2 - AMPCfusion

UMR Génétique 2
22/10/2015
Eric PASMANT – Claude HOUDAYER
Eric.pasmant@parisdescartes.fr
RT : Arnaud KLOKNER
RL : Corentin BACHELLEREAU
Principaux mécanismes moléculaires des maladies
génétiques – Bases de données – Cas particulier des
« variants de signification incertaine »
Plan :
I. Introduction
A. Définitions
B. Mécanismes des mutations délétères à l’origine des
maladies mendéliennes
C. Classification des maladies génétiques
D. Conséquences des mutations délétères
E. Maladies génétiques liées à des réarrangements
chromosomiques.
F. Maladies génétiques par expansion de microsatellites.
G. Les substitutions nucléotidiques : remplacement d’une
base par une autre.
II. Interprétations des mutations
A. Les changements nucléotidiques faux sens.
B. Bases de données publiques et navigateurs
C. Bases de données de mutations
D. Variants de signification incertaine
E. Analyse des mutations d’épissage
F. Cas pratiques
1. Néoplasies endocriniennes multiples de type 1
2. Applications du Next Generation Sequencing
2.1. Mutation de BRCA dans un cancer de l’ovaire.
2.2. Syndrome de Peutz-Jeghers
2.3. Le cas de la mucoviscidose.
2.4. Syndrome néphrotique corticoresistant
III. Conclusion

I. Introduction
A. Définitions
Variant : Changement de séquence par rapport à l’allèle de référence (allèle ancestral). On
distingue plusieurs types de variants :
Polymorphisme MAF >1%
Variant rare : MAF <1%
Mutation : variant défini par son caractère causal.
Une mutation est une variation de séquence du génome responsable de l’apparition d’une
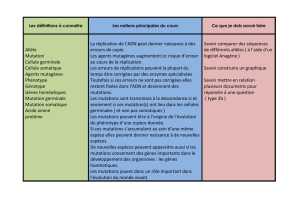
maladie définie par son caractère causal et son mécanisme de survenue. Selon la cellule mutée
on va parler de mutation constitutionnelle ou de mutation somatique.
B. Mécanismes des mutations délétères à l’origine des maladies
mendéliennes
Le terme de mutation désigne tout changement du matériel héréditaire survenant soit dans la
lignée germinale (mutations germinales ou constitutionnelles) soit dans les cellules somatiques
(mutations somatiques) responsables de l’apparition d’une maladie.
Seules les mutations germinales peuvent être transmises à la descendance.
Les mutations sont dans la majorité des cas spontanés mais elles peuvent également être
induites par exposition à des agents mutagènes.
Les mutations peuvent aussi apparaitre de novo (néomutations) selon deux modes en fonction
du timing de l’apparition.

Il est très important d’avertir les parents des risques de transmettre à nouveau la mutation à
leurs prochains enfants lors du conseil génétique.
Pour les cas de mosaïques on peut réellement voir des territoires cutanés touchés et d’autre non
comme dans la neurofibromatose de type 1 par exemple.
La mutation touche les gamètes
parentaux, toutes les cellules de
l’embryon sont touchées
La mutation survient dans les
stades très précoces du
développement, certaines
cellules de l’embryon sont
touchées : mosaïque

C. Classification des maladies génétiques
On peut distinguer plusieurs types de maladies génétiques :
Les maladies héréditaires à transmission mendélienne dont l’apparition est conditionnée par la
mutation d’un seul gène comme la mucoviscidose par exemple. On parle aussi de maladie
monogénique. Ce sont des maladies à forte pénétrance mais à faible fréquence allélique.
Les maladies multifactorielles quant à elles sont conditionnées par la présence de certaines
combinaisons d’allèles de plusieurs gènes situés sur des locus différents, aucun de ces gènes
n’étant indispensable par lui-même à l’apparition de la maladie. On parle d’hérédité complexe ou
de maladie polygénique. Dans ce cas, ce sont des maladies à pénétrance beaucoup plus faible
mais avec une fréquence allélique dans la population beaucoup plus importante. Ces allèles
peuvent tout à fait être présents chez des personnes saines.
Les maladies par aberration chromosomique sont des maladies dues à une anomalie du nombre
ou de la structure des chromosomes.
Les maladies mitochondriales sont dues à des mutations dans le génome mitochondrial et
d’hérédité maternelle. Toutefois les cytopathies mitochondriales peuvent être la conséquence de
mutations du génome nucléaire et mitochondrial.
La pénétrance : La pénétrance d’une maladie à transmission dominante est définie par le
pourcentage de sujets hétérozygotes pour le gène délétère qui expriment les manifestations
cliniques de la maladie. On a un continuum de la maladie monogénique à la maladie
multifactorielle. La pénétrance est un phénomène en tout ou rien : le sujet est ou n’est pas atteint
de la maladie. A ne pas confondre avec l’expressivité.
𝑃 = 𝑆𝑢𝑗𝑒𝑡𝑠 𝑚𝑎𝑙𝑎𝑑𝑒𝑠
𝑆𝑢𝑗𝑒𝑡𝑠 ℎé𝑡é𝑟𝑜𝑧𝑦𝑔𝑜𝑡𝑒𝑠 ×100

Transmission autosomique récessive
Ce mode de transmission et défini par plusieurs caractéristiques. Parmi les sujets malades :
pas de prépondérance d’un sexe
ils sont homozygotes ou hétérozygotes composite pour le gène délétère
généralement issus de l’union de deux hétérozygotes sains
la descendance du malade sera généralement de phénotype normal.
Transmission autosomique dominante
Dans ce mode ci :
pas de prépondérance d’un sexe non plus
le sujet est généralement hétérozygote pour la maladie
un seul des deux parents atteint
½ de transmettre à ses enfants
Transmission récessive liée à l’X
Dans le cas d’une mutation sur le chromosome sexuel :
Ne touche que les hommes
Les femmes peuvent néanmoins être porteuses saines
D. Conséquences des mutations délétères
1. Mutations par gain de fonction.
Il s’agit généralement d’une seule ou de peu de mutations qui sont responsable de la maladie, qui
est le plus souvent une maladie dominante. Elles sont responsables d’une modification des
propriétés de la protéine ou du transcrit. Ce sont le plus souvent des mutations faux sens très
précises, plus rarement des maladies à expansion de triplets dans les régions codantes ou des
mutations d’épissage.
Ce gain de fonction peut se révéler par l’acquisition d’une nouvelle fonction, par une
surexpression ou par un effet de dominant négatif ; c’est-à-dire que les mutations affectent la
fonction de l’allèle normal chez les hétérozygotes et que celui-ci ne peut plus fonctionner
correctement (protéines de structure ou formant des homo-ou des hétéropolymères).
Exemple de la mutation gain de fonction de l’α1antytrypsine qui à cause d’une mutation
spécifique peut inhiber la thrombine en plus de sa fonction de base qui est l’inhibition de
l’elastase. Cela provoque des syndromes hémorragiques chez les malades qui en sont atteints.
2. Mutations par perte de fonction.
La mutation rend l’allèle inutilisable. Dans le cas d’une maladie récessive, la quantité de transcrit
va diminuer mais il faudrait que les deux copies soient inutilisables pour que le phénotype
apparaisse. Et dans le cas d’une maladie dominante on va se retrouver dans une situation
d’haploinsuffisance. C’est-à-dire que le manque d’un allèle va empêcher le gène d’assurer
correctement sa fonction.
 6
7
8
9
10
11
12
13
14
15
6
7
8
9
10
11
12
13
14
15
1
/
15
100%