
http://www.univ-usto.dz/mathinfo/presentation.php
Présentée par BENKRAMA Soumia soumia.b[email protected]
Sous la direction de : ZAOUI Lynda zaoui_lynda@yahoo.fr
Étude de cas réalisée dans Laboratoire L.S.S.D (Laboratoire Signaux Systèmes Donneès)
Faculté des Mathématiques et Informatique
U.S.T.O_M.B- Algérie

Travaux scientifiques
Activités scientifiques:
1. Participation de session orale de l’article « Adaptation de VA-File dans
les systèmes d’indexation et de recherche d’images par contenu à grande
echelle ». 2ème Edition de la Conférence Internationale sur l’Extraction et
la Gestion des Connaissances - Maghreb EGC-M2011. Tanger, MAROC.
2. Participation de session orale de l’article « Indexation et recherche par
contenu dans de très grandes bases d’image » Ecole Thématique sur
l’Informatique et les Technologies de l’Information ITI 2011. Oran, AL-
GERIE.
3. Participation au workshop Innovation et Nouvelles Tendances dans les
Systèmes d’information INTIS’2011. Tanger, MAROC.
4. Participation de session orale de l’article « Adaptation des techniques
d’indexation pour la recherche d’images par contenu » Conférence Inter-
nationale sur le Traitement de l’Information Multimédia CITIM’2012.
Mascara, ALGERIE.
Publications
1. Benkrama, S ; Zaoui, L ; Charrier, C : « Accurate Image Search using
Local Descriptors into a Compact Image Representation ». In Interna-
tional Journal of Computer Science Issues IJCSI. Vol 10, Issue 1, N°2,
pp. 220-225, 2013.
2. Benkrama, S ; Zaoui, L ; Charrier, C : « Clustering and dimensionality
reduction forimage retrieval in high-dimensional spaces». In Journal of
Theoretical and Applied Computer Science JTACS. Vol 8, N°3, pp.37-50,
2014.
3. Benkrama, S ; Zaoui, L : « Similarity Search in a large Scale». In Inter-
national Journal of Imaging and Robotics. Vol 16, N°3. 2016
3


Remerciements
A l’issue de la rédaction de cette recherche, je suis convaincue que la thèse est loin
d’être un travail solitaire. En effet, je n’aurais jamais pu réaliser ce travail doctoral
sans le soutien d’un grand nombre de personnes dont la générosité, la bonne humeur
et l’intérêt manifestés à l’égard de ma recherche m’ont permis de progresser dans
cette phase délicate de « l’apprenti chercheur». Au terme de ce travail, c’est avec
émotion que je tiens à remercier tous ceux qui, de près ou de loin, ont contribué à
la réalisation de ce projet.
En premier lieu, je remercie très chaleureusement ma directrice de thèse, madame
Zaoui Lynda, qui, malgré ses nombreuses occupations, a accepté de prendre la direc-
tion de cette thèse en cours de route, transformant ainsi les difficultés rencontrées en
une expérience enrichissante. Je lui suis également reconnaissante de m’avoir assuré
un encadrement rigoureux tout au long de ces années.
Je tiens à remercier les membres du jury de l’intérêt qu’ils ont porté à mes travaux.
Je remercie Mme. Belbachir Hafida, d’avoir accepté d’être président de ce travail.
Je remercie également Mme. Baba ahmed Latifa, Mme. Nait Bahloul Nacéra et Mr
Benyettou d’avoir accepté d’être examinateurs.
Je remercie les membres du laboratoire signaux, systèmes de données pour la
dynamique au sein du groupe que ce soit sur le plan scientifique ou sur le plan
humain.
Je ne sais comment exprimer ma gratitude à ces deux personnes Sarah et Asmaa
pour leurs aide et leurs soutien mais aussi pour leurs encouragements répétés au
cours de la rédaction de ce manuscrit.
J’adresse toute mon affection à ma famille et en particulier à mes parents, mes
sœurs et mon frère, Meriem, awatif, chaimaa et abdelkader. Je ne serai pas la où j’en
suis sans eux. De même, que tous les membres de ma belle famille Baiche trouvent
ici toute ma reconnaissance pour le soutien que chacun d’eux a pu apporter pour
faire aboutir ce rêve.
Enfin, le dernier et pas des moindres, je voudrais remercier tout particulièrement
mon cher époux Amine pour son amour, son soutien quotidien indéfectible et son
enthousiasme et sa patience à mon égard. Merci d’être ce que tu es. De plus, mes
remerciements seraient incomplets, si je ne fais pas mention de mon adorable petite
ma fille Alaa, qui a pu supporter mon éloignement et a pu continuer d’être sage en
dépit de mon absence. Je t’adresse mes chaleureux remerciements.
5
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
1
/
152
100%