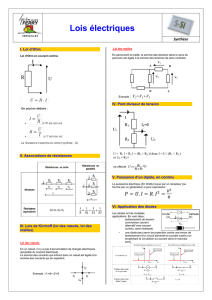
Optimisation des ressources d`un cluster pour le calcul scientifique

DELHAY
Damien
E2S
Rapport d'Assistant Ingénieur
4ème année du Cycle Ingénieur à Polytech Paris Sud
12 mai au 1 août 2014
Tuteur école : François Samouth
Mail : [email protected]
Optimisation des ressources d'un cluster
pour le calcul scientifique
Société : LUMAT
Adresse : Bâtiment 210, Université Paris Sud,
Orsay, 91405
Date du stage : 12 mai au 1er août 2014
Tuteur de l'entreprise : Philippe Dos Santos
Mail : [email protected]

Table des matières
Remerciements.....................................................................................................................................................3
Introduction..........................................................................................................................................................4
I/ Présentation de la fédération LUMAT...........................................................................................................5
I.1. La Fédération.............................................................................................................................................5
I.2. Plate-formes...............................................................................................................................................6
I.3. GMPCS......................................................................................................................................................6
I.3.1) Périmètre............................................................................................................................................6
I.3.2) Descriptions matérielles et logicielles...............................................................................................7
II/ Optimisation des calculs sur la grappe.........................................................................................................8
II.1. Introduction..............................................................................................................................................8
II.2. Généralités sur les calculs parallèles........................................................................................................8
II.3. Niveaux de parallélismes étudiés............................................................................................................10
II.3.1) Parallélisme sur un seul nœud........................................................................................................10
II.3.2) Parallélisme sur plusieurs nœuds...................................................................................................10
II.4. Description matérielle.............................................................................................................................12
III/ Performance de la parallélisation pour la multiplication de matrices...................................................12
III.1. Résultats sur un seul nœud....................................................................................................................12
III.1.1) Méthodes et réalisation.................................................................................................................13
III.1.2) Résultats........................................................................................................................................13
III.1.3) Optimisations................................................................................................................................14
III.1.4) Comparaison avec une librairie existante.....................................................................................15
III.2. Performances sur plusieurs nœuds........................................................................................................16
III.2.1) Méthodes et réalisation.................................................................................................................16
III.2.2) Résultats........................................................................................................................................17
III.2.3) Optimisations................................................................................................................................19
III.2.4) Comparaison avec une librairie existante.....................................................................................21
IV/ Méthodologie pour optimiser les ressources de calcul.............................................................................22
IV.1. Mesures sur un nœud............................................................................................................................22
IV.2. Mesures sur plusieurs nœuds................................................................................................................23
Conclusion..........................................................................................................................................................24
Bibliographie......................................................................................................................................................25
Annexes...............................................................................................................................................................26
Annexe 1 : Lexiques.......................................................................................................................................26
Annexe 2 : Architecture Ivy Bridge................................................................................................................27
Annexe 3 : Multiplication sur 1 nœud en mémoire partagée..........................................................................27
Annexe 4 : Accélération sur un processeur Ivy Bridge...................................................................................28
Annexe 5 : Accélération sur un processeur Sandy Bridge..............................................................................28
Annexe 6 : Courbes de temps de communication sur plusieurs nœuds..........................................................29
Annexe 7 : Rapport personnel........................................................................................................................30
2-31

Remerciements
Je remercie Philippe Dos Santos, mon tuteur de stage, et Georges Raseev pour m'avoir encadré durant ce stage
sur la grappe GMPCS, pour leur disponibilité, soutien et leurs conseils tout au long de ce travail.
Je remercie également Yves Bergougnoux, Oliver De Kermoysan et Jean-Yves Bazzara, ainsi que tout le
personnel de l'ISMO.
Je remercie aussi tous les chercheurs, ingénieurs, techniciens et administratifs travaillant dans les locaux du
bâtiment 210 pour leur accueil chaleureux.
Je tiens à remercier Cédric Koeniguer d'avoir été la pour nous encourager durant nos recherches et nos
périodes de stage et François Samouth, pour sa bienveillance au bon déroulement du stage.
3-31

Introduction
La Grappe Massivement Parallèle de Calcul Scientifique est une plate-forme de la fédération LUmière-
MATière utilisée par les chercheurs pour effectuer des calculs scientifiques de haute performance. La mission
de mon stage est d'optimiser les allocations des ressources de la grappe pour les calculs parallèles.
Pour ce faire, je vais m'appuyer sur l'algorithme de la multiplication de matrice, qui est entièrement
parallélisable, afin d'observer les limitations du parallélisme sur un et sur plusieurs nœuds. Puis, je
généraliserai au cas d'un programme donné qui n'est pas complément parallélisable.
Dans un premier temps, je présenterai le contexte de mon stage. Puis, j’étudierai les principes de la
parallélisation sur un et plusieurs nœuds. Enfin, j'apporterai des recommandations pour optimiser les
ressources de la grappe.
Enfin, dans l'annexe 1, le lecteur trouvera un lexique des termes techniques pour l'aider dans sa lecture du
rapport.
4-31

I/ Présentation de la fédération LUMAT
I.1. La Fédération
La fédération Lumière Matière LUMAT est une fédération de recherche, regroupant quatre laboratoires situés
dans l'Université d'Orsay : le Laboratoire Charles Fabry (LCF), l'Institut des Sciences Moléculaires d'Orsay
(ISMO), le Laboratoire de Physique des Gaz et des Plasmas (LPGP) et le Laboratoire Aimé Cotton (LAC).
LUMAT est composé d'environ 320 personnes permanentes, qui sont rattachés au Centre National de la
Recherche Scientifique (CNRS), à l'Université Paris-Sud (UPS) ou à l'Institut d'Optique Graduate School
(IOGS). Ces 320 personnes sont constituées de :
- 115 chercheurs
- 75 enseignant-chercheurs
- 130 ingénieurs, techniciens et administratifs
L'organigramme de la fédération s'établit comme ceci:
5-31
Figure 1: Organigramme du LUMAT
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
1
/
31
100%