Implémentation d`un système de reconnaissance automatique

1
2emes JOURNEES DU LABORATOIRE DE COMMUNIPARLEE ET DE TRAITEMENT DES SIGNAUX
(JLCPTS 2015)
Résumé — Dans cet article, nous avons élaboré un système de
Reconnaissance Automatique de la Parole Visuelle (RAPV) par
les Supports à Vecteurs Machines (SVM) comme méthodes de
reconnaissance. Nous avons utilisé plusieurs méthodes de
paramétrisation du signal parole visuel, pour trouver la meilleure
méthode qui s’adapte mieux à la base de données utilisée ainsi
que le système de reconnaissance. La première méthode est
l’approche par estimation du gradient qui nécessite plusieurs
prétraitements, la deuxième méthode est basée sur les contours
actifs par approche des ensembles de niveaux, elle permet une
estimation moyenne des contours extérieurs des lèvres, mes ne
permet pas d’avoir une bonne détection sur tout la base de
données, car ces paramètres change d’une image à une autre.
Nous avons opté pour la DCT comme solution à nos problèmes,
elle a permet d’avoir un très bon taux de reconnaissance.
Mots clés— RAP visuelle, SVM, contours actifs, DCT.
I. INTRODUCTION
a parole est un moyen de communication. Le message
parlé est plus intelligible quand il est accompagné de la
vision des lèvres du locuteur, surtout quand le milieu de
transmission est dégradé [1].
Dans le cadre de la communication homme-machine, le
signal visuel des lèvres parlantes peut s’appréhender à la fois
comme modalités d’entrée et de sortie. La machine peut lire
sur les lèvres en intégrant des paramètres labiaux dans les
systèmes de RAP visuelle et réduire considérablement sa
sensibilité au bruit ambiant. L’enjeu est d’isoler et de
caractériser les gestes de parole produits par les lèvres.
Pour pouvoir utiliser la parole visuelle dans les applications
réelles [3], il semble nécessaire d’étudier l’extraction des
paramètres labiaux sur des images en niveau de gris acquises
sans préparation du locuteur dans un environnement réaliste
soumis à des variations d’éclairement.
Dans ce travail nous nous intéressons à la RAP visuelle, et
cela par l’utilisation de différentes méthodes de caractérisation
du signal visuel de parole, ainsi que l’utilisation d’un moteur
de reconnaissance ‘’les machines à vecteurs de support’’
désignées par SVM (Support Vector Machines) qui permet
d’avoir des résultats satisfaisants et d’amélioré celles qui font
l’objet de ce travail.
II. SYSTEME DE RECONNAISSANCE AUTOMATIQUE DE LA PAROLE VISUELLE
Comme le montre le schéma synoptique de la figure 1, un
système de RAP visuelle nécessite une base de données qui
contient l’information du signal parole. Dans le cadre de cette
étude il s’agit d’une base de données audiovisuelle. Ce
système comprend trois phases : phase de lecture du signal
visuel de la base de données audiovisuelle, phase de
prétraitements et traitements du signal visuel et la phase de
reconnaissance. Une fois le signal de parole est caractérisé, on
passe à l’étape de la reconnaissance par SVM qui attribue
chaque information à une classe selon un processus
d’apprentissage qui va classifier chaque mot ou chaque chiffre
à sa place selon l’application utilisée.
III. PARAMETRISATION DU SIGNAL PAROLE VISUEL
A. Définition du signal parole visuel
Les caractéristiques visuelles d’un signal parole reposent
sur la lecture labiale qui permet de comprendre le message
parlé en mettant en relation les mouvements des lèvres. Un
signal audiovisuel est représenté dans un signal vidéo
numérique qui contient les deux informations acoustique et
visuelle, la paramétrisation du signal visuelle revient à extraire
l’information visuelle de la vidéo.
B. Méthodes d’analyse du signal visuel
La RAP visuelle a pour objet la transformation automatique
d’un signal vidéo en image puis évaluer les différents
changements issus des mouvements des lèvres pour les
traduire, idéalement, au mot prononcé par un locuteur.
Le traitement visuel de la parole regroupe l’acquisition du
signal visuel, son débruitage et l’extraction des coefficients
caractéristiques de ce signal. Donc, le signal parole est
représenté par une suite de vecteurs qui constituent
l’information relative au mouvement des lèvres de chaque
image dans une séquence vidéo. Nous allons aborder
différentes approches : une approche pour la détection de
contour classique et une autre pour la détection de contour
actif : ensemble de niveaux (level set ) et la DCT.
Implémentation d’un système de reconnaissance
automatique de la parole visuelle par les SVMs
Nadia BAKIR1, Mohammed DEBYECHE2 et Abderrahmene AMROUCHE2
L
Fig. 1. Schéma global d’un système RAP visuelle.

2
2emes JOURNEES DU LABORATOIRE DE COMMUNIPARLEE ET DE TRAITEMENT DES SIGNAUX
(JLCPTS 2015)
1) Approche classique
a) Prétraitements
Les prétraitements sont faits par des étapes successives
comme elles sont présentées dans la figure 2.
Filtrage gaussien : On applique un filtrage gaussien
d’un ecart type sigma=5 (Fig. 2)
Application du masque 1
0
1 à l’image filtrée (Fig.3).
Seuillage : Comme on peut le voir sur
l’histogramme de l’image prétraitée (seuil=0).
Sur la figure 5, on voit bien l’effet de bord créé par le
filtrage gaussien, ce qui va générer par la suite des contours
artificiels, et ça engendrera une information redondante sur le
processus de reconnaissance. Pour remédier à cela, un
redimensionnement de l’image pour éliminer ce problème.
b) Détection de contour
On a utilisé 6 filtres représentés sur la figure 8. Comme on
peut le voir, les frontières des lèvres inférieures ne sont pas
détectées, ce qui ne caractérise pas l’information relative à la
séquence vidéo du mot prononcé.
Malgré les prétraitements utilisés, on n’a pas pu avoir une
bonne détection des contours des lèvres. Comme on l’a
appliqué.
La figure ci-dessus représente les meilleurs résultats
obtenus pour la détection des contours des lèvres.
La méthode utilisée concernant l’approche classique est
illustrée dans l’organigramme suivant :
2) Approche par détection de contour actif (level set)
La deuxième méthode utilisée est la méthode des contours
actifs.
Le principe général de l’algorithme des contours actifs
utilisés, est d’initialiser une courbe dite zero level set, et puis
faire subir une évolution (déformation de la courbe) jusqu'à
atteindre le contour extérieur des lèvres, et cela grâce à la
minimisation d’une fonctionnelle d’énergie.
L’implémentation de l’algorithme à notre base de données
est présentée dans l’organigramme de la figure 10.
3) Caractérisation par la DCT
Comme cette méthode est déjà faite dans les travaux
précédents [3], on applique la DCT sur les images des lèvres.
La dimension de l’image est de 80x60, où sont conservés
seulement 500 coefficients de basses fréquences.
Ainsi les tailles des vecteurs caractéristiques sont comme
suit : - Base d’apprentissage [63, 500,150]
- Base de test [63, 500, 100]
Fig. 2. Image filtrée avec sigma=5
Prewitt canny zerocross
Sobel Roberts log
Fig.8 Détection des contours des lèvres avec plusieurs filtres.
Fig. 3. Application du masque Fig. 4. Histogramme de
vertical à l’image filtrée. l’image 2.
Fig.5 Effets de bord
Fig. 6 Redimensionnement de Fig. 7 Image seuillée.
l’image traitée.
Fig. 9. Organigramme de l’algorithme de la paramétrisation du signal
visuel par la méthode classique
Fig. 10. Organigramme de l’algorithme de la paramétrisation du signal
visuel par la méthode des contours actifs.

3
2emes JOURNEES DU LABORATOIRE DE COMMUNIPARLEE ET DE TRAITEMENT DES SIGNAUX
(JLCPTS 2015)
IV. MÉTHODE DE RECONNAISSANCE ‘’SVM’’
A. Principe de fonctionnement
1) Notions de base : hyperplan, marge et support vecteur
Pour deux classes d’exemples donnés, le but du SVM est de
trouver un classificateur qui va séparer les données et
maximiser la distance entre deux classes.
Dans le figure si dessus, on détermine un hyper plan qui
sépare les deux ensembles de points.Les points les plus
proches, qui seuls sont utilisés pour la détermination de
l’hyperplan, sont appelés vecteurs de support.
On appelle la distance marge entre l’hyperplan et les
exemples. L’hyperplan séparateur optimal est celui qui
maximise la marge. Comme on cherche à maximiser cette
marge, on parlera de séparateur à vaste marge.
2) Linéarité et non-linéarité
Parmi les modèles des SVM, on constate les cas
linéairement séparable et les cas non linéairement séparable.
Les premiers sont les plus simples de SVM. Dans la plupart
des problèmes réels il n’y a pas de séparation linéaire possible
entre les données, le classificateur de marge maximale ne peut
pas être utilisé car il fonctionne seulement si les classes de
données d’apprentissage sont linéairement séparables. [ref23]
Cas non linéaire :
Pour surmonter les inconvénients des cas non linéairement
séparables, l’idée des SVM est de changer l’espace de
données. La transformation non linaire des données peut
permettre une séparation linéaire des exemples dans un nouvel
espace. On va donc avoir un changement de dimension. Cette
nouvelle dimension est appelé espace de re-description.
En effet, intuitivement, plus la dimension de l’espace de re-
description est grande, plus la probabilité de pouvoir trouver
un hyperplan séparateur entre les exemples est élevée.
a) Extensions des SVMs aux problèmes multi-
classes
Les SVMs sont des classifieurs binaires permettant de
séparer deux classes de données uniquement. Leurs
extensions aux problèmes multi-classes peuvent être établies
selon différentes approches procédant toutes par la
combinaison de plusieurs SVMs. [ref25] telles que :
- L’approche un contre tous (OAA : One-Against-All) : dans
laquelle chaque SVM est entrainé par séparer une classe de
toutes les autres classes).
- L’approche un contre un (OAO: One-Against-One) : C’est
une méthode dite de un contre un, au lieu d’apprendre N
fonction de décision, chaque classe est discriminé d’une autre.
V. EXPERIENCES ET RESULTATS
A. Base de données
La base de données utilisée est une base audiovisuelle
comportant des chiffres arabes isolés prélevés à une fréquence
d’échantillonnage de 16 KHz et 25 images/s. Elle est
constituée de 25 répétitions des 10 mots isolés (siffer, wahed,
ithnani, thalatha, arbaa, khamssa, sitta, sabaa, thamania,
tissaa) prononcés par une seule locutrice arabisante. Donc
c’est une base monolocuteur, elle a été apprise sur le mot à
reconnaître pour le même style de corpus de parole. A savoir
des séries de dix mots des chiffres arabes tirés aléatoirement,
sans répétition, appelés en élocution continue [3].
La figure suivante présente le schéma synoptique du banc
d’acquisition :
Normalisation
Une normalisation de la base de données s’impose pour
simplifier la tâche à l’algorithme de traitement et de
reconnaissance.
En premier, lieu on fait la lecture de la base de données et
dans chaque lecture en sauvegarde le nombre d’images dans
chaque clip et on fait une comparaison dans tout l’ensemble de
la base afin de déterminer le nombre maximum d’images. Une
fois le nombre maximum est déterminé, on procède à la
normalisation, on décompose le clip vidéo en images et on
stock ces images dans une matrice de telle sorte que si le
nombre d’images du clip lu est inférieur au nombre maximum,
en ajoutant N fois la dernière image du clip.
La matrice finale est de 4 dimensions (hauteur, largeur,
nombre d’images maximal, nombre de clips).
L’apprentissage des modèles visuels se fait par estimation
Fig. 11. Hyperplan séparateur optimal.
Fig. 12. Cas linéairement et non linéairement séparable.
Fig. 14. Schéma synoptique pour l’approche un contre un OAO.
Fig. 15. Schéma synoptique du banc d’acquisition [2]
Fig. 3. Schéma synoptique pour l’approche un contre tous (OAA).

4
2emes JOURNEES DU LABORATOIRE DE COMMUNIPARLEE ET DE TRAITEMENT DES SIGNAUX
(JLCPTS 2015)
de leurs paramètres sur un corpus dit ‘’Apprentissage’’ qui
doit être disjoint du corpus dit ‘’Test’’. Nous avons utilisé
60% de la base pour l’apprentissage et 40% pour le test.
B. Schéma synoptique
Le schéma général du système implémenté est donné par la
figure 1.
Comme nous l’avons expliqué dans le schéma général du
système de reconnaissance représenté par la figure 1, la base
de données est divisée en deux: base Test et base
Apprentissage, et après la normalisation de la base de données
les tailles des deux matrices sont comme suit :
la matrice de la base Apprentissage est de [60,80,63,150].
la matrice de la base Test est de dimension [60,80,63,100].
Avant tout, on va chercher les caractéristiques des images
de la base de données visuelles.
Comme le montre la figure 17.a, il s’agit de la première
image d’un clip de la base de données audiovisuelle,
évidement les lèvres sont fermées.
Après les modifications sur l’histogramme (Figure 17.d), on
obtient l’image représenté dans la figure 17.c, on constate que
les lèvres supérieures sont confondues avec la partie inférieure
des lèvres inférieures, qui sont confondues avec le reste de
l’image. Cela est dû à la mauvaise acquisition de la base de
données.
C. Résultats par la détection des contours actifs
Avant toute chose, on applique un filtre gaussien de l’écart-
type 1 sur l’image, et on redimensionne l’image pour éliminer
l’effet de bord. Comme le montre la figure 19.a, on initialise la
fonction level set (rectangle en rouge).
On applique l’évolution avec les paramètres suivants :
=1.5 , = 0.04 , =5 , =1, nombre d’itérations =500.
Sur la figure 19.a la fonction level set finale est représentée
en rouge sur l’image originale. On peut dire quand à une
détection moyenne des contours extérieurs des lèvres.
On refait le même travail sur des lèvres ouvertes avec les
mêmes paramètres. Le résultat final sur des lèvres ouvertes est
mauvais comme le montre la figure 4.19.b, par rapport au
résultat obtenu sur les lèvres fermées.
On filtre maintenant l’image avec le masque vertical après
le redimensionnement, et on applique l’algorithme comme il
est présenté sur la figure 10.
Comme on peut le voir sur les figures 20.c et 20.d,
l’initialisation de la fonction level set sur l’image filtré par le
masque vertical.
Les figures 20.c et 20.d nous montrent le contour final sur
les images originales respectivement lèvres ouverts et lèvres
fermés.
On peut dire que le contour est fermé par rapport au contour
de la figure 19 mais il est moins précis par rapport au contour
de la figure 8.
Discussion
La caractérisation du signal visuel de la parole avec les
Fig. 16. Schéma synoptique du système de RAP visuelle par SVM
mis en œuvre.
Fig. 19.a : Initialisation de la fonction Fig. 19.b : Contour final
level set sur des lèvres ouvertes. après 500 itérations.
Initial contour
10 20 30 40 50 60 70
5
10
15
20
25
30
35
40
45
Fig. 20.a : Initialisation de la fonction Fig. 20.b : Contour final
level set (levres fevres ouverts)
Fig. 20.c : Initialisation de la fonction Fig. 20.d : Contour final
level set (levres fevres fermés)
Initial contour
10 20 30 40 50 60 70 80
5
10
15
20
25
30
35
40
45
Fig. 17.a : Image originale 17.b : Histogramme du l'image originale
Fig. 17.c : Image modifié. 17.d : Modification de l'histogramme.
Fig. 4.18.a : Initialisation de la fonction Figure 4.18.b : Contour final
level set sur des lèvres fermes. avec 500 itérations.
Initial contour
10 20 30 40 50 60 70
5
10
15
20
25
30
35
40
45

5
2emes JOURNEES DU LABORATOIRE DE COMMUNIPARLEE ET DE TRAITEMENT DES SIGNAUX
(JLCPTS 2015)
deux méthodes proposées ont données de résultats un peu
satisfaisants et cela à cause des conditions réels d’acquisition
du signal visuel. On a vu que pour la détection de contours
avec l’approche classique nécessite plusieurs prétraitements
pour détecter les contours intérieurs et extérieurs des lèvres.
La deuxième méthode nous a révélé que ces paramètres
changent d’une image à une autre, d’une image où les lèvres
sont fermées à une image où les lèvres sont ouvertes. On se
retrouve à poser le problème suivant : est-ce-qu’on peut faire
une meilleure paramétrisation sur toute la base de données
sans faire des changements manuels des paramètres avec
moins de prétraitements.
La méthode qui répond à tous ces contraintes est la DCT.
D. Résultats de la classification
On va présenter les résultats de la classification par les
SVMs sur les résultats de la caractérisation par la DCT.
Les matrices d’entrés des SVMs doivent être représenté en
2-D, or que les taille des matrice sont en 3-D.
Les matrices contenant les caractéristiques visuelles des
deux bases respectivement Apprentissage et de Test sont
réorganisées comme suit :
Base Aapprentissage: [150, 63*500].
Base Test: [100, 63*500]
Ou chaque ligne de la matrice (d’apprentissage ou de test)
représente les 500 coefficients des 63 images d’un clip, c.-à-d.,
une ligne représente la caractérisation d’une répétition d’un
chiffre.
Les résultats de la classification sont représentés par le
paramètre Taux Moyen de Bon Reconnaissance ‘’TMBR’’ :
=
éé
Avec: N: nombre de classes = 10.
Nombre de répétitions = 15 (Apprentissage) et 10 (Test).
a) Classification par noyaux
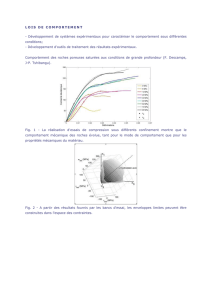
La figure 21 présente l’influence des différents noyaux sur
le TMBR pour chaque chiffre, ou le système à fait une erreur
de 10% pour le chiffre 7 pour les noyaux Linéaires et RBF, et
pour remédier à cette erreur, on applique le noyau linéaire à la
classe d’erreur et le noyau RBF sur les autres classes. On
obtient résultat meilleur TMBR = 100%.
On peut représenter l’influence du type de noyaux sur le
TMBR global par la figure ci-dessous.
VI. CONCLUSION
Notre travail présenté dans ce document a porté sur la RAP
visuelle. Nous avons ainsi abordé les principaux problèmes de
la RAPV, à savoir la paramétrisation des informations de
parole et la nature du système de Reconnaissance.
Nous avons choisi pour résoudre ces problèmes en
appuyant sur des travaux réalisés dans le domaine de la
perception visuelle de la parole.
Nous nous sommes intéressés, en premier temps, à
l’extraction des paramètres visuels. Elles sont calculées sur
des images fixes basées sur la forme et les mouvements des
lèvres, et paramétrées par trois méthodes :
La premier est la détection de contour par estimation de
gradient (Approche classique), la deuxième méthode est la
détection des contours actifs par la formulation Level Set et la
dernier méthode c’est la DCT (Discret Cosine Transform).
Nous avons ensuite mis en œuvre le système de RAP visuelle
fondé sur le module de reconnaissance SVMs.
Aux cours de l’évaluation de notre système, on a constaté
que la méthode de paramétrisation classique ne donne pas de
bonne résultats, car cette méthode permet de détecter tous les
contours présents dans l’image, ainsi il nous a fallu employer
plusieurs prétraitements, mes la nature de la base de données
utilisée (milieu réel) a engendré plusieurs problèmes liés à la
détection des contours des lèvres. Par contre la méthode Level
Set permet plus ou moins de détecter les contours extérieurs
des lèvres, mais ces paramètres changent d’une image à une
autre. Pour remédier à ces problèmes, on a utilisé la DCT qui
nous a donné un TMBR (Taux Moyen de Bonne
Reconnaissance) égale à 100%.
La DCT reste toujours la meilleure approche pour la
caractérisation des images par rapport aux autres méthodes.
REFERENCES
[1] Alexandrina ROGOZAN, ‘Etude de la fusion des données hétérogènes
pour la reconnaissance automatique de la parole audiovisuelle’
,Thèse PHD, Ecole doctorale en électronique de l’université d’Orsay,
Paris, 1999.
[2] N. BAKIR, . DEBYECHE, Y. CHIBANI, ‘’Reconnaissance
automatique des chiffres arabes en milieu réel par fusion
audiovisuelle’’, 10ème Congrès Français d'A
coustique, Lyon, France,
Avril 2010
[3] BAKIR Nadia. ‘ Reconnaissance automatique de la parole par fusion
audiovisuelle dans un milieu réel’,Thèse de Magister en Électronique
Spécialité : Communication Parlée, USTHB 2008.
[4] Bovik A., "Handbouk of Image and Video
Processing", Academic Press, p891 (2000).
[5] Harshit Mehrotra, Gaurav Agrawal and M.C. Srivastava,’’ Automatic
Lip Contour Tracking and Visual Character Recognition for
Computerized Lip Reading’’, International Journal of Computer Science
4:1 2009.
Fig. 21. Influence du noyaux sur le TMBR pour chaque chiffre
Fig. 22. Comparaison des differents noyaux du SVM sur le TMBRG.
1
/
5
100%



![III - 1 - Structure de [2-NH2-5-Cl-C5H3NH]H2PO4](http://s1.studylibfr.com/store/data/001350928_1-6336ead36171de9b56ffcacd7d3acd1d-300x300.png)