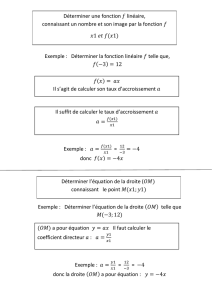
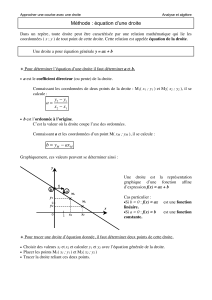
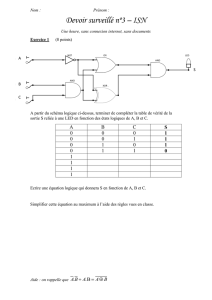
Régression linéaire & Notes de cours de statistique descriptive
Telechargé par
lilirose20021

COURS STATISTIQUE DESCRIPTIVE : Pr Hassiba DJEMA / EHEC : Page 1
2/ Etude conjointe de deux variables Quantitatives :
En présence de deux variables statistiques, on peut se demander s’il existe un lien linéaire
entre ces deux variables ou si, ou contraire, l’une évolue indépendamment de l’autre.
Lorsqu’une liaison existe entre deux variables, ce lien peut présenter différentes caractéristiques
telles que son sens (proportionnel ou opposé), son importance (forte ou faible) ou sa forme
(linéaire ou non linéaire).
Le modèle de régression linéaire simple
Comment expliquer à travers la statistique ?
Expliquer existence d’un phénomène a expliquer (interpréter par une variable) et des éléments d’explications (un ou
plusieurs) existence d’une relation de causalité entre les variables ;
Il s’agit d’étudier la relation entre une variable dépendante particulière et une ou plusieurs variables indépendantes
(d’où le qualificatif de régression simple ou multiple)
Deux objectifs principaux
La prédiction: développer une formule permettant de faire des prédictions à propos de la variable dépendante
sur la base des valeurs observées parmi les variables indépendantes
L’analyse causale: déterminer si telle ou telle variable indépendante affecte réellement la variable dépendante
et si oui estimer la grandeur de cet effet
Commençons par le cas le plus simple avec deux variables : Y une variable à expliquer par une variable X qui est
l’explicative ;
Prenons l’exemple de l’étude de marché de Danone :
Une enquête consommation grand public a était réalisé par un institut de recherche marketing en Algérie en 2006 au
profit de l’entreprise Danone, les objectifs de l’étude :
Evaluer le potentiel marché et les besoins du consommateur en terme de valeur.
Analyser la satisfaction des consommateurs des produits Danone.

COURS STATISTIQUE DESCRIPTIVE : Pr Hassiba DJEMA / EHEC : Page 2
Afin de répondre au premier besoin (potentiel marché) nous analysons la relation existante entre le budget consacré à
la consommation des produits laitiers (Y) et le revenu du foyer (X) :
La premiere étape d’analyse consiste
à tracer le nuage de point des deux
variables X, Y ; en respectant le
positionnement de la variable
explicative (Revenu X) sur l’axe des
abscisse et la variable à expliquer
(Consommation produits laitier Y)
sur l’axe des ordonnées.
Nous observons que le nuage s’étale
en un sens unique, pas de points
positionnées sur les zones A ou B ; il
marque clairement un relation entre
les deux variables (une causalité) ;
0
1 000
2 000
3 000
4 000
5 000
6 000
7 000
8 000
9 000
0 20 000 40 000 60 000 80 000 100 000
Revenu Mensuel (X)
consommation produit laitier Mensuel
(Y)
Nous traçons une courbe
d’ajustement de la distribution ;
cette courbe à pour équation :
Y= b0+b1X
Pour que cette courbe donne le
meilleur ajustement possible, elle
doit passer par le maximum de points
possibles ou être proche le plus
possible des points.
On note, pour la même observation :
équationl' de
partir à calculpar obtenu valeur la
ˆ
entempiriquem observé valeur la
i
i
y
y
0
1 000
2 000
3 000
4 000
5 000
6 000
7 000
8 000
9 000
0 20 000 40 000 60 000 80 000 100 000
Revenu Mensuel (X)
consommation produit laitier Mensuel
(Y)
A
B

COURS STATISTIQUE DESCRIPTIVE : Pr Hassiba DJEMA / EHEC : Page 3
Donc nous devons minimisé la
somme des différence de
ii yy ˆ
soit
mathématiquement
n
iii yy
1
ˆ
min
Nous remarquons que certains points
sont positionnés au dessous de la
ligne d’ajustement alors que d’autre
au dessous, de ce fait certaines
distances vont avoir des signes
positifs alors que d’autre des signes
négatifs, ainsi les distances vont
s’annulées entre eux ;
Afin d’éviter ce problème nous
pouvons pensé à deux solutions :
1. utilisé les valeurs absolue I
2. mettre au carrée les valeurs ²
Sur le plan statistique, la deuxième
solution est préférable ; ainsi
l’équation devient :
²
ˆ
min 1
n
iii yy
0
1 000
2 000
3 000
4 000
5 000
6 000
7 000
8 000
9 000
0 20 000 40 000 60 000 80 000 100 000
Revenu Mensuel (X)
consommation produit laitier Mensuel
(Y)
2. Quelques développements mathématiques simples:
Nous développons l’équation :
2
110
1
2
ˆ
N
iii
N
iii xbbyyy
N
iiiiiii xbxbbbxybyby
1
22
110
2
010
2222

COURS STATISTIQUE DESCRIPTIVE : Pr Hassiba DJEMA / EHEC : Page 4
Pour que cette équation atteint son minimum il faut que les dérivés du premier ordre
s’annulent1 :
n
iii
n
iii xbby
b
yy
110
0
1
2
)222(
ˆ
………1
n
iiiii
n
iii xbxbxy
b
yy
1
2
10
1
1
2
)222(
ˆ
….2
A partir de la première équation nous pouvons déduire :
n
i
n
iii
n
i
n
iii
n
ixbyNbxbyb 1 1
10
1 1
1
10
En divisant par N les deux parties de l’équation, sachant que
N
x
X
N
ii
1
nous obtenons :
retenir) a(résultat
10 XbYb
En remplaçant ce résultat dans la deuxième équation nous trouvons :
0)2)((2)222( 1
2
11
1
2
10
n
iiiii
n
iiiii xbxXbYxyxbxbxy
D’où :
N
ii
N
iii
N
i
N
iiii
N
i
N
iii
XNx
XYNxy
b
xYxyxXxb
1
22
1
1
1 11 1
2
1
)(
1 Nous admettons que la distribution de cette équation est convexe
Nous dérivons par rapport à b0 et b1 (et non pas X, Y ..attention) car nous cherchons les valeurs de b0 et b1 qui permettent de
minimiser cette équation

COURS STATISTIQUE DESCRIPTIVE : Pr Hassiba DJEMA / EHEC : Page 5
)2(
)(
2
)()(
2
)()(2
)(
2
1
2
1
1
1 1
22
11 1
1
1
222
1
1
1
22
1
1
XxXx
XYxYXyxy
b
XNxXx
XYNxYXyxy
b
XNXNx
XYNXYNxy
b
XNx
XYNxy
b
i
N
ii
ii
N
iii
N
i
N
iii
N
ii
N
i
N
iiii
N
ii
N
iii
N
ii
N
iii
)²(
1
))((
1
)²(
))((
1
1
1
1
1
1
Xx
N
XxYy
N
b
Xx
XxYy
b
i
N
i
i
N
ii
i
N
i
i
N
ii
retenir) a(résultat
)( ,cov
1XVar YX
b
Cette méthode d’ajustement de Y sur X s’appelle la régression linéaire.
3. Des définitions à retenir :
L’équation Y= b0+b1X est appelé modèle de régression linéaire simple
 6
7
8
6
7
8
1
/
8
100%