ELE MET-DON 8162

Méthodologie de l’observation
Partie B
Statistiques
Cours 4

Recherche de description
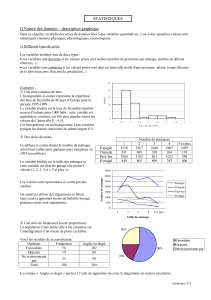
•Rappel = décrire les caractéristiques (les distributions)
d’une ou plusieurs variables mesurées sur un échantillon
ou une population.
•2 caractéristiques à dégager :
–les indices de tendance centrale des données
–les indices de dispersion
•Présentation des informations et données
–les transformations possibles et nécessaires des
données
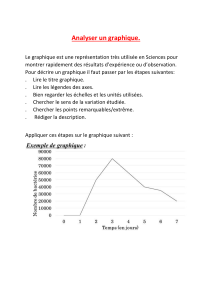
–les représentations graphiques des résultats

L’indice de tendance centrale
•= indique la caractéristique la plus représentative de
tous les individus du groupe en la ramenant à un individu
type qui se situerait au « centre » de la distribution
•Il rend possible la comparaison entre des groupes
d’individus différents sur base de la mesure d’une même
variable
•Ex : les éléphants d’Afrique ont « en moyenne » une
masse supérieure à celle des éléphants d’Asie

L’indice de dispersion
• = exprime l’étendue de la variabilité des observations
•Les données peuvent être concentrées autour de la
tendance centrale ou au contraire très dispersées
Exemple :
• un groupe d’élèves (classe A) avec une moyenne de
10/20 mais dont les résultats en fin d’année s’étendent
de 5/20 à 18/20
• un groupe d’élèves (classe B) avec une moyenne de
10/20 mais dont les cotes s’établiraient de 9/20 à 14/20
La classe A a un indice de dispersion supérieur à la
classe B

Les indices de tendance centrale
•Echelle nominale le mode
•Echelle ordinale la médiane
•Echelle intervalle la moyenne
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
1
/
39
100%