Algorithmes de partitionnement, modèles de mélange

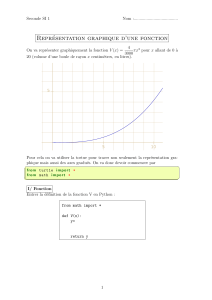
30/70 Repr´
esentation Clustering Approches probabilistes ´
Evaluation PLSA
D´
efinitions
qSoit Gune partition d’une collection Cdonn´
ee de N
documents. Un ´
el´
ement de Gest appel´
e un groupe (ou
classe). Un groupe correspond donc `
a un sous-ensemble
des documents de C. Un groupe d’une partition Gsera de
plus not´
eGi,o
`
u1i|G|.
qLe partitionnement de documents a pour but l’identification
de groupes disjoints de documents au sein d’une collection
donn´
ee.
)On cherche, d’une part, `
a obtenir des groupes homog`
enes,
c’est-`
a-dire qui rassemblent des documents proches les
uns des autres, et, d’autre part, `
a´
eviter que des groupes
diff´
erents soient proches l’un de l’autre.
Massih-[email protected] 3A IF, WMMFB40
Vide

31/70 Repr´
esentation Clustering Approches probabilistes ´
Evaluation PLSA
Prototype
qSoit Giun groupe d’une partition G. On appelle
repr´
esentant (ou prototype) de Giun vecteur `
aV
dimensions rir´
esumant le groupe. Le centro¨
ıde ou centre
de gravit´
e du groupe est souvent utilis´
e comme
repr´
esentant.
Modèle
vectoriel Algorithme
de partitionnement
Collections*
de*documents
d
Documents
vectorisés
Groupe, G1
Groupe, G2
Prototypes
Massih-[email protected] 3A IF, WMMFB40
Vide

32/70 Repr´
esentation Clustering Approches probabilistes ´
Evaluation PLSA
Les ´
etapes du partitionnement
Le partitionnement d’un ensemble de documents en diff´
erents
groupes est en g´
en´
eral un processus it´
eratif au cours duquel
un utilisateur cherche `
a mieux comprendre le contenu d’une
collection. Ce processus passe par les ´
etapes suivantes:
1. Choix d’une mesure de similarit´
e et ´
eventuellement calcul
de la matrice de similarit´
e.
2. Partitionnement.
a. Choix de la m´
ethode de partitionnement.
b. Choix de l’algorithme de partitionnement.
3. Validation des groupes obtenus.
4. Retour `
a l’´
etape 2, en modifiant les param`
etres de
l’algorithme de partitionnement voire la m´
ethode de
partitionnement et l’algorithme associ´
e; ce retour est bien
sˆ
ur optionnel.
Massih-[email protected] 3A IF, WMMFB40
Vide

33/70 Repr´
esentation Clustering Approches probabilistes ´
Evaluation PLSA
Mesures de similarit´
e
Il existe plusieurs mesures de similarit´
e ou de distance, les plus
connues et les plus utilis´
ees sont:
qL’ indice de Jaccard, calcule la proportion de termes communs `
a
deux documents. Dans le cas de poids quelconques compris
entre 0 et 1, cet indice prend la forme:
simJaccard(d,d0)=
V
X
i=1
wid wid0
V
X
i=1
wid +wid0wid wid0
qLe coefficient de Dice prend la forme:
simDice(d,d0)=
V
X
i=1
wid wid0
V
X
i=1
w2
id +w2
id0
Massih-[email protected] 3A IF, WMMFB40
Vide

34/70 Repr´
esentation Clustering Approches probabilistes ´
Evaluation PLSA
Mesures de similarit´
e
qLe cosinus, lui, s’´
ecrit:
simcos(d,d0)=
V
X
i=1
wid wid0
v
u
u
t
V
X
i=1
w2
id v
u
u
t
V
X
i=1
w2
id0
qEnfin, la distance euclidienne est donn´
ee par:
disteucl(d,d0)=||dd0||2=v
u
u
t
V
X
i=1
(wid wid0)2
Cette distance est ensuite soit transform´
ee en similarit´
e, en
utilisant par exemple une valeur maximale (´
egale `
a la plus
grande distance observ ´
ee entre deux points ou arbitrairement
fix´
ee) `
a laquelle on retranche la distance entre deux documents.
Massih-[email protected] 3A IF, WMMFB40
Vide
 6
7
8
9
10
11
12
13
14
15
16
6
7
8
9
10
11
12
13
14
15
16
1
/
16
100%