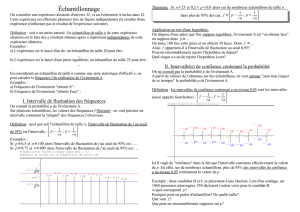
3.Estimation d`une moyenne

STATISTIQUES
Estimation d’une moyenne
Sept.-Nov.2010
Bruno Depay

Rappels du cours précédent
Variables :
–Qualitatives (modalités)
–Quantitatives
Mesure de la tendance centrale :
–Moyenne, médiane
Mesure de la dispersion :
–Étendue, quartile, distance interquartile
–Variance, écart-type

Rappels du cours précédent
Représentations
Variable qualitative (fréquence des modalités)
–Diagramme à barres
–Diagramme circulaire
Variable quantitative
–Histogrammes
–Boîte à moustaches

Rappels : Loi normale N(µ,σ)
Moyenne de X = µ
Variance de X = σ
2
95% des valeurs de X sont dans
[µ- 1.96σ; µ+ 1.96σ]

Estimation d’une moyenne
Problème :
Comment passer d’un échantillon à l’ensemble
de la population ?
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
1
/
43
100%