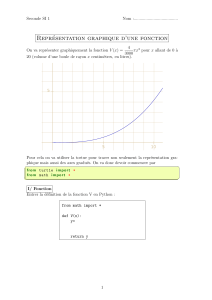
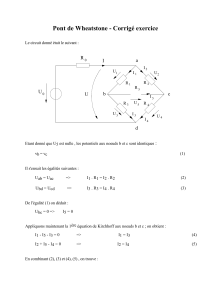
analyse numerique non-lineaire

Universit´
e de Metz
Licence de Math´
ematiques - 3`
eme ann´
ee
1er semestre
ANALYSE NUMERIQUE NON-LINEAIRE
par Ralph Chill
Laboratoire de Math´
ematiques et Applications de Metz
Ann´
ee 2010/11
1


Table des mati`
eres
Chapitre 1. Repr´
esentation des nombres 5
Chapitre 2. Interpolation et approximation 9
1. Interpolation selon Lagrange 9
2. Etude de l’erreur d’interpolation 11
3. L’algorithme de Newton 12
4. Approximation hilbertienne 15
5. Approximation uniforme 19
Chapitre 3. Int´
egration et diff´
erentiation num´
erique 21
1. Int´
egration approch´
ee 21
2. Etude de l’erreur d’int´
egration approch´
ee 24
3. La formule d’int´
egration approch´
ee de Gauss 26
4. Diff´
erentiation num´
erique 27
Chapitre 4. R´
esolution num´
erique d’´
equations non-lin´
eaires dans RN31
1. R´
esolution num´
erique d’une ´
equation d’une variable par dichotomie ou
regula falsi 31
2. Approximations successives 32
3. M´
ethode de Newton 32
4. M´
ethode de plus grande descente 32
Chapitre 5. R´
esolution num´
erique d’´
equations diff´
erentielles ordinaires 33
1. Le sch´
ema d’Euler explicite ou implicite 34
3


CHAPITRE 1
Repr´
esentation des nombres
P 1.1. Soit β≥2un entier donn´e (la base). Alors tout nombre r´eel
x∈Rs’´ecrit de la forme
x=(−1)s·
k
X
j=−∞
ajβj
avec s ∈ {0,1}, k ∈Z, a j∈N,0≤aj≤β−1. Si on exige que ak,0, alors la
repr´esentation ci-dessus est unique. On ´ecrit aussi
(1.1) x=akak−1...a0,a−1a−2a−3. . . .
Si β=10, alors la repr´
esentation (1.1) est exactement la repr´
esentation d´ecimale
de x. Autres bases fr´
equentes: β=2 (repr´
esentation binaire), β=8 ou β=16
(repr´
esentation hexad´
ecimale). Pour les ordinateurs, on a typiquement β=2.
Dans l’´
ecriture (1.1), d´
eplacer la virgule d’une position `
a droite (ou `
a gauche)
correspond `
a une multiplication (ou une division) par β. Tout nombre x∈Radmet
donc une unique repr´
esentation sous la forme
(1.2) x=(−1)sak,ak−1ak−2ak−3··· · βk
avec s∈ {0,1},k∈Z,aj∈N, 0 ≤aj≤β−1, ak,0. C’est cette repr´
esentation
scientifique (ou: repr´
esentation en virgule flottante) que l’on va utiliser dans la suite.
Dans cette repr´
esentation on appelle sou (−1)sle signe, la suite ak,ak−1ak−2ak−3. . .
la mantisse et k∈Zl’exposant de x. Ces trois variables caract´
erisent le nombre r´
eel
x.
0.1. Repr´
esentation binaire. Nombres machine. Dans la repr´
esentation bi-
naire (c.`
a.d. β=2) on a
s∈ {0,1},
k∈Z,
aj∈ {0,1}(j≤k),et
ak=1.
Comme la m´
emoire d’un ordinateur est limit´
e, on ne peut coder qu’un nombre fini de
nombres r´
eels. Ainsi, la mantisse d’un nombre machine est toujours une suite finie,
et l’ensemble des exposants kest un ensemble fini. Par exemple, avec b bits (binary
5
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
1
/
36
100%