cours1_rsd_reparti_model


2
Plan général
Introduction aux systèmes distribués
Pré requis
Programmation réseau en Java : Socket
Temps dans un système distribué
Algorithmique distribuée
Exclusion mutuelle distribuée
Diffusion atomique
Élection d’un maître
Consensus
Transaction
Propriété stable : terminaison distribuée d’une application répartie
Introduction aux composants logiciels (JavaBeans)
Introduction aux Java Server Pages (JSP)

3
Plan
Partie I : Systèmes distribués
Définition
Objectifs
Avantages
Inconvénients
Applications réparties
Partie II :Communication dans un système distribué
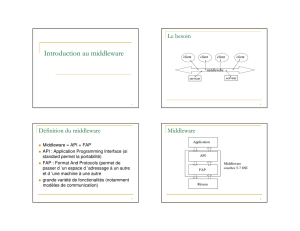
Middleware (intergiciel)
Modèles de communication
Client/serveur
Diffusion de messages
Pair à pair (peer to peer)
Type de communication
Synchrone
Asynchrone

4
Plan
Partie III : Algorithmique distribuée
Voies d’études des systèmes distribués
Éléments de base d’un système distribué
Modèles conceptuels de systèmes distribués
Modèle d’interaction
Modèle de fautes
Franches
Par omission
Arbitraires ou byzantines
Détecteur de pannes
Classification
Réalisation

5
Partie I :
Systèmes distribués
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
1
/
64
100%