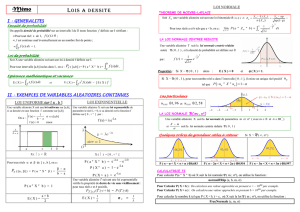
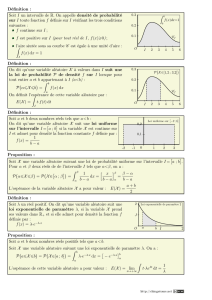
Le cercle répétiteur de Borda : une solution technologique fondée

Le cercle répétiteur de Borda :
une solution technologique fondée sur
l'étude statistique des erreurs aléatoires
Publication n°118 de la commission Inter-IREM Lycées techniques
Commission Inter-IREM
Lycées techniques
Institut Galilée
99, av. J.B. Clément
93430 VILLETANEUSE

2
UNIVERSITE Paris-Nord - I.R.E.M.
LA STATISTIQUE INFERENTIELLE
EN QUATRE SEANCES
Carnet de stage
272 pages
Dépôt légal : 4ème trimestre 2002

3
AVANT-PROPOS
La statistique inférentielle est au programme de la plupart des BTS tertiaires et
industriels depuis une quinzaine d'années. Ce thème, absent de la formation initiale de la
plupart des enseignants de mathématique, a nécessité de gros efforts de formation continue.
Les formateurs étant peu nombreux, notre commission inter-IREM a organisé de nombreuses
journées d'information dans les académies.
Les stages que notre commission a organisé sur ce thème à Paris pour les professeurs de
mathématiques en BTS ont été ouverts aux professeurs des académies voisines (Amiens,
Caen, Dijon, Orléans, Rouen). Bien que portant sur de "nouveaux programmes de 1988", ces
stages n'ont pas désemplis jusqu'en 2000… Les épreuves d'examen de BTS n'ont intégré que
très progressivement ces notions, pour laisser aux enseignants le temps de les approfondir.
Malgré cela il n'était pas rare, il y a peu, de trouver dans des sujets de BTS des questions où la
distinction entre intervalle de confiance et test n'était pas évidente, ou entre paramètres à
tester et observations…
Je m'occupe de la formation continue depuis 1977 et la statistique inférentielle est le
seul thème de formation qui ait nécessité durant cette période un dispositif aussi étalé dans le
temps.
Bien entendu l'outil informatique a permis de développer récemment les activités de
simulation.
Notre réflexion sur l'enseignement de la statistique inférentielle en BTS depuis une
quinzaine d'années nous a été très précieuse pour aborder les nouveaux programmes apparus
en seconde à la rentrée 2000, même si, comme plus personne ne l'ignore maintenant, les
"fourchettes" ne sont pas des "intervalles de confiance"… Nous étions, par exemple, un des
rares groupes IREM (pour ne pas dire le seul) a avoir travaillé et publié sur la simulation, à la
demande notamment de Monsieur Jean-Louis Piednoir IGEN, dans le cadre de travaux
commandés par la direction de l'enseignement scolaire du Ministère.
La pénurie de formateurs sur ce thème s'étendant aux séries générales, tout
naturellement, nous avons mis en place des stages de statistique et probabilités sur les
nouveaux programmes pour les classes de seconde, première et terminale, à Paris, pour les
académies d'Ile de France.
Philippe Dutarte, en s'appuyant notamment sur les travaux de la commission inter-
IREM lycées techniques, anime ces formations, ainsi que des journées d'information sur
l'usage des TICE en statistique et probabilités dans les académies, à la demande des IA-IPR.
La brochure suivante est le document papier remis aux participants à ces stages et
séances d'information au cours desquels Philippe Dutarte présente différentes activités sur
calculatrices ou ordinateurs.
Nous espérons que ce "carnet de stage" rendra service aux collègues et les remercions
par avance de leurs remarques et suggestions.
Bernard VERLANT
Responsable de la Commission Inter-IREM
"Lycées techniques"

4

5
Cette brochure a été réalisée par :
Philippe DUTARTE
dutarte@club-internet.fr
Christian KERN
Lycée Alain – ALENÇON
Avec la participation de :
Marie-France NOUGUES Faculté des Sciences de Montpellier
Christine DHERS Lycée Newton ENREA – Clichy la Garenne
Geneviève SAINT-PIERRE IREM de Paris-Nord
Dominique ARBRE Lycée Paul Constans – Montluçon
Françoise DELZONGLE Lycée Eiffel – Cachan
Isabelle BRUN Lycée Pagnol – Athis-Mons
Loïc MAZO Lycée Follereau - Belfort
de la
Commission Inter-IREM "Lycées techniques"
Réalisation :
Bernard VERLANT, responsable de la C.I.I. L.P.-L.T.
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
1
/
272
100%