Outils d`extraction d`informations à partir de documents numérisés

UNIVERSITÉ DE LA RÉUNION - M2
INFORMATIQUE
RAPPORT DE STAGE DE MASTER M2-INFORMATIQUE
Outils d’extraction d’informations à
partir de documents numérisés
Auteur :
MANGATA Nicky
31001630
Encadrants :
Jean DIATTA
Cynthia PITOU
9 juin 2015
1

Resume
Ce document est un rapport de stage dans le cadre d’un master 2 informatique à
l’Université de la Réunion située à St-Denis. Ce travail d’étude et de recherche
concerne un projet informatique et se fait sur une durée de 6 mois. Le projet
informatique effectué est encadré par deux experts en analyse de données et en
recherche : Cynthia PITOU et Jean DIATTA, ce projet concerne la mise en place
d’outils d’extraction d’informations à partir de documents numérisés et d’études
de méthodes de classifications sur ces informations. Ainsi dans une génération où
l’information numérisées joue un rôle primordial et où son volume ne cesse de
croitre, tirer le maximum de bénéfice de ces données par le biais de techniques,
d’outil et de technologies serait un atout considérable. Ce rapport mets donc en
avant plusieurs dispositifs permettant de générer des documents numérisés, d’or-
ganiser, de stocker, d’extraire et d’analyser des masses d’informations de ces do-
cuments numérisés afin de localiser celles qui seraient pertinentes relativement à
un besoin en information d’un utilisateur sans avoir eu au préalable des indications
sur son emplacement.
Mots clés : Data Mining , JAVA , classification supervisée, classification non
supervisée, méthodes d’évalutations, R, SQL.
Abstract
This paper is an internship report in connection with a last-year master’s degree
in computer sciences at the University of Reunion Island located in Saint-Denis.
This work of study and research involves a computer project and was done over
a period of six months. The IT project done was provided by two data mining
and research experts : Cynthia Pitou and Jean DIATTA, this project talk about
the implementation of data extract tool from scanned document and the study
of classifications methods on it. In this way, within a generation where scanned
data plays an crucial role and has a volume which are becoming more and more
important, obtaining the maximum of benefits of this data through methods, tools,
technologies will be a considerable asset. This report is therefore highlighting
devices allowing to generate scanned documents, organize, record, extract and
analyze wealth of information in order to locate those relevant in the context in an
informations needs to a user without any indications about the location.
Key-words : DataMining, java, clusterings, evaluation methods, r, sql.
2

Table des matières
1 Introduction 5
1.1 Contextedel’étude ......................... 5
1.2 Description du laboratoire d’accueil . . . . . . . . . . . . . . . . 6
2 Analyse des besoins et spécifications 8
2.1 Définition du problème . . . . . . . . . . . . . . . . . . . . . . . 8
2.2 Existant ............................... 8
2.3 Solutions apportées au projet . . . . . . . . . . . . . . . . . . . . 9
3 Développement 10
3.1 Outil de génération de facture automatisées . . . . . . . . . . . . 10
3.2 Basededonnées........................... 15
3.3 Générateur de fichier csv . . . . . . . . . . . . . . . . . . . . . . 17
4 Les méthodes de classification non supervisées 20
4.1 La méthode de classification ascendante hiérarchique . . . . . . . 20
4.1.1 Mise en oeuvre de la CAH avec la fonction agnes et le
critère d’agregation : "lien complet" . . . . . . . . . . . . 22
4.1.2 Mise en oeuvre de la CAH avec la fonction agnes et le
critère d’agregation : ward . . . . . . . . . . . . . . . . . 25
4.1.3 Comparaison entre la librairie agnes et la librairie stats . . 26
4.1.4 Exploitation des résultats . . . . . . . . . . . . . . . . . . 28
4.2 L’analyse en composante principale . . . . . . . . . . . . . . . . 30
4.2.1 Mise en oeuvre de l’ACP . . . . . . . . . . . . . . . . . . 30
4.3 K-means............................... 34
4.3.1 Mise en oeuvre de la méthode K-means . . . . . . . . . . 35
4.4 K-medoids.............................. 36
4.4.1 Mise en oeuvre de la méthode K-medoids . . . . . . . . . 36
5 Les méthodes de classification supervisées 38
5.1 Les Forêts aléatoires (ou Forêt Decisionnels) . . . . . . . . . . . 38
3

5.1.1 Mise en oeuvre de la forêt aléatoire . . . . . . . . . . . . 39
5.2 Les arbres de décisions . . . . . . . . . . . . . . . . . . . . . . . 41
5.2.1 Mise en oeuvre des arbres de décisions . . . . . . . . . . 42
5.3 Classification naïve bayésienne . . . . . . . . . . . . . . . . . . . 47
5.3.1 Mise en oeuvre de la classification naives bayésienne . . . 47
5.4 Les Règles d’Associations . . . . . . . . . . . . . . . . . . . . . 48
5.5 Mise en oeuvre des règles d’associations . . . . . . . . . . . . . . 48
5.6 Les méthodes d’évaluations . . . . . . . . . . . . . . . . . . . . . 49
5.6.1 Le taux d’erreur . . . . . . . . . . . . . . . . . . . . . . . 49
5.6.2 Mesure de performance . . . . . . . . . . . . . . . . . . . 49
6 Le résultat 50
7 Conclusion 52
8 Annexe 53
8.1 Fonctions codées sous R . . . . . . . . . . . . . . . . . . . . . . 53
Table des figures 56
Bibliographie 57
4

Chapitre 1
Introduction
1.1 Contexte de l’étude
De nos jours, l’information joue un rôle primordial dans le quotidien des indivi-
dus et dans l’essor des entreprises. Cependant, le développement de technologies
dans tous les domaines ont conduit à la production d’un volume d’informations
numérisés sans précédent. Il est par conséquent, de plus en plus difficile de loca-
liser précisément ce que l’on recherche dans cette masse d’informations numéri-
sées. Il est alors intéressant de mettre en place un dispositif permettant de stocker
et d’organiser des masses d’informations de ces documents numérisés et de loca-
liser celles qui seraient pertinentes relativement à un besoin en information d’un
utilisateur.
L’objectif de ce travail est donc de mettre en place des outils permettant l’ex-
traction et la classification de données à partir de documents numérisés. Toutes les
données étant maintenant numérisées, il est nécessaire de pouvoir correctement les
traitées, pour cela il existe ce qu’on appelle les méthodes de classifications. Ces
méthodes vont permettre d’analyser de gros corpus de données quelque soit le do-
maine. En procédant à une classification, on construit des ensembles homogènes
d’individus, c’est-à-dire partageant un certain nombre de caractéristiques iden-
tiques. Ainsi la classification permet de mettre en évidence des regroupements
sans connaissance à priori sur les données traitées.
Dans ce travail afin d’avancer dans la recherche, il faut prendre des données
d’entrées qui ont la même nature mais sont différentes dans leur conception. Les
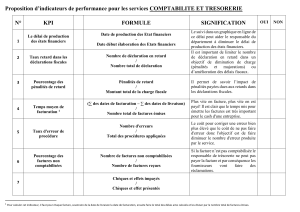
factures étant un type de document qui répond à cette attente, nous considérons
donc que les données d’entrées seront des factures. Pour produire une masse de
factures il est nécessaire de développer un outil permettant la génération automa-
5
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
1
/
57
100%