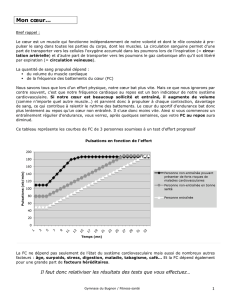
La modélisation par équations structurelles basée sur la méthode PLS

La modélisation par équations structurelles basée sur la méthode PLS : une
approche intéressante pour la recherche en marketing
Marie-Laure Mourre *
Doctorante
Université Paris-Est Créteil
Enseignant-chercheur
Institut Supérieur de Gestion
* 147 avenue Victor Hugo 75116 Paris, mlmourre@yahoo.fr 06 61 39 02 71

La modélisation par équations structurelles basée sur la méthode PLS :
une approche intéressante pour la recherche en marketing
Résumé
La modélisation par équations structurelles basée sur la méthode PLS diffère des méthodes
basées sur l’analyse de covariances telles que Lisrel par son caractère prédictif plutôt que
confirmatoire et sa plus grande souplesse notamment en ce qui concerne les conditions
préalables à son utilisation. Elle permet en outre de traiter l’hétérogénéité des données. Ainsi,
elle s’avère particulièrement intéressante pour les chercheurs en marketing. Après une
description de ses caractéristiques et avantages, nous proposons une illustration sur des
données réelles.
Mots-clés : équations structurelles, méthodologie, PLS
Abstract
Structural equation modeling based on the PLS method differs from covariance-based
methods such as Lisrel by its predictive nature rather than confirmatory and its greater
flexibility especially regarding the prerequisites to its use. In addition, it allows to address the
heterogeneity of the data. Thus, it is particularly interesting for researchers in marketing.
After a description of its features and benefits, we propose an illustration based on real data.
Keywords : SEM, methodology, PLS

La modélisation par équations structurelles basée sur la méthode PLS :
une approche intéressante pour la recherche en marketing
Introduction
La modélisation par équations structurelles est désormais couramment utilisée par les
chercheurs en marketing car elle permet de mettre à jour des liens de causalité entre plusieurs
variables, y compris modératrices et médiatrices, tout en incorporant les erreurs de mesure
(Bagozzi, 1980). Mais, il arrive que les prérequis à son utilisation ne soient pas parfaitement
respectés ; ainsi en est-il de la normalité des données qui est une condition à respecter de la
méthode basée sur l’analyse de covariances et le maximum de vraisemblance (Bentler et
Chou, 1987, Barnes et al., 2001). La violation de la normalité peut conduire à des résultats
erronés ou aberrants (Chin et al., 2001). Or, il existe une méthode d’estimation des paramètres
qui est moins exigeante dans ses conditions d’utilisation (pas de normalité, petits échantillons
acceptés), et qui par ailleurs, se trouve être plus adaptée aux recherches exploratoires et
prédictives tout en étant rigoureuse d’un point de vue statistique (Fernandes, 2012, Hair,
Ringle et Sarstedt, 2011). Il s’agit de la méthode PLS basée sur l’analyse de variance et la
méthode des moindre carrées partiels. Le fait qu’elle soit plus récente (Wold, 1982) et
disponible sur moins de logiciels statistiques explique probablement sa moindre utilisation
alors qu’elle nous semble présenter un grand intérêt pour les chercheurs en marketing.
Sans entrer dans le détail des soubassements théoriques et mathématiques de cette méthode
1
,
nous en présenterons les grands principes, nous exposerons les prérequis à son utilisation, ses
avantages et inconvénients en nous appuyant sur la littérature existante. Nous présenterons
également une méthode d’analyse multi-groupe qui en est issue qui permet de traiter
l’hétérogénéité des données en identifiant des sous-modèles. Nous proposerons enfin une
application sur des données réelles à titre d’illustration.
1. Rappel sur les équations structurelles à variables latentes
Les modèles d’équations structurelles à variables latentes (SEM) sont des modèles multivariés
utilisés pour modéliser les structures de causalité dans les données. L’intérêt de la
modélisation par équations structurelles réside essentiellement dans sa capacité à tester de
manière simultanée l’existence de relations causales entre plusieurs variables latentes. Une
variable latente est une variable qui n’est pas observable et ne peut être mesurée directement.
1
Pour une discussion plus fouillée sur ces aspects, on pourra se reporter à Valette-Florence (1993, 1998)

A l’inverse, pour une variable manifeste, on pourra recueillir une mesure de manière directe.
Les variables latentes peuvent être estimées à partir de variables manifestes en isolant leur
part de variance commune. Les modèles à équations structurelles consistent en un système
d’équations pouvant être représentées sous forme de graphe orienté, les nœuds représentent
les variables sous forme de carré pour les variables manifestes et sous forme de rond pour les
variables latentes, les arcs modélisent les liens de causalité. Chaque variable manifeste est
associée à une seule variable latente et les variables latentes peuvent être liées entre elles. Une
variable latente peut être de type réflexif : chaque variable manifeste reflète sa variable latente
et lui est reliée par une régression plus un terme d’erreur (c’est le cas de ξ1 et η1 de la Figure
1, on notera par exemple x11 = π11.η1+ε11 avec π11 le loading liant la variable manifeste x11 à la
variable latente 1). Elle peut être de type formatif : la variable latente est générée par ses
propres variables manifestes, c’est alors une fonction linéaire des variables manifestes plus un
terme résiduel (cas de η2 de la Figure 1, on notera par exemple η2 = π21x21+π22x22+π23x23+
π23x24+ ε avec πij le poids liant le variable manifeste xij à la variable latente η2). On parlera de
mode MIMIC lorsqu’une variable latente est de type mixte : une partie de ses variables
manifestes sont de type réflexif et les autres de type formatif. On qualifiera d’endogène une
variable dont les valeurs sont déterminées par le modèle et peut à son tour déterminer les
valeurs d’autres variables (η1 et η2 de la Figure 1). Une variable exogène pourra elle aussi
déterminer les valeurs d’autres variables du modèle mais sera elle-même déterminée par des
variables extérieures au modèle (ξ1 de la Figure 1). Enfin, on distinguera au sein du modèle
deux sous-modèles : le modèle de mesure ou modèle externe (outer model) liant les variables
manifestes aux variables latentes et le modèle structurel ou modèle interne (inner model) liant
les variables latentes entre elles. Le modèle structurel sera dit récursif si les liens entre
variables sont unidirectionnels. A l’inverse, un modèle non récursif pourra présenter des
boucles où deux variables endogènes seront réciproquement cause et conséquence l’une de
l’autre.
La modélisation par équations structurelles comporte quatre étapes :
- dans un premier temps, la spécification vise à développer un modèle conceptuel qui
pourra être traité par les logiciels statistiques,
- vient ensuite l’estimation des paramètres en fonction de l’algorithme choisi,
- puis l’évaluation du modèle qui se fera par le biais de différents indicateurs,
- et enfin, la modification du modèle en fonction des informations données par les indices
d’évaluation afin d’obtenir le meilleur modèle possible.

Nous ne rentrerons pas dans le détail des procédures d’estimation des paramètres mais nous
en rappellerons les grands principes dans les lignes qui suivent.
L’estimation des paramètres du modèle se fait aujourd’hui en recourant à différents types
d’algorithme :
- la méthode Lisrel (Linear Structural Relationships) qui repose sur l’analyse de la
structure de covariance et utilise l’approche du maximum de vraisemblance ; elle
requiert la multinormalité des données,
- la méthode GLS (Generalized Least Squares) est moins sensible à la non normalité
mais demeure très sensible à la complexité du modèle,
- les méthodes ADF (Asymptotic Distribution Free) et WLS (Weighted Least Squares)
ne requièrent pas la multinormalité mais exigent des échantillons de plus de 2 500
observations,
- la méthode PLS (Partial Least Square) qui repose sur l’analyse de la variance et
utilise l’approche des moindre carrés partiels.
Nous aborderons uniquement Lisrel qui est la plus utilisée et PLS qui est le sujet de cette
communication.
Figure 1 : Exemple de modèle structurel à variables latentes
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
1
/
24
100%