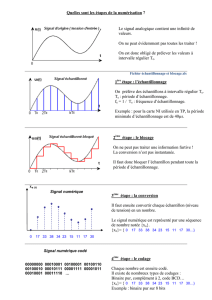
loi faible des grands nombres

statistiques échantillonnage
loi faible des grands nombres
lien entre probabilités et statistiques :
jeu de pile ou face : "pile" avec proba 1/2
on joue une fois : soit "pile", soit "face"
on joue deux fois : pas forcément un "pile", un "face"...
mais si fest la fréquence de "pile", si le nombre de tirages augmente, f tend vers
1/2
41 / 80

statistiques échantillonnage
loi faible des grands nombres
Sur ntirages, soit Snle nombre de "pile", la fréquence est Sn/n
Sn∼B(n,1/2),E(Sn) = n/2, σ(Sn) = √n/2
donc (Tchébychev) p(|Sn−n/2|<t√n/2)≥1−1/t2
donc p(|Sn/n−1/2|<t
2√n)≥1−1/t2
donc si on fixe une proba aussi proche de 1 que l’on veut, avec nassez grand, la
fréquence est proche de 1/2.
42 / 80

statistiques échantillonnage
loi faible des grands nombres
énoncé de la loi faible des grands nombres :
dans une expérience aléatoire, on considère un événement de probabilité p.
Si on répète l’expérience nfois en notant fnla fréquence d’apparition du résultat,
fn→pquand n→+∞.
mais le hasard n’a pas de mémoire
43 / 80

statistiques échantillonnage
échantillonnage
Xvariable de loi connue, espérance µ, variance σ2
propriétés d’un échantillon de taille n: moyenne, variance ?
modélisation de l’échantillon : variable ¯
X=X1+...+Xn
n
¯
X: même espérance mais variance σ2/n!
probabilité que les valeurs effectivement mesurées soient proches de µ?
remarque : on doit supposer que les variables sont indépendantes : tirages avec
remise
44 / 80

statistiques échantillonnage
échantillonnage : loi normale
X∼N(µ, σ2)⇒¯
X∼N(µ, σ2/n)
exemple : disques diamètre D∼N(15,0.252).
Diamètre d’un disque au hasard ? Dans 95.4% des cas dans
[15 −2×√0.0625,15 +2×√0.0625] = [14.5,15.5]
On en prend 10 au hasard, diamètre moyen ?
¯
D∼N(15,0.00625)donc dans 95.4% des cas dans
[15 −2×√0.00625,15 +2×√0.00625] = [14.842,15.158]
Dans 98% des cas dans
45 / 80
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
1
/
26
100%