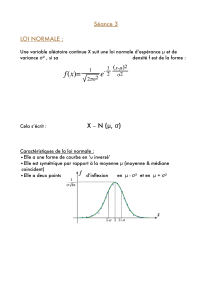
X - UQAM

1
Premier chapitre :
Distributions
Avant propos
Le mot « statistique » au singulier, désigne un ensemble de techniques et d’instruments
scientifiques servant à expliquer et à interpréter les phénomènes pour lesquels une étude
exhaustive s’avère impossible à cause de leur grand nombre ou leur complexité. Elle se
compose des méthodes permettant de recueillir, de classer et d’organiser, de présenter, de
traiter et d’analyser des observations relatives à ces phénomènes pour en tirer ensuite des
conclusions et prendre des décisions. Au pluriel, le mot « statistiques » désigne un
ensemble de données numériques concernant une catégorie de faits et utilisables selon
des méthodes d’interprétation de la statistique.
Bref, le mot « statistiques » désigne des collections de nombres constituant l’information
brute tandis que le mot « statistique » est constitué par un ensemble de méthodes et
techniques qui a pour but d’analyser et d’interpréter cette information afin de mieux
connaître le phénomène en question, de prendre des décisions plus éclairées et
d’envisager des actions plus appropriées.
L’étude statistique d’un phénomène s’effectue, disons, en trois étapes :
1. La collecte des données qui consiste à recueillir les informations adéquates mais
partielles sur le phénomène. Elles serviront ultérieurement de base d’étude. Ces
données sont habituellement obtenues selon un plan de sondage établi d’avance.
2. La statistique descriptive qui précise des techniques permettant de dépouiller les
renseignements obtenus, de les mettre en ordre, de les schématiser en les
présentant sous forme de tableaux ou de graphiques et d’en dégager les
caractéristiques essentielles (moyenne, proportion,…)
3. La statistique inférentielle qui permet de tirer des conclusions sur tout le
phénomène à partir des informations partielles recueillies en autant que certaines
règles et conventions auront été respectées. Ces conclusions comportent une
marge d’erreur statistique qui peut être calculée.
Section 1.1 :
Variables et Distributions
Les types de variables. Les méthodes et les techniques s’appliquent à des
informations écrites sous forme numérique. Ces informations correspondent à des
variables (ou des caractères) parmi lesquelles on différencie les variables qualitatives (ou
catégoriques) et les variables quantitatives.

2
Une variable qualitative (ou catégorique) exprime une propriété ou une qualité ou une
manière d’être des unités statistiques et cette propriété (ou qualité ou manière d’être)
s’observe mais ne se mesure pas.
Une variable quantitative exprime un aspect quantifiable ou numériquement mesurable
dont les valeurs de la variable varient d’un individu à l’autre et dont les opérations de
calcul ( addition, moyenne etc.) ont du sens.
Exemple
Prenons l’ensemble (ou base) de données suivant:
Code Permanent Sexe Note Stat. (/100)
Ahmx23127102 M 65
Doms12127181 M 52
Hamn31018423 F 78
… … …
Pobm19096512 F 82
Youh20027606 M 90
Chaque colonne représente ce qu’on appelle une variable, laquelle mesure la
caractéristique d’un objet.
Exemple:
• Variable catégorique: Sexe représente deux valeurs M et F
• Variable quantitative : Note de l’étudiant(e).
Les nombres ou les lettres qui y figurent sont des valeurs de la variable. La
correspondance entre ces valeurs et leurs fréquences (ou effectifs) est ce qu’on appelle
une distribution.
La première étape de l’analyse descriptive consiste à construire alors la distribution de
fréquences qui est un tableau qui comporte au moins deux lignes (ou colonnes). Dans la
première ligne ( ou colonne) sont écrites les valeurs de la variable considérée et dans la
seconde sont écrites les fréquences de chaque valeur de cette variable. On peut ajouter
une troisième ligne (ou colonne) dans laquelle figurent les fréquences relatives de chaque
valeur de variable.
Exemple d’une distribution de la variable (catégorique) Sexe :
La distribution présentée en fonction des fréquences :
Sexe M F Total
Fréquence 20 30 50

3
La distribution présentée en fonction des fréquences relatives:
Sexe M F Total
Fréquence relative 20/50 0.60 1
Notes:
• La fréquence relative d’une valeur de la variable est égale à la fréquence associée
à cette valeur divisée par la somme des toutes les fréquences.
• La somme des fréquences relatives est toujours égale à 1.
Représentation graphique:
On peut représenter graphiquement la distribution de chaque variable. Ce graphique nous
permet de saisir et d’observer en un coup d’œil les caractéristiques de cette distribution.
C’est ce qu’on appelle: l’analyse exploratoire des données. (Exploratory data
analysis: EDA).
On considérera ici:
• Diagramme à bâtons (bar graph)
Le diagramme à bâtons consiste en une représentation graphique indiquant en ordonnée
la liste des diverses valeurs de la variable étudiée. À la droite de chaque valeur de la
variable on construit horizontalement des rectangles de même largeur et dont les
longueurs sont égales ou proportionnelles aux nombres de cas (fréquences) ou
pourcentages des valeurs des variables représentées. Notons que les rectangles ne peuvent
en aucun cas être accolés.
Exemple:
Voici la distribution du nombre de professeurs dans une faculté de sciences :
Département Fréquence Fréquence
relative
Mathématiques 183 0.47
Informatique 127 0.33
Physique/Chimie 23 0.06
Biologie/Géologie 54 0.14
Total 387 1

4
Procédure « Minitab » pour construire un diagramme à bâtons : Graph>Chart :
Nous obtenons alors:
Bio./Géo. Info. Math. Phy./Ch.
0
100
200
Département
Fréquence

5
• Diagramme en pointes de tarte: «Pie Chart»
Le diagramme en pointes de tarte consiste en un cercle dont l’aire est décomposée en
secteurs circulaires et l’angle au centre de chaque secteur représente la proportion d’une
des valeurs correspondantes à la variable considérée. Pour obtenir cette configuration, il
faut donc déterminer l’angle au centre de chaque secteur circulaire, angle qui est
proportionnel aux nombres de cas ou aux pourcentages représentés.
Prenons l’exemple ci dessus et par Minitab: Graph>Pie Chart,
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
1
/
26
100%