Chapitre 10 : Variables aléatoires – Cours complet. - 1 -
Variables aléatoires.
Chapitre 10 : cours complet.
1. Variable aléatoire discrète.
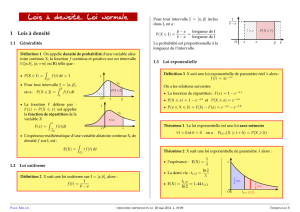
Définition 1.1 : variable aléatoire discrète.
Théorème 1.1 : image réciproque d’une partie de E.
Théorème 1.2 : probabilité attachée à une variable aléatoire discrète.
Définition 1.2 : loi de probabilité d’une variable aléatoire discrète.
Théorème 1.3 : système complet induit par une variable aléatoire discrète.
Théorème 1.4 : caractérisation d’une loi de variable aléatoire discrète à l’aide d’événements élémentaires.
Théorème 1.5 :
(admis)
existence d’une probabilité pour (x
n
) et (p
n
) données.
2. Fonction de répartition d’une variable aléatoire discrète, lois classiques.
Définition 2.1 : fonction de répartition d’une variable aléatoire discrète réelle.
Définition 2.2 :
(hors programme)
histogramme d’une variable aléatoire discrète réelle.
Théorème 2.1 : propriétés d’une fonction de répartition d’une variable aléatoire réelle discrète.
exemples : fonctions de répartition et histogrammes des lois uniforme, de Bernoulli, binomiale.
Définition 2.3 : loi géométrique.
Théorème 2.2 : loi géométrique ⇔ variable aléatoire discrète sans mémoire.
Définition 2.4 : loi de Poisson.
Théorème 2.3 : approximation d’une loi binomiale par une loi de Poisson.
3. Espérance d’une variable aléatoire discrète.
Définition 3.1 : espérance d’une variable aléatoire discrète.
Théorème 3.1 :
(admis)
ordre des termes pour le calcul d’une espérance.
Théorème 3.2 : espérance d’une variable aléatoire discrète à valeurs dans .
Théorème 3.3 :
(admis)
formule du transfert.
Théorème 3.4 :
(admis)
linéarité de l’espérance.
Théorème 3.5 : premières propriétés de l’espérance.
Théorème 3.6 : espérance d’une variable aléatoire suivant une loi géométrique G(p).
Théorème 3.7 : espérance d’une variable aléatoire suivant une loi de Poisson P(λ).
Théorème 3.8 : espérance d’une variable aléatoire prenant un nombre fini de valeurs.
Rappel : espérance des lois uniforme, de Bernoulli et binomiale.
Théorème 3.9 : inégalité de Markov.
4. Couple et famille de variables aléatoires, indépendance.
Théorème 4.1 et définition 4.1 : couple de variables aléatoires discrètes.
Définition 4.2 : loi conjointe et lois marginales d’un couple de variables aléatoires discrètes.
Théorème 4.2 : lien entre loi conjointe et lois marginales d’un couple de variables aléatoires.
Définition 4.3 : lois conditionnelles.
Théorème 4.3 : lien entre loi conjointe, loi marginale et loi conditionnelle.
Définition 4.4 : couple de variables aléatoires indépendantes.
Théorème 4.4 :
(admis)
indépendance et événements non élémentaires.
Théorème 4.5 :
(admis)
espérance d’un produit de variables aléatoires discrètes indépendantes.
Théorème 4.6 : images de deux variables aléatoires discrètes indépendantes.
Définition 4.5 : famille finie de variables aléatoires discrètes mutuellement indépendantes.
Définition 4.6 : suite de variables aléatoires discrètes mutuellement indépendantes.
Théorème 4.7 :
(admis)
existence d’un modèle pour des lois de probabilité données.
Théorème 4.8 : somme de deux variables aléatoires indépendantes suivant une loi de Poisson.
5. Variance et covariance.
Théorème 5.1 : lien entre espérance de X et de X
2
.
Définition 5.1 : variance d’une variable aléatoire discrète réelle.
Théorème 5.2 : autre expression de la variance.
Théorème 5.3 : propriétés élémentaires de la variance.
Définition 5.2 : écart-type d’une variable aléatoire discrète réelle.

Chapitre 10 : Variables aléatoires – Cours complet. - 2 -
Théorème 5.4 : variance d’une variable aléatoire prenant un nombre fini de valeurs.
Exemple : variance d’une variable aléatoire suivant une loi uniforme, de Bernoulli, binomiale.
Théorème 5.5 : variance d’une variable aléatoire suivant une loi géométrique.
Théorème 5.6 ; variance d’une variable aléatoire suivant une loi de Poisson.
Théorème 5.7 : inégalité de Bienaymé-Tchebytchev.
Théorème 5.8 : inégalité de Cauchy-Schwarz.
Théorème 5.9 et définition 5.3 : covariance d’un couple de variables aléatoires discrètes réelles.
Théorème 5.10 : covariance d’un couple de variable aléatoires discrètes réelles indépendantes.
Définition 5.4 et théorème 5.11 : coefficient de corrélation d’un couple de variables aléatoires discrètes
réelles.
Théorème 5.12 : variance d’une somme finie de variables aléatoires discrètes réelles.
Théorème 5.13 : variance d’une somme de deux variables aléatoires discrètes réelles indépendantes.
Théorème 5.14 : loi faible des grands nombres.
6. Fonctions génératrices des variables aléatoires à valeurs dans .
Définition 6.1 : fonction génératrice d’une variable aléatoire à valeurs dans .
Théorème 6.1 : rayon de convergence et propriétés d’une fonction génératrice.
Remarque : fonction génératrice d’une variable aléatoire prenant un nombre fini de valeurs.
Théorème 6.2 : lien réciproque entre fonction génératrice et variable aléatoire.
Théorème 6.3 : fonction génératrice d’une variable suivant une loi géométrique.
Théorème 6.4 : fonction génératrice d’une variable suivante une loi de Poisson.
Théorème 6.5 :
(admis)
espérance de X et dérivabilité de G
X
en 1.
Théorème 6.6 :
(admis)
variance de X et dérivabilité seconde de G
X
en 1.
Théorème 6.7 : fonction génératrice d’une somme de deux variables indépendantes à valeurs dans .
7. Annexe 1 : caractéristiques des lois classiques.
8. Annexe 2 :
(hors programme)
familles sommables de réels.
Définition 8.1 : famille sommable de réels positifs, somme d’une telle famille sommable.
Théorème 8.1 : dénombrabilité des éléments non nuls d’une famille sommable de réels positifs.
Théorème 8.2 : lien entre famille sommable de réels positifs et série.
Théorème 8.3 : opérations sur les familles sommables de réels positifs.
Théorème 8.4 : sous-familles d’une famille sommable de réels positifs.
Théorème 8.5 : sommation par paquets d’une famille sommable de réels positifs.
Définition 8.2 : famille sommable de réels quelconques, somme d’une famille sommable.
Théorème 8.6 : définition équivalente de la sommabilité d’une famille de réels.
Théorème 8.7 : sommabilité et séries absolument convergentes, convergence commutative.
Théorème 8.8 : sous-familles de familles de réels sommables.
Théorème 8.9 : linéarité.
Théorème 8.10 : sommation par paquets d’une famille sommable de réels.
Théorème 8.11 : théorème de Fubini pour les familles sommables de réels.

Chapitre 10 : Variables aléatoires – Cours complet. - 3 -
Variables aléatoires.
Chapitre 10 : cours complet.
1. Variable aléatoire discrète.
Définition 1.1 : variable aléatoire discrète.
Soient (Ω,A) un ensemble muni d’une tribu, et E un ensemble quelconque.
On dit que X est une variable aléatoire discrète (ou v.a.d.) sur (Ω,A) (ou sur Ω) à valeurs dans E si et
seulement si :
• X est une application de Ω dans E,
• l’ensemble des valeurs prises par X sur Ω (soit l’ensemble X(Ω)) est au plus dénombrable,
• ∀ x ∈ E, X
-1
({x}) ∈ A, autrement dit X
-1
({x}) est un évènement.
Pour : x ∈ E, on notera (X = x) ou {X = x} l’évènement X
-1
({x}).
Théorème 1.1 : image réciproque d’une partie de E.
Soient (Ω,A) un ensemble muni d’une tribu et X une variable aléatoire discrète sur Ω à valeurs dans E.
Alors : ∀ U ⊂ X(Ω), X
-1
(U) ∈ A, et donc X
-1
(U) est un évènement.
On notera parfois : X
-1
(U) = {X ∈ U} = (X ∈ U).
Démonstration :
Puisque X(Ω) est au plus dénombrable, U l’est aussi et on peut énumérer ses éléments :
U = {x
n
, n ∈ }, où les x
n
sont deux à deux distincts (la démonstration s’adapte si U est fini).
Puis :
{ }
U
+∞
=
=0nn
xU
, et :
{ } { }
UU
+∞
=
−
+∞
=
−−
=
=
0
1
0
11
)()(
nn
nn
xXxXUX
.
Comme : ∀ x ∈ X(Ω), X
-1
({x}) ∈ A, et puisque A est une tribu sur Ω, on en déduit que, comme réunion
dénombrables d’éléments de A, X
-1
(U) est encore un élément de A.
Théorème 1.2 : probabilité attachée à une variable aléatoire discrète.
Soient (Ω,A,P) un espace probabilisé et X une variable aléatoire discrète sur Ω à valeurs dans un
ensemble E.
Alors l’application P
X
de P(X(Ω)) dans [0,1] définie par :
∀ A ∈ P(X(Ω)), P
X
(A) = P(X
-1
(A)),
définit une probabilité sur (X(Ω),P(X(Ω))).
En particulier, si : x ∈ X(Ω), on notera plus simplement P(X = x) la quantité :
P(X = x) = P
X
(X
-1
({x})) = P({X = x}).
De même, si : A ⊂ X(Ω), on notera plus simplement P(X ∈ A) la quantité :
P(X ∈ A) = P
X
(X
-1
(A)).
Démonstration :
Vérifions les différents points qui garantissent le résultat.
• P
X
est bien à valeurs dans [0,1].
• P
X
(X(Ω)) = P(X
-1
(X(Ω))) = P(Ω) = 1.
• Soit (A
n
) une suite de parties de X(Ω) deux à deux disjointes.
Alors les ensembles {X
-1
(A
n
), n ∈ } sont deux à deux disjoints, donc la série
∑
≥
−
0
1
))((
nn
AXP
est
convergente et :
∑
+∞
=
−
∉
−
=
0
11
))(())((
nn
Nn n
AXPAXP
U
.
Mais on a de plus :
=
∉
−
∉
−
UU
Nn n
Nn n
AXAX
11
)(
, qu’on vérifie par double inclusion.
Donc :
∑∑
∞+
=
∞+
=
−
∉
−
∉
−
∉
==
=
=
00
111
)())(()(
nnX
nn
Nn n
Nn n
Nn nX
APAXPAXPAXPAP
UUU
.
Définition 1.2 : loi de probabilité d’une variable aléatoire discrète.
Soient (Ω,A,P) un espace probabilisé et X une variable aléatoire discrète sur Ω à valeurs dans E.

Chapitre 10 : Variables aléatoires – Cours complet. - 4 -
L’application définie au théorème 1.2 est appelée loi (ou de loi de probabilité) de la variable aléatoire X,
et on la note P
X
.
Théorème 1.3 : système complet induit par une variable aléatoire discrète.
Soient (Ω,A,P) un espace probabilisé et X une variable aléatoire discrète sur Ω à valeurs dans E.
Alors la famille des parties ({X = x
k
}, k ∈ ), où (x
k
) correspond à une énumération de X(Ω), forme un
système complet d’événements.
Démonstration :
Il est clair que ces ensembles sont deux à deux disjoints (un élément ω de Ω ne peut avoir deux images
distinctes par X), et que leur réunion est bien Ω puisque chaque élément ω a une image X(ω) qui se
retrouve dans l’énumération.
Théorème 1.4 : caractérisation d’une loi de variable aléatoire discrète à l’aide d’événements
élémentaires.
Soient (Ω,A,P) un espace probabilisé et X une variable aléatoire discrète sur Ω à valeurs dans E.
Alors la loi de X est entièrement déterminée par la connaissance des P(X = x
k
), où (x
k
) correspond à une
énumération de X(Ω).
Démonstration :
Si on connaît la loi de X, on connaît évidemment les P(X = x
k
), k ∈ .
Réciproquement si on connaît ces probabilités élémentaires, alors :
∀ A ∈ P(X(Ω)),
{
}
U
Kk k
xA
∈
=
, où K est une partie de .
Cette réunion étant disjointe, on peut alors écrire :
{
}
∑
∈
∈
====
Kk k
Kk kX
xXPxXPAP )()()(
U
.
Donc on peut ainsi déterminer P
X
(A) pour tout : A ∈ P(Ω).
Remarque : si : A ∈ P(E), on peut écrire : A = A’ ∪ A’’, avec : A’ ⊂ X(Ω), et : A’’ ⊂ E \ X(Ω).
On peut alors écrire : P
X
(A) = P
X
(A’) + 0, et obtenir ainsi P
X
(A).
Théorème 1.5 :
(admis)
existence d’une probabilité pour (x
n
) et (p
n
) données.
Soient (Ω,A) un ensemble muni d’une tribu et X une variable aléatoire discrète sur Ω à valeurs dans un
ensemble E.
Soient par ailleurs (x
n
) les valeurs prises par X dans E, et (p
n
) une suite d’éléments de [0,1] telle que :
1
0=
∑
+∞
=nn
p
.
Alors il existe une probabilité sur (Ω,A) telle que : ∀ n ∈ ,
nn pxXP == )(
.
Démonstration
(hors programme)
:
X(Ω) étant au plus dénombrable, on écrit : X(Ω) = {x
0
, …, x
n
, …}, et on choisit, pour tout : n ∈ , un
élément ω
n
dans Ω tel que : X(ω
n
) = x
n
.
Pour tout élément A de A, on note ensuite 1
A
sa fonction indicatrice définie par :
∀ ω ∈ Ω, 1
A
(ω) = 1, si : ω ∈ A, et : 1
A
(ω) = 0, si : ω ∉ A.
Enfin, on définit : ∀ A ∈ A,
∑
+∞
=
=0)(1.)( nnAn
pAP
ω
, la somme étant finie si X(Ω) est fini.
Alors P répond au problème, car :
• P est bien à valeurs dans [0,1] puisque les p
n
sont positifs et donc :
∀ A ∈ A,
11)(1.)(0 000 ==≤=≤ ∑∑∑ +∞
=
+∞
=
+∞
=nn
nn
nnAn pppAP
ω
.
•
11)(1.)( 000 ====Ω ∑∑∑ +∞
=
+∞
=
+∞
=Ωnn
nn
nnn pppP
ω
.
• Si (A
p
) est une suite d’éléments de A deux à deux disjoints, on a : ∀ ω ∈ Ω,
∑
+∞
=
=
∞+
=
0
)(1)(1
0
pA
A
p
pp
ωω
U
.
En effet, pour : ω ∈ Ω,
- soit : ∃ p ∈ , ω ∈ A
p
, et dans ce cas il n’y a qu’un seul indice p qui a cette propriété car la famille
est formée d’ensembles disjoints.

Chapitre 10 : Variables aléatoires – Cours complet. - 5 -
On a alors :
1)(1
0
=
∞+
=
ω
U
pp
A.
D’autre part,
)(1
ω
k
A
sont nuls sauf pour : k = p, et il vaut alors 1.
Donc la série
∑
≥0
)(1
pA
p
ω
converge et sa somme vaut 1, ce qui démontre l’égalité annoncée.
- soit : ∀ p ∈ , ω ∉ A
p
, et dans ce cas la série est nulle, de somme 1 d’une part, mais ω
n’appartient pas non plus à la réunion et l’autre terme est nul également d’où à nouveau l’égalité.
Pour : n ∈ , la famille
∑
≥≥ 0,0
)(1.
pn nAn
p
p
ω
est alors sommable car :
- ∀ n ∈ , la famille
∑
≥0
)(1.
pnAn
p
p
ω
est sommable de somme 0 ou p
n
, et :
n
pnAn
pp
p
≤≤
∑
≥0
)(1.0
ω
.
- la famille
∑ ∑
≥ ≥
0 0
)(1.
n p nAn
p
p
ω
est sommable car la famille
∑
≥0
nn
p
est elle-même sommable.
Le théorème de Fubini (th. 8.11) permet d’en déduire que la famille :
∑ ∑∑
≥ ≥≥
=
0 00
)(1.)(
p n nAn
pp
p
pAP
ω
, et :
==
=
=
∞+
=
+∞
=
+∞
=
+∞
=
+∞
=
+∞
=
+∞
=
∑∑ ∑∑ ∑∑ ∞+
=
U
U
0
00 00 00
)(1.)(1.)(1.)(
0
pp
nn
A
n
n p nAn
n p nAn
pp
APpppAP
pp
pp
ωωω
.
Remarque :
Pratiquement toutes les démonstrations hors programme se réfèrent au paragraphe 8 (familles
sommables).
2. Fonction de répartition d’une variable aléatoire discrète, lois classiques.
Définition 2.1 : fonction de répartition d’une variable aléatoire discrète réelle.
Soient (Ω,A,P) un espace probabilisé et X une variable aléatoire discrète réelle sur Ω.
On appelle fonction de répartition de X la fonction F
X
définie sur par :
∀ x ∈ ,
)()( xXPxF
X
≤=
.
Remarque :
En fait, la connaissance de Ω est très souvent inutile.
En pratique, on se contente souvent de la variable aléatoire X ou de sa loi de probabilité ou encore de sa
fonction de répartition F
X
.
Un théorème (difficile) assure que si on se donne une (ou des) « bonne(s) » fonctions, on peut trouver
un univers probabilisé et une (ou des) variable(s) aléatoire(s) sur cet univers dont la (les) fonction(s) de
répartition est (sont) la (les) fonction(s) donnée(s) initialement.
Définition 2.2 :
(hors programme)
histogramme d’une variable aléatoire discrète réelle.
Soient (Ω,A,P) un espace probabilisé et X une variable aléatoire discrète réelle sur Ω.
Soit (x
n
)
n∈
une énumération ordonnée des valeurs de X (telle que (x
n
) est croissante).
On appelle histogramme de X la représentation (en bâtons ou rectangles) de la suite ordonnée
(P(X = x
n
))
n∈
.
Théorème 2.1 : propriétés d’une fonction de répartition d’une variable aléatoire réelle discrète.
Soient (Ω,A,P) un espace probabilisé et X une variable aléatoire discrète réelle sur Ω.
Soit F la fonction de répartition de X.
Alors :
• F est croissante sur ,
•
1)(lim =
+∞→
xF
x
,
•
0)(lim =
−∞→
xF
x
.
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
1
/
35
100%