Méthodes d`apprentissage automatique pour la bioinformatique

M´ethodes d’apprentissage automatique pour la
bioinformatique - BIOL-F-524
TP 5: Analyse discriminante lin´eraire
19 D´ecembre 2008
1 Introduction
L’analyse discriminante lin´eaire (Linear discriminant analysis - LDA)
une une mani`ere de calculer un hyperplan s´eparateur permettant de classifier
des donn´ees. Les donn´ees utilis´ees pour ce TP se trouvent `a l’adresse :
http://www.ulb.ac.be/di/map/yleborgn/BIOLF524/TP5/script.tgz
L’archive contient le fichier R ’lda.R’ dans lequel se trouvent les fonctions qui
seront utilis´ees dans le TP, ainsi qu’une version du jeu de donn´ees microar-
ray Golub modifi´e de mani`ere `a ce que les classes y soient ´equitablement
repr´esent´ees. Une fois dans R, chargez ’lda.R’
source("lda.R")
et le jeu de donn´ees ’Golub50.Rdata’ :
load("Golub50.Rdata")
Le jeu de donn´ees Golub50 contient :
– Une matrice Xde 50 observations pour 7129 variables, repr´esentant les
expressions d’un ensemble de 7129 g`enes pour 50 patients diff´erents.
– Une sortie Y, associant un type de leuc´emie pour chacun des 50 pa-
tients (25 de chaque type, classe 0 ou 1).
2 Analyse discriminante lin´eaire
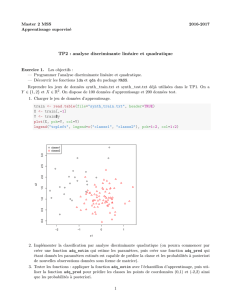
La fonction ’lda.example()’ illustre l’analyse discriminante lin´eaire sur
un jeu de donn´ees g´en´er´e artificellement, et ayant 2 classes possibles. La
ligne noire continue represente la s´eparation optimale (calcul´ee en ayant
connaissance des param`etres ayant permi de g´en´erer les donn´ees), et la ligne
bleue repr´esente la s´eparation obtenue en estimant `a partir du jeu de donn´ees
les param`etres de la gaussienne multiva´eri´ee correspondant `a chacune des
classes.
1

−10 −5 0 5 10
−10 −5 0 5 10
x1
x2
3 Application `a Golub
R´eduisez d’abord la dimensionalit´e du dataset Golub `a 2 dimensions, en
ne retenant que les deux premi`eres composantes principales. Celles-ci sont
obtenues en calculant les deux premiers vecteurs propres de la matrice de
covariance des entr´ees, voir fonction ’getPC’.
X.2<-getPC(X)
Appliquez ensuite l’analyse discriminante lin´eaire :
lda(X.2,Y)
Enfin, calculez l’erreur empirique et l’erreur en 10-fold CV de ce mod`ele.
2
1
/
2
100%