Architecture et technologie des ordinateurs II G. Tempesti Semaine

Architecture et technologie des ordinateurs II
G. Tempesti Semaine XII 1
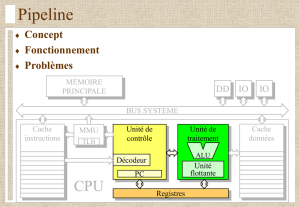
Pipeline
®Concept
®Fonctionnement
®Problèmes
BUS SYSTÈME
Registres
Registres
Unité de
traitement
Unité de
traitement
Unité
flottante
Unité de
contrôle
Unité de
contrôle
Décodeur
PC
ALU
CPU
MÉMOIRE
PRINCIPALE
MÉMOIRE
PRINCIPALE DD
DD IO
IO IO
IO
Cache
données
Cache
instructions MMU
MMU
TLB
Vue d'ensemble du processeur
RA
WA
RB
WEN
I0I1
Z
SHIFTER
R0 R1 R2 R3 R4 R5 R6 R7
SH2
SH1
SH0
AL2
AL1
AL0
OEN SEL
Zπ0
1 0
INPORTOUTPORT
3
3
3
Mémoire
Mémoire
Séquenceur
Séquenceur
CK
IR
Opcode Opérandes
IR
Opcode Opérandes
Fanions
RAM
RAM
Contrôle
SLC
SLC
Opérandes
MDR MAR
CK
PC
Boucle de traitement
Décodage
Décodage
Chargement
(opérandes)
Chargement
(opérandes)
Rangement
(opérandes)
Rangement
(opérandes)
Chargement
(instruction)
Chargement
(instruction)
Exécution
Exécution
L'instruction est cherchée en mémoire et chargée
dans le registre d'instruction (IR)
L'instruction est décodée pour en extraire les
signaux de contrôle pour l'unité de traitement
Les opérandes demandés par l'instruction sont
cherchés dans les registres ou en mémoire
L'opération demandée est effectuée sur les
opérandes choisis
Le résultat de l'opération est stocké dans un
registre ou en mémoire

Architecture et technologie des ordinateurs II
G. Tempesti Semaine XII 2
IF ID OF EX OC
IF ID OF EX OC
IF ID OF EX OC
IF ID OF EX OC
Exécution - Timing
L'exécution d'une instruction comporte donc au plus 5 phases:
•le chargement de l'instruction (instruction fetch ou IF)
•le décodage de l'instruction (instruction decode ou ID)
•le chargement des opérandes (operand fetch ou OF)
•l'exécution de l'instruction (execute ou EX)
•le rangement des opérandes (operand commit ou OC)
Toutes les phases d'exécution n'ont pas la même durée.
INST 1
INST 2
INST 3
INST 4
CK
La fréquence maximale de l'horloge est déterminée par l'instruction
la plus lente (sans compter les cache miss).
Vue d'ensemble du processeur
SHIFTER
SHIFTER
REGISTRES
REGISTRES
I0
I1
Z
INPORT
INPORT
Séquenceur
Séquenceur
IR
IR
Décodeur
Décodeur PC
Adresse
Adresse Adresse
Adresse INPORT
INPORT OUTPORT
OUTPORT
Chargement
(instruction) Rangement
(opérandes)
Décodage Exécution
Chargement
(opérandes)
REGISTRES
REGISTRES
REGISTRES
REGISTRES
REGISTRES
REGISTRES
Pipeline - Implémentation
SHIFTER
SHIFTER
REGISTRES
REGISTRES
I0
I1
Z
INPORT
INPORT
Séquenceur
Séquenceur
IR
IR
Décodeur
Décodeur PC
Adresse
Adresse Adresse
Adresse INPORT
INPORT OUTPORT
OUTPORT
Chargement
(instruction) Rangement
(opérandes)
Décodage Exécution
Chargement
(opérandes)
Les étages doivent être séparés par des registres (ou des latches).

Architecture et technologie des ordinateurs II
G. Tempesti Semaine XII 3
Pipelining
Pipelining: l'exécution de chaque instruction est divisée en étages.
IF ID OF EX OC
IF ID OF EX OC
IF ID OF EX OC
IF ID OF EX OCINST 1
INST 2
INST 3
INST 4
CK
IF ID OF EX OCINST 1
INST 2
INST 3
INST 4
CK
IF ID OF EX OC
IF ID OF EX OC
IF ID OF EX OC
La fréquence maximale
de l'horloge d'un
pipeline est déterminée
par l'étage le plus lent.
Latence (latency ou flow-through time) d'un pipeline:
temps (en nombre de coups d'horloge) nécessaire
pour produire le premier résultat.
Latence (latency ou flow-through time) d'un pipeline:
temps (en nombre de coups d'horloge) nécessaire
pour produire le premier résultat.
Bande passante (throughput) d'un pipeline: nombre
d'instructions par cycle d'horloge.
Bande passante (throughput) d'un pipeline: nombre
d'instructions par cycle d'horloge.
Timing - Définitions
En pratique, la latence d'un pipeline correspond à sa profondeur,
c'est-à-dire, au nombre d'étages.
En pratique, pour la plupart des pipelines, la bande passante est
d'une instruction par cycle d'horloge.
Timing - Temps d'exécution
Si on ignore les cache miss, le temps d'exécution d'un programme sur
un processeur sans pipeline est donné par:
Texec = # instructions ¥¥
¥¥ # cycles par instruction ¥¥
¥¥ Tcycle
Pour un processeur avec pipeline, le temps d'exécution devient:
Texec = ((# instructions-1) ¥¥
¥¥ (1 / Bande passante) + Latence) ¥¥
¥¥ Tcycle
Comme pour la plupart des processeurs avec pipeline la bande
passante est d'une instruction par cycle d'horloge:
Texec = ((# instructions-1) + Latence) ¥¥
¥¥ Tcycle

Architecture et technologie des ordinateurs II
G. Tempesti Semaine XII 4
Timing - Temps de cycle
Le temps de cycle sur un processeur sans pipeline est donné par:
C'est à dire, le temps d'exécution de l'instruction i la plus lente parmi
toutes les instructions du jeu d'instructions du processeur.
Pour un processeur avec pipeline, le temps de cycle devient:
C'est-à-dire, le temps d'exécution de l'étage le plus lent parmi tous les
étages des toutes les instructions i du jeu d'instructions.
Tcycle T T T T T
i
IF i
ID i
OF i
EX i
OC
=++++max( )
[] [] [] [] []
Tcycle T T T T T
i
IF i
ID i
OF i
EX i
OC
=max(max( ),max( ),max( ),max( ),max( ))
[] [] [] [] []
TIF TID TOF TEX TOC Total
Instruction A 2ns 3ns 2ns 3ns 2ns 12ns
Instruction B 2ns 4ns 2ns 1ns 2ns 11ns
Instruction C 2ns 2ns 2ns 1ns 2ns 9ns
TIF TID TOF TEX TOC Total
Instruction A 2ns 3ns 2ns 3ns 2ns 12ns
Instruction B 2ns 4ns 2ns 1ns 2ns 11ns
Instruction C 2ns 2ns 2ns 1ns 2ns 9ns
Remarques sur la performance
Remarque 1:
Certaines phases sont inutiles pour certaines instructions (p.ex. un
LOAD ne nécessite pas d'exécution), mais toutes les instructions
doivent traverser tout le pipeline. Ce "gaspillage" est nécessaire pour
simplifier le contrôle.
Remarque 2:
Les pipelines sont normalement associés à des architectures
load/store: la complexité des accès mémoire dans une architecture
"standard" demande trop de matériel et de délai supplémentaire
pour les étages de lecture et d'écriture des données.
Améliorations possibles
Amélioration 1:
Logiquement, un meilleur résultat pourrait être obtenu en
augmentant le nombre d'étages: ils seront plus simples et la
fréquence d'horloge pourra ainsi être plus élevée. La décomposition
fine est toutefois très difficile. La plupart des processeurs sur le
marché en ce moment ont des pipelines d'une profondeur de 5 à 7
étages, même si des pipelines de 14 étages existent (Pentium Pro).
Amélioration 2:
En général, la performance d'un pipeline est augmentée en
accélérant l'étage le plus lent (souvent, le décodage). L'optimisation
des parties les plus rapides (p.ex. l'ALU) est inutile.

Architecture et technologie des ordinateurs II
G. Tempesti Semaine XII 5
Aléas d'un pipeline
La présence d'un pipeline (et donc le partage de l'exécution d'une
instruction en plusieurs étages) introduit des aléas:
•aléas de structure: l'implémentation empêche une certaine
combinaison d'opérations (lorsque des ressources sont partagées
entre plusieurs étages)
•aléas de données: le résultat d'une opération dépend de celui
d'une opération précédente qui n'est pas encore terminée
•aléas de contrôle: l'exécution d'un saut introduit un délai lorsque
le saut est conditionnel et dépend donc du fanion généré par une
opération précédente
Les aléas de structure peuvent être éliminés en agissant sur
l'architecture du processeur lors de sa conception. Par contre, les
aléas de données et de contrôle ne peuvent pas être éliminés.
Aléas de données
Deux instructions contiguës i et j peuvent présenter
des aléas de données (dépendances entres les
opérandes des deux instructions). En particulier,
pour notre pipeline:
•RAW (read-after-write): j essaie de lire un
registre avant que i ne l'ait modifié
i: move R1, R2 {R2¨¨
¨¨R1}
j: add R2, R3 {R3¨¨
¨¨R2+R3}
D'autres aléas sont possibles entre deux instructions
(write-after-read, write-after-write), mais ils ne sont
pas possibles dans un pipeline "standard".
Décodage
Décodage
Chargement
(opérandes)
Chargement
(opérandes)
Rangement
(opérandes)
Rangement
(opérandes)
Chargement
(instruction)
Chargement
(instruction)
Exécution
Exécution
Aléas de données - Solution I
Une solution relativement simple pour traiter les aléas de données est
de retarder l'exécution des instructions concernées (pipeline stall) en
les bloquant à l'étage de chargement des opérandes.
IF ID OF EX OCINST 1
INST 2
INST 3
INST 4
CK
IF ID OF EX OC
IF ID OF EX OC
IF ID OF EX OC
move r1,r2
add r2,r3
...
...
Il faut toutefois remarquer que, les aléas de données (et surtout les
RAW) étant relativement fréquents, le délai introduit par cette
méthode est loin d'être négligeable.
 6
7
8
9
10
6
7
8
9
10
1
/
10
100%