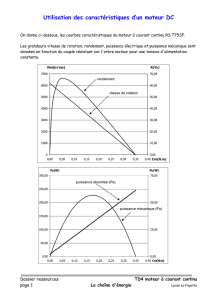
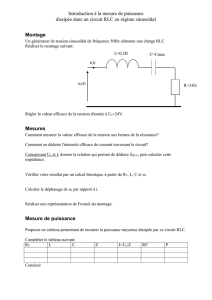
Algorithmes d’approximation et Big Data Lionel Eyraud-Dubois et Olivier Beaumont 2015-2016





Sac `a dos
Probl`eme Sac-A-Dos
IEntr´ees : nobjets, de taille siet profits pi, et une taille S
ISolution : un ensemble Jd’objets, avec Pi∈Jsi≤S
IObjectif : maximiser le profit p(J) = Pi∈Jpi
INP-Complet par r´eduction depuis Partition
IAlgorithme pseudopolynomial en programmation dynamique
(O(nS) ou O(nPipi))
INP-Complet au sens faible / au sens fort
IApproximation polynomiale par arrondis
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
1
/
36
100%