Modéliser un critère par un réseau bayésien : V

Modéliser un critère par un réseau
bayésien : V-structure et observations
probabilistes fixes
Véronique Delcroix1, Ali Ben Mrad2
1. LAMIH UMR 8201,
UVHC Valenciennes, France
veronique.delcr[email protected]
2. CES
université de Sfax, Tinisie
RÉSUMÉ. Cet article propose un système à base de réseaux bayésiens pour fournir des recom-
mandations dans le cadre des problèmes récurrents d’aide à la décision multicritères. Chaque
critère de choix est modélisé par une V-structure dans le graphe du RB. Les auteurs mettent
en évidence l’intérêt de découper le RB et d’utiliser des observations probabilistes fixes afin de
produire le raisonnement attendu.
ABSTRACT. This paper proposes a system composed of Bayesian networks in order to provide
recommendations in recurrent multicriteria decision problems. Each criterion is modeled by
a V-structure in the graph of the BN. The authors highlight the interest of cutting the BN and
using fixed probabilistic evidence to produce the waited reasoning
MOTS-CLÉS : observation probabiliste, réseau bayésien, observation de vraisemblance, aide à la
décision multicritères
KEYWORDS: probabilistic evidence, bayesian network, likelihood evidence, soft evidence,MCDA
DOI:10.3166/RIA.-.1-18 c
2016 Lavoisier
Revue d’intelligence artificielle – no-/2016, 1-18

2 RIA. Volume - – no-/2016
1. Introduction
La modélisation d’un critère est utile dans les problèmes de décision où un ou plu-
sieurs critères de choix doivent être pris en compte. Chaque critère oriente la décision
suivant une direction. Dans cet article; nous considérons un critère comme une qualité
positive que l’on cherche systématiquement à optimiser. Par exemple, lors du choix
d’une voiture, le critère associé au prix est l’adéquation entre le prix de la voiture et
le montant disponible, et cette adéquation doit toujours être la meilleure possible. Un
critère peut aussi être associé à un risque ou un niveau de gravité.
Nous considérons ici les problèmes de décision récurrents et multicritères . La
spécificité de ces problèmes est qu’ils concernent tout type de décideurs (Monsieur
"tout le monde"). Nous considérons une étape très amont du processus de décision
qui vise à aider le décideur à cibler un ensemble d’alternatives potentielles à l’aide
d’un système de recommandations sur les caractéristiques les plus pertinentes des
alternatives en fonction de son cas de décision. Ce système de recommandation basé
sur des réseaux bayésiens est présenté dans (Delcroix et al., 2013).
Dans cet article, nous proposons de modéliser chacun des critères de choix à l’aide
de trois noeuds formant une V-structure dans un réseau bayésien. Cette structure peut
être utilisée pour évaluer une alternative sur un critère dans un cas de décision spéci-
fique, mais aussi pour fournir des recommandations adaptées au cas considéré en vue
de satisfaire le critère.
Nous expliquons pourquoi l’utilisation de ce type de réseau bayésien en vue de
fournir des recommandations sur les alternatives nécessite quelques précautions. En
effet, il est nécessaire de limiter la propagation vers les noeuds susceptibles de faire
l’objet de recommandation. Pour cela, nous proposons d’utiliser des observations pro-
babilistes afin de fixer les distributions de probabilités des variables non observées qui
ne doivent pas faire l’objet d’une recommandation. Ce type d’observation est spécifié
par une distribution locale de probabilités sur une variable qui reflète la croyance sur
cette variable après propagation de l’information dans le réseau. Le fait d’imposer une
distribution de probabilités fixe revient à modifier temporairement le modèle, puisque
les a priori sur les variables concernées par les observations probabilistes fixes sont
temporairement remplacés. D’un coté, ce type d’observations soulève des critiques
dans la communauté des modèles graphiques probabilistes car il ne s’agit pas d’un
événement eque l’on peut propager en calculant P(.|e); d’un autre coté, il existe
une réelle demande pour ce type d’observations (Bloemeke, 1998 ; Valtorta et al.,
2002 ; Baldwin, Tomaso, 2003 ; Arsene et al., 2015).
Dans la partie suivante, nous introduisons les problèmes récurrents d’aide à la dé-
cision multicritères, et nous expliquons leur spécificité. Puis dans la partie 3, nous pré-
sentons la modélisation d’un critère à l’aide d’une V-structure et son utilisation pour
évaluer et pour recommander. Nous expliquons et illustrons les problèmes rencontrés
pour fournir des recommandations sur les alternatives en utilisant le RB de façon clas-
sique. La partie 4 concerne la solution proposée avec des observations probabilistes
fixes et les résultats obtenus sur un exemple jouet d’aide à la décision multicritère.

Modèle d’un critère dans un RB 3
2. Problème récurrent d’aide à la décision multi-critères
2.1. Présentation
Un problème de décision récurrent est un problème de décision qui est répété
plusieurs fois dans des contextes différents et avec différents acteurs, mais toujours
avec le même type d’alternatives et les mêmes critères de choix. Les problèmes de
décision récurrents sont caractérisés par le fait qu’ils concernent tout type de décideur.
En effet, chaque occurrence de la décision implique un ensemble d’acteurs différents
avec leur contraintes propres, et dans un contexte spécifique. L’importance de chaque
critère et l’évaluation d’une alternative en fonction d’un critère donné dépendent de
chaque cas de décision. Ces problèmes sont aussi caractérisés par l’absence possible
d’un expert, capable d’évaluer une alternative sur un critère ainsi que l’importance des
critères qui dépend de chaque cas de décision, ce qui rend plus utile encore d’apporter
de l’aide au décideur(s). Nous considérons les problèmes multi-attributs dans lesquels
les alternatives sont caractérisées par un ensemble d’attributs fixes.
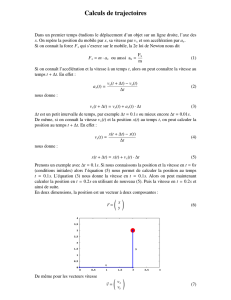
FIGURE 1. Exemples de paramètres intervenant dans le choix d’un véhicule
La figure 1 montre quelques uns des paramètres qui entrent en jeu lorsqu’une per-
sonne choisit une voiture. Les réseaux bayésiens sont bien adaptés pour la modéli-
sation des problèmes récurrents de décision car ils permettent de représenter et de
raisonner avec l’incertitude et d’apporter au décideur une information et des recom-
mandations adaptées à son cas.
2.2. Spécificité des problèmes récurrents d’aide à la décision multicritère
Les problèmes et les méthodes d’aide à la décision multicritère (ADMC) repré-
sentent un champs de recherche déjà bien étudié. Nous expliquons ci-dessous pour-
quoi ces méthodes ne sont pas adaptées aux problèmes récurrents d’ADMC que nous
abordons, de même que d’autres outils d’aide à la décision comme les diagrammes
d’influences.
Un premier élément à considérer concerne le décideur. Dans les problèmes de dé-
cision récurrents, le décideur est parfois "ignorant" et n’est pas toujours accompagné

4 RIA. Volume - – no-/2016
d’un spécialiste. De ce fait, il ne peut être sollicité de façon importante et systéma-
tique sur des questions qui requièrent de l’expertise. Au contraire, les méthodes multi-
critères reposent sur l’idée d’utiliser les préférences du décideur pour différencier les
solutions et l’aider dans le processus de décision. Dans notre approche, le décideur
n’est sollicité que pour fournir des informations sur les éléments concernant son cas
de décision et qui peuvent entrer en jeu dans la décision : ses caractéristiques, ses
contraintes, ses besoins, le contexte, etc.; en revanche il n’a pas à donner ses préfé-
rences en termes de comparaison d’alternatives relativement à des critères, ce qui peut
demander une certaine expertise. Dans notre exemple très simplifié sur le choix d’une
voiture, tous les acheteurs ne sont pas capables de classer deux voitures données en
termes de satisfaction relativement à l’accélération, ou sur d’autres critères comme par
exemple ceux qui impactent sur le type de carburant.
Deuxièmement, la plupart des méthodes d’ADMC supposent que l’on dispose a
priori d’une liste de solutions potentielles de taille "raisonnable". Notre proposition se
situe plus en amont dans le processus de choix et ne nécessite pas que le décideur ait
dès le départ une liste d’alternatives. Au contraire, les recommandations sur les carac-
téristiques des alternatives fournies par notre approche peuvent constituer un point de
départ pour établir une telle liste d’alternatives. Concrètement dans notre exemple, une
personne désireuse de choisir une voiture pourrait dans un premier temps obtenir des
recommandations sur les caractéristiques d’un véhicule adapté à ses besoins grâce à
notre proposition; puis tirer parti de ces recommandations pour établir une liste de vé-
hicules pertinents pour son cas; et enfin, exploiter une méthode d’ADMC pour classer
ces véhicules, ou sélectionner le ou les meilleurs.
D’autres modèles graphiques probabilistes, dont les diagrammes d’influence sont
dédiés à l’aide à la décision. Ces modèles permettent de traiter des problèmes de dé-
cision séquentiels, dans lesquels chaque décision comporte un nombre limité d’al-
ternatives. Dans les problèmes de décision récurrents que nous traitons, la liste des
alternatives n’est pas connue a priori. Dans notre exemple sur le problème récurrent
de l’aide au choix d’une voiture, un noeud de décision d’un diagramme d’influence
pourrait comporter une liste de voitures réelles, dont toutes les caractéristiques seraient
connues (options, etc). S’il s’agit d’une liste commune à tous les cas de décision, sa
taille est immense; et si elle est spécifique à chaque cas de décision, c’est un travail
préalable qui est demandé au décideur, or notre proposition vise au contraire à aider à
obtenir une telle liste restreinte et spécifique.
Une autre approche pourrait considérer le choix des valeurs des caractéristiques
des alternatives comme autant d’étapes dans la décision. Cependant, les diagrammes
d’influence imposent de déterminer un ordre fixe sur les décisions, ce qui n’est pas per-
tinent pour le choix des caractéristiques des alternatives (par exemple le type de voi-
ture, puis la marque, etc.). La comparaison des réseaux bayésiens et des diagrammes
d’influence pour les problèmes récurrents d’ADMC a été discutée dans (Sedki, Del-
croix, 2012).
En résumé, notre approche se situe à une phase très amont du processus de décision
pour des problèmes d’ADMC récurrents, en vue de fournir des recommandations sur

Modèle d’un critère dans un RB 5
les caractéristiques des alternatives qui soient adaptés à la spécificité de chaque cas de
décision. Cet ensemble de recommandations peut ensuite être utilisé pour sélectionner
un sous-ensemble d’alternatives de taille raisonnable qui constitue le point de départ
de l’étape suivante du processus de décision.
3. Principe du réseau bayésien pour les problèmes récurrents d’aide à la
décision multicritères : structure du graphe et utilisation
L’idée d’utiliser une V-structure pour modéliser un critère dans un réseau bayésien
(RB) n’est pas nouvelle (Fenton, Neil, 2001 ; Leicester et al., 2013), mais elle n’est
pas clairement formalisée.
3.1. Modélisation d’un critère de décision par une V-structure dans un RB
Le principe de la V-structure pour représenter un critère est représenté sur la fi-
gure 2 : un noeud sans enfants représente l’indice de satisfaction du critère. Il peut
aussi représenter un degré d’adéquation entre une contrainte liée au cas de décision
et une caractéristique (directe ou dérivée) de l’alternative. Cet indice est une valeur
entre 0 et 1 où 1 représente une satisfaction maximale du critère. Pour des raisons de
facilité, nous représentons cet indice dans pyAgrum par une variable “quasi continue”,
c’est à dire une variable entière variant dans un intervalle. Nous avons choisi l’inter-
valle [1,10] car il faut faire un compromis entre précision et taille du modèle. De ce
fait, les variables satAcceleration et adeqPrix de notre exemple représentent l’indice
de satisfaction multiplié par 10.
Le degré de satisfaction d’un critère dépend d’une part des caractéristiques de l’al-
ternative, et d’autre part de l’importance de ce critère ou de contraintes spécifiques à
chaque cas de décision. Ces facteurs sont représentés par les deux noeuds parents de
la V-structure. Le parent représenté à gauche concerne le cas de décision et nous l’ap-
pellerons parfois le parent gauche. Ces deux noeuds parents peuvent être des indices,
comme ci-dessous pour le critère accélération, ou l’importance et l’indice sont des
valeurs dans [0,10], ou bien des grandeurs de même unité, comme le prix du véhicule
et le montant disponible.
FIGURE 2. V-structure pour modéliser un critère dans le graphe du réseau bayésien
 6
7
8
9
10
11
12
13
14
15
16
17
18
6
7
8
9
10
11
12
13
14
15
16
17
18
1
/
18
100%