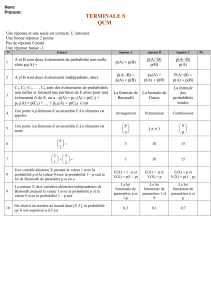
Variables aléatoires

Distribution de probabilités
Rappel:
Liste empirique de fréquences, il s’agit de valeur observée dans l’échantillon.
Distribution de probabilités :fréquence relative (idéale) avec laquelle on s’attend à voir
les observations (valeur des variables) par rapport à un modèle THEORIQUE.
L’idée est de comparer les données empiriques avec un modèle théorique et voir si ça
colle.
Dans une distribution empirique on se base sur le compte des valeurs observées
Distribution de probabilité : on se base sur un modèle théorique.
Quels sont les paramètres pouvant caractérisés une distribution théorique (afin de pouvoir
reproduire les expériences, ou comparer les distributions)
A) L’espace d’échantillonnage : : il s’agit de l’ensemble de tous les résultats possibles
(d’une expérience). Chacun des résultats possibles est appelé : évènement simple
Ex : je jette un dé
={1 ,2,3,4,5,6}
Je tire un 1 ou 2 ou 3, … tirer une valeur est un évènement simple
Ex :Avoir deux enfants
={FG,FF,GF,GG}
Ex : combien de porcins vivants dans la portée
={0,1,2,3,4,…
Avoir 1 porc vivant est un évènement simple. Le nombre d’évènements simples peut-être
infini (pas borné à droite)
Ex : peut appartenir à N (nombre des entiers positifs)
B) Le deuxième paramètre dont on a besoin pour définir notre modèle théorique est la
probabilité associée à chaque évènement simple.
{0, 1, 2, 3, …
{p0,p1,p2,p3,…
p0 étant la probabilité de l’évènement simple 0.
Rmk : Propriété d’une probabilité : 0<=pi<=1
n
ii
p
11
Ex : Jet de dé
={1,2,3,4,5,6)
p={1/6,1/6,…,1/6)
1
i
p
E1={1} et p1=1/6

E2={2} et p2=1/6 …
Distribution empirique
J’aurais lancé le dé un très grand nombre de fois et compter le nombre de fois que X=1,
2, 3,4,5,6 arrivait.
Si on calcule la fréquence relative pour chaque valeur de X, si le modèle théorique est
correct alors fi doit plus ou moins être égal à pi
(Le but étant de trouver un modèle théorique qui s’adapte le mieux aux fréquences que
l’on a trouvé)
Variable Aléatoire
Il s’agit d’une variable qui peut prendre différente valeurs avec une probabilité donnée.
Ex : X représente le résultat d’un jet de dé, on peut dire que X est une variable aléatoire
Ex : X est la taille des personnes d’un échantillon
Les différentes valeurs que peut prendre la variable sont les évènements simples
(on associe une valeur de la variable à un évènement simple)
Ex : pour la taille, on prend tous les valeurs réelles entre 1m30 et 2m80.
A chacune des valeurs possibles de la variable on associe une probabilité.
On peut donc définir la distribution de probabilité de la variable X.
On note aussi les variables aléatoires (va). On parle de variable aléatoire car on ajoute les
notions de probabilités correspondantes aux valeurs de la variable.
Exercice :
Imaginons qu’une vache mette au monde un veau :
Exp : Sexe du veau {0=femelle,1=mâle}
On associe la probal p0 à 0 et la probabilité p1 à 1. De plus
p0+p1=1 (définition d’une probabilité)
=> p0=p1=0.5
Rappel :
On classe les variables aléatoires en fonction de leurs caractéristiques, on va donc
marquer la différence entre les variables qualitatives (nominales ou ordinales) et
quantitatives (continues [ex : poids] ou discrètes [ex : porcins vivants]).
Variable qualitatives ordinales :
Ex : 3 catégories en fonction de l’état de santé d’un cheval de course {Bon, Moyen,
Mauvais}
Qualitative nominale :
Race des animaux par exemple.
Pour chacun de ces types de variables on va choisir un modèle théorique de distribution
de probabilité.

Rmk : Espérance d’une variable aléatoire : (Expected value) : valeur moyenne à
laquelle on s’attend si on répète un grand nombre de fois l’expérience. Il s’agit d’une
valeur théorique (on n’est pas obligé de la retrouvé dans la distribution).
Variables discrètes :
On note l’espérance d’une variable discrète de la manière suivante :
n
iii xpxXE 1)()(
p(xi) : représente la probabilité de la variable aléatoire, si elle vaut 0, elle n’intervient pas
dans l’espérance.
Cette notation ressemble à celle d’une moyenne. p(xi) représentant la fréquence relative
de xi, si on effectue l’expérience un très grand nombre de fois.
Définition générale :
Soit g() est une fonction réelle que l’on applique à x.
Et j’ai une variable y qui a l’espace d’échantillonnage suivant :
={y0,y1,y2, …, yn}
Auquel correspond un ensemble de proba :
{p0,p1,p2,…, pn}
Avec n qui tend vers l’infini.
Rmk :Dans ce cas même si n tend vers l’infini, il s’agit de valeurs infinies dénombrables.
Car on sait les compter par opposition aux valeurs indénombrables, que l’on ne sait pas
compter. Exemple :
On mesure 2 temps lors d’une course :t0 et t1, plus on veut être précis plus il faut
diminuer l’intervalle t0 et t1. Combien y a-t-il de temps possible entre 10 et 11s. C’est
impossible à dire, on pourra toujours trouver un intervalle de temps plus petit que celui
choisit. Impossible à dénombrer entre deux valeurs proches.
Pour appliquer g à x, en gros on remplace les xi d’au dessus par g(yi) :
n
iii ygpYgE 1)())((
Cette formule est intéressante, elle permet de retrouver le cas particulier de la moyenne
où g(y)=1.y (g(y) est la fonction identité qui consiste à multiplier par 1 la variable y)
E(Y)=p0.y0+p1.y1+…+pn.yn
Il est également possible de calculer l’espérance de la moyenne des écarts à la
moyenne (ce que l’on appelle communément la variance):
En choisissant :
))(())((
)()(
2
2
y
y
uyEygE
uyyg
On élève les paramètres calculés via l’échantillon au rang de la population (à condition
que le modèle théorique soit correct)
yiyiy puyuyE 22 )())((

On retrouve une définition analogue de la variance pour la population. En résolvant le
carré on peut très vite arrivé à la formule suivante :
n
i
n
iy
n
iiyiiii upupypy
1 1
2
1
22
Rappel
n
ii
p
11
; définition d’une distribution probabilité
22
1 1
22222
))(()(
2
YEYE
upyuupy
n
i
n
iyiiyyii
Propriétés de l’espérance
Si y est var alors si
byaz
Cas d’utilisation de ce z, convertir des unités en d’autres (ex : y est exprimé en inch, et je
veux l’exprimer en centimètre, je vais utiliser z qui s’exprimera en cm, et qui sera défini
par la conversion des inch vers les cm).
Alors
yz buau
YbEaZE
)()(
Par contre,
222
2)()(
yz b
yVarbzVar
Sigma représente l’écart type de la population (en général on utilise les lettres latines
pour l’échantillon et les lettres grecques pour la population)
Le paramètre a, n’influence pas la variance, par contre le coefficient b passe au carré, la
variance n’est pas un opérateur linéaire.
Construction des modèles théoriques
Variable aléatoire discrète
La distribution binomiale :
On considère une expérience ne pouvant avoir que deux résultats possibles. Ex une vache
va vêler le veau est soit M soit F.
Ex : si on lance un dé, le résultat est pair ou impair.
Si je tire une carte, c’est un cœur ou ce n’est pas un cœur
On va alors parler de succès ou d’échec pour caractériser les deux résultats
Le succès ou l’échec est une interprétation statistique, ex : diagnostiquer une maladie
peut-être considéré comme un succès de l’expérience, pour le patient, ce n’est pas
vraiment un succès.
Si je réalise une expérience, je peux avoir soit un succès, soit un échec, et je peux établir
la probabilité ps du succès ou pe de l’échec.
X étant le résultat de l’expérience, il reste à définir l’espace d’échantillonnage

}1,0{
Si p est ps alors nonp = pe = 1-ps = 1-p. (on l’appelle parfois q)
On calcule les paramètres de cette distribution de succès/echec :
)1(
2
)21()1(
)1()1()0()(
1.0).1(
2
3232
22
2
1
2222
2
1
pp
pp
ppppp
ppppp
pppppux
pppxpu
iixix
iiix
On s’intéresse maintenant à la réalisation multiple de cette expérience :
p sera donc la proportion de fois que l’on obtiendra un succès si on fait un très grand
nombre de fois l’expérience :
ériencelfaitonlquefoisdenombre succèsdenombre
succesP exp''
)(
Dans le cas du dé, si on joue 24000 fois à pile ou face, on remarquera que p(succes)->0.5,
donc p(echec)->0.5
Dans la distribution binomiale, X n’est plus la valeur 0 pour échec et 1 pour succès mais
le nombre de fois que j’ai obtenu un succès en faisant n fois mon expérience.
On répète cette expérience de façon indépendante (dans les mêmes conditions)
Ex : si je tire une carte dans un jeu, je remet la carte avant de recommencer l’expérience.
L’espace d’échantillonnage =
},...,2,1,0{ n
. On remarque qu’ici l’espace d’épreuve est
borné, il n’est pas infini.
Comment calculer la distribution de probabilité associée :
Partons de l’exemple du jeu de carte :
« Je tire cinq fois une carte dans un jeu de 52 cartes, à chaque tirage, je remets la carte, E
est l’évènement avoir un cœur, la probabilité de E est de ¼, la probabilité de ne pas avoir
un cœur, c’est à dire de non E est de ¾.
Je défini X=0 comme étant la probabilité de n’obtenir aucun cœur après cinq expérience :
5
)4/1()( PEetEetEetEetEP
Je défini X=1 comme étant la probabilité d’avoir un seul cœur après cinq tirages (en
ayant remis la carte)
44 )4/3)(4/1(5...))4/3(4/1()1(
))()(
)()()(()1(
XP
EetEetEetEetEouEetEetEetEetEou
EetEetEetEetEouEetEetEetEetEouEetEetEetEetEPXP
Je vois que l’ordre n’a pas d’importance, puisqu’on ne s’intéresse pas au moment du
tirage pendant lequel on aura un cœur
 6
7
8
9
10
11
6
7
8
9
10
11
1
/
11
100%