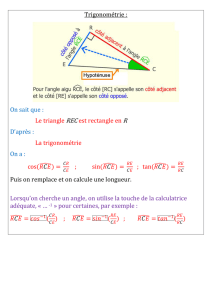
Chapitre 1
Logique et ensembles
Sommaire
1.1 Rudiments de logique ................................ 2
1.1.1 Propositions, démonstrations, etc. ......................... 2
1.1.2 Ensembles, éléments ................................. 3
1.1.3 Propriétés portant sur les éléments d’un ensemble ................ 3
1.1.4 Opérations sur les propositions ........................... 4
1.1.5 Quantificateurs .................................... 4
1.1.6 Quelques synonymies classiques ........................... 5
1.1.7 Conditions nécessaires et/ou suffisantes ...................... 6
1.2 Raisonnements classiques .............................. 6
1.2.1 Conseils appuyés pour bien rédiger ......................... 6
1.2.2 Quelques figures usuelles du raisonnement ..................... 7
1.2.3 L’axiome de récurrence ............................... 8
1.2.4 Raisonnement par récurrence ............................ 9
1.2.5 Raisonnement par analyse-synthèse ......................... 10
1.2.6 Résolutions d’équations ou d’inéquations ...................... 11
1.2.7 Équations ou inéquations à un paramètre ..................... 12
1.3 Ensembles ....................................... 13
1.3.1 Opérations sur les ensembles ............................ 13
1.3.2 Ensemble des parties d’un ensemble ........................ 13
1.3.3 Opérations sur les parties d’un ensemble ...................... 14
1.3.4 Produit cartésien d’un nombre fini d’ensembles .................. 15
1.4 Applications ..................................... 16
1.4.1 Applications entres ensembles non vides ...................... 16
1.4.2 Famille indexée par un ensemble non vide ..................... 17
1.4.3 Fonction indicatrice d’une partie .......................... 18
1.4.4 Restriction et prolongement ............................. 19
1.4.5 Image directe d’une partie par une application .................. 19
1.4.6 Image réciproque d’une partie par une application ................ 20
1.4.7 Composition d’applications ............................. 21
1.5 Injections, surjections, bijections ......................... 22
1.5.1 Applications injectives ................................ 22
1.5.2 Applications surjectives ............................... 23
1.5.3 Applications bijectives ................................ 23
1

1.1 Rudiments de logique ⇑Chapitre 1 : Logique et ensembles
1.6 Relations binaires .................................. 25
1.6.1 Généralités ...................................... 25
1.6.2 Propriétés éventuelles des relations binaires .................... 26
1.6.3 Relations d’ordre ................................... 26
1.6.4 Relations d’équivalence, classes d’équivalence ................... 28
1.6.5 Congruence modulo un réel strictement positif .................. 30
1.6.6 Division euclidienne et congruence modulo un entier ............... 30
1.1 Rudiments de logique
1.1.1 Propositions, démonstrations, etc.
Définition 1.1.1
Une proposition est un énoncé dont on doit pouvoir dire qu’il est « vrai » ou « faux ».
On notera Vet F(ou encore 1et 0) les deux valeurs logiques possibles d’une proposition.
Exemples :
– « l’entier 2011 est premier » est une proposition vraie
– « l’entier 2012 est premier » est une proposition fausse
– « l’entier 2014 est une somme de deux carrés » est une proposition fausse (prouvez-le)
– « l’entier 2017 est somme de deux carrés » est une proposition vraie (en effet 2017 = 92+ 442)
Définition 1.1.2
Certaines propositions sont déclarées vraies à priori : ce sont les axiomes. Sinon la véracité (ou la
fausseté) d’une proposition doit résulter d’une démonstration (d’une preuve).
Remarque : dans le cadre d’un cours de mathématiques, quand on énonce une proposition, c’est pour
affirmer qu’elle est vraie (et qu’on va la démontrer) !
Définition 1.1.3
Un théorème est une proposition vraie particulièrement importante.
Un lemme est une proposition vraie, utile à la démonstration d’une proposition plus importante.
Un corollaire est une proposition vraie, conséquence immédiate d’une autre proposition vraie.
Une conjecture est une proposition qu’on pense généralement vraie, sans en avoir de preuve.
Exemples :
– « l’axiome de récurrence » dans N, « l’axiome de la borne supérieure » dans R.
– « le théorème de Pythagore », le « théorème de Rolle », « le théorème de Bolzano-Weierstrass ».
– le « lemme des bergers », le « lemme de Gauss », le « lemme des noyaux ».
– la « conjecture de Syracuse », la « conjecture de Goldbach ».
– la « conjecture de Fermat » est devenue le « grand théorème de Fermat » en 1994.
©Jean-Michel Ferrard Ce cours accompagne la souscription au site mathprepa.fr
Sa diffusion en dehors de ce cadre n’est pas autorisée
Page 2

1.1 Rudiments de logique ⇑Chapitre 1 : Logique et ensembles
1.1.2 Ensembles, éléments
On ne se risque pas à donner une définition précise de ces notions premières.
Définition 1.1.4
On dit qu’un ensemble Eest constitué d’éléments et qu’un élément aappartient àE(on écrit : a∈E)
ou n’appartient pas à E(on écrit : a /∈E).
Deux ensembles E, F sont dits égaux (on note E=F) s’ils sont constitués des mêmes éléments.
Par convention l’ensemble vide, noté ∅, est l’ensemble ne contenant aucun élément.
Quelques remarques
– Un même objet mathématique peut, selon les circonstances, être vu comme un ensemble, ou comme
un élément d’un ensemble. Par exemple, l’intervalle [0,1] est un ensemble de nombres réels, mais c’est
également un élément de l’ensemble des intervalles de R.
– Un ensemble fini peut être défini en extension, c’est-à-dire par la liste (non ordonnée) de ses éléments.
C’est le cas par exemple de l’ensemble E={1,3,6,10,15,21,28,36,45,55}.
Dans une écriture comme {a, b, c, . . .}les éléments a, b, c, etc. sont à priori supposés distincts, et
l’ordre dans lequel ils sont donnés n’a aucune importance.
– Un ensemble Epeut être défini en compréhension (par une propriété caractérisant ses éléments).
Ainsi E=nn(n+1)
2, n ∈N,16n610oest une autre définition de {1,3,6,10,15,21,28,36,45,55}.
– Il y a bien d’autres conventions pour définir ou nommer des ensembles. Par exemple :
·Si a, b sont deux réels, [a, b[est l’ensemble des réels xqui vérifient a6x<b.
·Si Eest un ensemble, P(E)est l’ensemble des parties de E.
·Certains ensembles ont des noms consacrés par l’usage : N,Z,Q,R,C, ...
Définition 1.1.5
Par convention l’ensemble vide, noté ∅, est l’ensemble ne contenant aucun élément.
Un ensemble {a}, formé d’un seul élément, est appelé un singleton.
Un ensemble {a, b}, formé de deux éléments distincts, est appelé une paire.
1.1.3 Propriétés portant sur les éléments d’un ensemble
On sait que la proposition « l’entier 2017 est somme de deux carrés » est vraie (2017 = 92+ 442).
Mais l’énoncé « l’entier nest une somme de deux carrés », qui contient la variable libre n(c’est-à-dire
à laquelle on n’a pas donné de contenu particulier) ne peut pas être considéré comme une proposition,
car on ne peut lui attribuer la valeur « Vrai » ou « Faux » tant qu’on ne donne pas une valeur à n.
On parlera plutôt ici d’une propriété Pportant sur les entiers naturels n.
Avec cette définition, la proposition P(2017) est vraie (ou encore : l’entier 2017 vérifie la propriété P)
et la proposition P(2014) est fausse (l’entier 2014 ne vérifie pas la propriété P).
Soit Pune propriété portant sur les éléments d’un ensemble E. Pour affirmer qu’un élément xde E
vérifie (ou satisfait à) la propriété P, on écrira simplement « P(x)» plutôt que « P(x)est vraie »˙
Il nous arrivera de considérer des énoncés contenant plusieurs variables libres.
Par exemple, la propriété Psuivante : « l’entier nest la somme de kcarrés »
©Jean-Michel Ferrard Ce cours accompagne la souscription au site mathprepa.fr
Sa diffusion en dehors de ce cadre n’est pas autorisée
Page 3

1.1 Rudiments de logique ⇑Chapitre 1 : Logique et ensembles
1.1.4 Opérations sur les propositions
On peut créer de nouvelles propositions à l’aide d’« opérations » sur des propositions existantes.
Définition 1.1.6
À partir des propositions A,B, on définit ainsi :
– la négation « non A» (ou encore A, ou encore ¬A).
– la disjonction «Aou B» (notée également A∨B).
– la conjonction «Aet B» (notée également A∧B).
– l’implication : la proposition « Aimplique B» (notée A⇒B)
– l’équivalence : la proposition « Aéquivaut à B» (notée A⇔B)
La valeur des propositions précédentes est résumée dans les tableaux de vérité ci-dessous.
A A
V F
F V
A B A ou B
V V V
V F V
F V V
F F F
A B A et B
V V V
V F F
F V F
F F F
A B A ⇒B
V V V
V F F
F V V
F F V
A B A ⇔B
V V V
V F F
F V F
F F V
Au vu des tableaux de vérités précédents, on peut donc dire, d’une façon moins formelle :
– La proposition Aest vraie quand Aest fausse, et fausse quand Aest vraie.
– La proposition « Aou B» est vraie quand l’une au moins des deux propositions A,Best vraie.
– La proposition « Aet B» est vraie quand les deux propositions A,Bsont vraies.
– « A⇒B» est vraie quand Aest fausse (le « faux implique n’importe quoi ») ou quand Best vraie.
– « A⇔B» est vraie quand A,Bsont toutes les deux vraies ou toutes les deux fausses.
Les opérations précédentes peuvent être répétées pour former des propositions P(A,B,C, . . .)dépendant
de propositions initiales A,B,C, etc.
Deux telles propositions P(A,B,C, . . .)et Q(A,B,C, . . .)sont dites synonymes si elles ont le même
tableau de vérité, c’est-à-dire si l’équivalence P(A,B,C, . . .)⇔Q(A,B,C, . . .)est toujours vraie (c’est-
à-dire quelle que soit la valeur de vérité des propositions A,B,C, . . .).
1.1.5 Quantificateurs
Définition 1.1.7
Soit Pune propriété portant sur les éléments d’un ensemble E.
– La proposition « ∃x∈E, P(x)» dit qu’au moins un un élément xde Evérifie la propriété P.
On dit que « ∃» est le quantificateur existentiel.
– La proposition « ∀x∈E, P(x)» exprime que tout élément xde Evérifie la propriété P.
On dit que « ∀» est le quantificateur universel.
– La proposition « ∃!x∈E, P(x)» exprime qu’un et un seul élément xde Evérifie la propriété P.
©Jean-Michel Ferrard Ce cours accompagne la souscription au site mathprepa.fr
Sa diffusion en dehors de ce cadre n’est pas autorisée
Page 4

1.1 Rudiments de logique ⇑Chapitre 1 : Logique et ensembles
De l’importance de la chronologie dans une phrase à plusieurs quantificateurs
On peut former des propositions « à tiroirs » avec plusieurs quantificateurs, notamment sur des énoncés
P(x, y, · · · )à plusieurs variables. Dans ce cas, on prendra garde à l’ordre des quantificateurs, notamment
dans les alternances de « ∀» et de « ∃».
Ainsi les propositions
A:∀x∈E, ∃y∈F, P(x, y)
B:∃y∈F, ∀x∈E, P(x, y)ont souvent des significations très différentes.
Le mieux est de penser à la traduction de ces deux propositions « en français ».
En effet, la proposition Aexprime que pour tout xde E, il existe un élément de y(dont la valeur
dépend a priori du xqu’on vient d’évoquer) tel que la proposition P(x, y)soit vraie.
Quant à la proposition B, elle exprime qu’il existe un certain élément yde Ftel que, pour tout xde
E, la proposition P(x, y)soit vraie.
Par exemple, la proposition « ∀x∈N,∃y∈N, x 6y» (qui exprime que pour tout xde N, il existe
un ydans Nqui lui est supérieur ou égal) est évidemment vraie (prendre y=x, par exemple).
En revanche, la proposition « ∃y∈N,∀x∈N, x 6y» (qui exprime qu’il existe un entier naturel y
supérieur ou égal à tous les entiers naturels) est manifestement fausse.
Bien distinguer le « mode texte » et « mode mathématique »
Considérons la proposition suivante : « tout nombre réel est la puissance troisième d’un nombre réel ».
On pourra tout aussi bien écrire : « pour tout réel x, il existe un réel ytel que y3=x».
En revanche, on n’écrira pas :
·« pour tout x∈R, il existe y∈Rtq y3=x»
·«∀x∈R, il existe y∈Rtel que y3=x»
Le programme le dit explicitement : « l’emploi de quantificateurs en guise d’abréviations est exclu »
Le mieux est de bien distinguer dans quel mode on écrit : en « mode texte » (c’est-à-dire en bon français,
sans utiliser de quantificateurs) ou en « mode mathématique ».
Proposition 1.1.1 (négation d’une proposition avec quantificateurs)
Soit Pune propriété portant sur les éléments d’un ensemble E.
La négation de la proposition «∃x∈E, P(x)» est «∀x∈E, non P(x)»
La négation de la proposition «∀x∈E, P(x)» est «∃x∈E, non P(x)
1.1.6 Quelques synonymies classiques
Soit A,B,C, etc. des propositions.
Les équivalences suivantes sont toujours vraies :
Double négation :non ( non A)⇔AIdempotence :
(Aet A)⇔A
(Aou A)⇔A
Commutativité :
(Aet B)⇔(Bet A)
(Aou B)⇔(Bou A)Associativité :
((Aet B) et C)⇔(Aet (Bet C))
((Aou B) ou C)⇔(Aou (Bou C))
Dualité ou encore Lois de De Morgan :
non (Aet B)⇔(( non A) ou ( non B))
non (Aou B)⇔(( non A) et ( non B))
©Jean-Michel Ferrard Ce cours accompagne la souscription au site mathprepa.fr
Sa diffusion en dehors de ce cadre n’est pas autorisée
Page 5
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
1
/
506
100%