Génétique Forward et Reverse

Par Krys3000 (Groupe « The Trust » - http://www.cours-en-ligne.tk/) Page 1
GÉNÉTIQUE DES EUCARYOTES ET MARQUEURS
MOLÉCULAIRES
CHAPITRE III : GENETIQUE FORWARD/RESERVE
Génétique : exploration des relations génotype – phénotype.
Le gène mutant est le plus puissant des outils dont elle dispose.
On utilisera des organismes modèles pour faire de la génétique : ils doivent être faciles à élever, avoir un temps de génération
court, un génome compact, une progéniture abondante, et être facile à mutagéniser et à croiser. Ces modèles peuvent servir à
faire de la génétique classique (forward) ou de la génétique inverse (reverse).
La génétique classique part de mutants pour découvrir la fonction normale des gènes. Pour cela, on produit des mutants, on les
isole, on définit les voies génétiques, on créer des mutants suppresseurs ou enhancers pour tester le tout, et on localise puis
clone le gène. C’est un travail long et fastidieux mais efficace, que l’on peut utiliser pour identifier les gènes contrôlant des
fonctions.
La génétique inverse part de protéines purifiées ou de gènes définit et va vers la mutagenèse ciblée. On peut ainsi prendre un
gène dans les bases de données et l’analyser.
I – GÉNÉTIQUE FORWARD
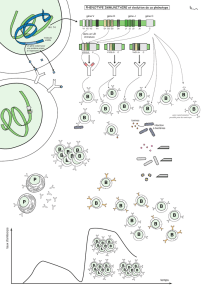
La génétique forward repose sur un phénotype observable. En effet, on impose une mutation (vecteur, agent mutagène, etc.…)
et on observe le résultat final. La procédure que l’on suit est la suivante :
• On définit la question expérimentale
• On prédit ce qu’il pourrait se passer en cas de mutation sur le gène
• On observe les phénotypes correspondant sur les résultats de la mutation
Les mutants peuvent être spontanés qui sont naturels mais rares et pour en avoir il faut cribler des millions d’individus, ou
induits c'est-à-dire qu’on augmente artificiellement la fréquence à l’aide de mutagènes
- Radiations ionisantes provoquant des cassures chromosomiques, délétion, ou inversion.
- UV, EMS ou nitrosoguanine qui provoquent des mutations ponctuelles, insertions et délétions. Les mutations
conditionnelles (thermo-sensibilité par exemple) sont nécessaires pour conserver les mutations chez les Haploïdes
(uniquement pour les mutations dominantes chez les diploïdes) et sont dues à des mutations faux-sens. La fonction de
la protéine est ainsi maintenue à température permissive, bloquée à température non-permissive.
- Transposons insérés aléatoirement. S’il s’intègre dans l’ORF, on a une perte de fonction, alors que s’il s’intègre dans les
régions régulatrices ou dans les introns, on aura un effet sur l’expression : cas de Sleeping Beauty avec un gène
permettant de coder pour une transposase, laquelle pourra exciser et intégrer un Gene Trap dans le génome.
Chez les organismes diploïdes, la majorité des mutations sont récessives et sont des pertes de fonction. Elles sont fréquemment
létales à l’état homozygote.
Les mutations dominantes sont rares, et les dominantes létales on ne les voit jamais, puisqu’ils meurent tout le temps.
On peut détecter des mutations récessives chez les diploïdes en faisant appel à un Chromosome Balanceur. C’est un
chromosome remanié, létal à l’état homozygote, possédant un marqueur dominant (donc il s’exprime si hétérozygotie et on
peut le reconnaitre) mais sur lequel la recombinaison est impossible due à la présence d’inversions de fragments qui rendent
tout les recombinés non viables.
Rechercher les mutants étant un processus lent et fastidieux, une sélection dans laquelle on va exposer à des conditions qui
suppriment ce qu’on ne veut pas garder va pouvoir nous faire aller plus vite (survie dans certaines conditions). Si nos mutations

Par Krys3000 (Groupe « The Trust » - http://www.cours-en-ligne.tk/) Page 2
sont récessives, ça ne sert à rien de faire ça, mais efficace dans la recherche de suppresseurs (mutation affectant un autre gène
restaurant ainsi une fonction normale – voir plus loin).
La dissection génétique est un procédé dont le but sera donc de trouver TOUT les gènes qui contrôlent un phénotype donné,
sachant que plusieurs mutations du MEME gène peuvent donner des phénotypes différent, et à l’inverse, des mutations de
gènes DIFFERENTS peuvent donner le même phénotype. Pour savoir dans quel cas on est, on va avoir recours à des analyses :
Analyses de complémentation pour les mutations récessives :
o Si on croise deux mutants homozygotes, et que chacun possède une mutation dans un gène différent, le gène
1 et le gène 2, les croisements vont annuler les deux mutations étant donné leur récessivité, puisque chacun
apportera la version dominante sauvage de la mutation de l’autre.
o Si on croise deux mutants homozygotes, et que ça se passe dans le même gène, le gène 1 va donner une
mutation effective à chaque fois, alors que le gène 2 n’en aura jamais.
Un groupe de complémentation = groupe au sein duquel les mutants ne complémentent pas. Les mutants complémentent entre
groupes et en général, un groupe correspond à un gène.
Analyses de recombinaison pour les mutations dominantes : on calcule le taux de recombinaison entre loci mutants
quand ils sont présents chez le même individu, ce qui nous permet d’estimer la distance génétique.
Ces analyses permettent de savoir combien de gènes participent à une voie particulière. Pour savoir maintenant à quel niveau le
gène agit sur la voie, on peut faire des analyses d’épistasie : on cherchera donc si l’effet d’un gène dit « épistatique » masque ou
modifie l’effet d’un autre dit « hypostatique ». Pour cela, on croise deux mutants homozygotes au phénotype visible, et, s’il y a
épistasie, le ratio de descendance obtenu ne suivra pas les fréquences classiques du dihybridisme (9-3-3-1).
Alors, pour connaitre l’ordre des deux, il faut prendre un mutant homozygote pour les deux gènes : si celui-ci à un phénotype
identique à l’un des mutants homozygote pour un seul gène, alors c’est ce gène la qui sera en amont dans la voie.
Afin de pousser plus loin l’analyse de la voie génétique, on peut procéder à une nouvelle mutagénèse. L’objectif, c’est de
rechercher des nouvelles mutations qui aggravent (les enhancers) ou atténuent voire font disparaitre (les suppresseurs) la
mutation de base.
Il existe 3 formes de suppresseurs :
- Interaction suppressor : Suite à la première mutation, la protéine A change de forme et ne peut plus se lier à la protéine
B. La deuxième mutation change la forme de la protéine B, et l’interaction est restaurée.
- Bypass suppressor : Suite à la première mutation, une voie génétique est coupée. La deuxième mutation permet
d’emprunter une autre voie pour contourner la mutation.
- High-copy suppressor : Suite à la première mutation, la protéine A, très exprimée et qui interagit normalement
transitoirement avec la protéine B, devient instable est n’est plus foldée. La deuxième mutation surexprimée la
protéine B afin qu’elle stabilise la A par son interaction.
On est capable ensuite de déterminer la localisation exacte de la mutation par séquençage, utilisation de SNPs (ph : [snips]) ou
récupération d’informations par PCR Inverse :
• Introduction de transposon dans une séquence inconnue
• Coupure de cette séquence par une enzyme de restriction n’ayant pas de site dans le transposon
• Ligase permettant de faire un ADN circulaire
• Coupure au niveau du transposon, permettant d’avoir une séquence connue de chaque côté de la séquence inconnue
• PCR sur le brin, puis séquençage et comparaison avec une base de données.
II – GÉNÉTIQUE INVERSE
Il va s’agir de déterminer la ou les fonctions d’un gène déjà identifié. L’approche est inverse, on analyse par bioinformatique
(recherches de motifs connus dans les banques) ou biochimie/biologie moléculaire c'est-à-dire qu’on invalide le gène, on le
remplace ou on le mute et on regarde ce que ça donne.
A l’époque ou le séquençage n’existait pas, on partait souvent d’une protéine connue et on déterminait tout les génomes
possibles pour cette séquence d’acides aminés avant d’utiliser la méthode d’Edman pour connaitre les extrémités N-Term. De
nos jours, le spectromètre de masse permet d’obtenir, à partir d’une protéine inconnue clivée en peptides, la séquence des
acides aminés qu’elle contient et, en comparant à une base de donnée (logiciels qui vont aligner la structure, rechercher des
motifs et prédire des structures) identifier la protéine. Cela permet d’orienter les tests de Biochimie et Biologie Moléculaire qui
vont suivre.

Par Krys3000 (Groupe « The Trust » - http://www.cours-en-ligne.tk/) Page 3
Au cours de ces tests, on va tenter de modifier la protéine via une mutation, et de faire en sorte qu’on puisse identifier cette
protéine d’intérêt ensuite au cours du développement du mutant. Pour cela, plusieurs techniques peuvent être utilisées comme
l’utilisation d’anticorps pour une immunofluorescence ou immunocytochimie.
Pour inférer la fonction, il nous faut connaitre les interacteurs. On peut alors faire de la co-immunoprécipitation ou de la
purification par affinité (purification de complexes, séparés ensuite sur gel dénaturant et identifiés grâce à la bioinformatique).
Enfin, le test ultime pour la fonction d’un gène reste l’étude in vivo en invalidant un gène (insertion d’un autre gène au sein du
premier pour le neutraliser) ou en le remplaçant.
Mis à part l’invalidation/remplacement du gène, l’autre technique pour analyser la fonction d’un gène, c’est la mutagenèse
dirigée (cf. Génie Génétique) :
- On place deux amorces aux extrémités du brin, l’amorce 1 en haut et l’amorce 2 en bas, ainsi que deux amorces
imparfaites, les amorces 3 (en haut) et 4 (en bas), au point à mutagéniser
- On fait ensuite deux PCR, une PCR 1 – 4 et une PCR 2 – 3
- On mélange ce qu’on obtient et après dénaturation on va faire une PCR 1 – 2
Récemment, la technique des ARNi a été inventée. C’est une production artificielle de petits ARN qui vont interférer avec la
fonction normale d’un gène en s’appariant. Cela fonctionne quelque soit l’exon utilisé, indépendamment de la taille de l’ARN, et
nécessite d’avoir une séquence présente sur l’ARNm dans notre interféron. On fait ainsi de la génétique sans recours à la
mutation.
Il existe deux classes d’ARN interféron :
• Les Small Interfering ARN ou ARNsi, petits ARN doubles brins synthétisés à partir d’ARN double brin par une protéine
Dicer. Ils sont pris en charge par le complexe RISC qui va en apparier le brin complémentaire (sens) sur l’ARNm,
provoquant un clivage de celui-ci.
• Les Micro ARN ou ARNmi, petits ARN simple brins synthétisés à partir d’ARN en épingle par une protéine Dicer. Ils
forment le complexent miRNP en s’associant à des protéines, et va pouvoir être apparié sur l’ARNm, bloquant l’action
de celui-ci.
Cette approche présente des avantages (spécifique, puissante, action possible à distance et effets longue durée) et des
inconvénients (l’inhibition est rarement totale, la transduction est parfois difficile, et les oligos ARN sont chers et instables)
Tout ça c’est bien, mais pour analyser un grand génome, c’est super long. Un outil efficace en génétique est le profilage
transcriptomique dans lequel on pratique une analyse simultanée de nombreux gènes sur un support (membrane poreuse ou
support en verre sur lequel on balance des acides nucléiques présynthétisés par PCR ou des oligonucléotides qu’on va plutôt
synthétiser in situ). Ces puces ADN permettent l’analyse à grande échelle des gènes.
1
/
3
100%