OPT-D3G2A: un nouveau Algorithme Génétique

OPT-D3G2A: un nouveau Algorithme Génétique Distribué Doublement Guidé
pour les CSOPs
Bouamama Sadok & Khaled Ghédira
SOIE/Université Tunis
Résumé
Les problèmes de satisfaction de contraintes
(CSPs) sont au cœur de nombreuses applications en
intelligence artificielle. Les CSOP sont une extension
des CSP. L’approche proposée dans ce papier
s’attaque à la résolution des CSOPs. Notre approche
est une Approche hybride des algorithmes génétiques,
qui profite à fond des avantages des systèmes multi-
agents pour pallier la complexité temporelle des
algorithmes génétiques. Ladite approche est guidée
par l’heuristique de minimisation des conflits et par le
concept des « templates ». Dans ce papier on
présentera la nouvelle approche ainsi que les
résultats expérimentaux.
1. Introduction
Les problèmes de satisfaction de contraintes (CSP)
sont au cœur de nombreuses applications en
intelligence artificielle et recherche opérationnelle, telles
que l'allocation de ressources, la planification,
l'ordonnancement. Un problème de satisfaction de
contraintes ou CSP, P = (X, D, C) est défini par :
- X est un ensemble fini de variables{X1,…,Xn}
- un ensemble D = {D1,…, Dn} de n domaines finis
pour les variables de X. Le domaine Di est associé à la
variable Xi
- C est un ensemble fini, éventuellement vide, de
contraintes C = {C1, C2,..., Cm} où une contrainte Ci est
définie par un sous-ensemble de variables : Ci = {Xi1,
Xi2, ..., Xin}.
La solution d’un CSP est une instanciation qui
satisfait toutes les contraintes.
Un CSOP [15] est un CSP avec une fonction
objectif. Cette dernière associe à chaque instanciation
une valeur numérique. La solution d’un CSOP est donc
une instanciation qui optimise la fonction objectif sans
violer de contraintes.
Les CSOP ont été traités par des méthodes
complètes et incomplètes. Les méthodes complètes,
sont capables de fournir des solutions optimales.
Malheureusement l’explosion combinatoire contrecarre
cet avantage. Les méthodes de la seconde famille dont
parmi les algorithmes génétiques (AG) [14] et la
recherche locale [14] ont toutes le même problème de ne
pas éviter le piège des optima locaux.
L’algorithme génétique distribué doublement guidé
(D3G2A)[1,2] a présenter de bon résultats pour les
Max_CSP. D3G2A est un algorithme génétique hybride,
il est guidé par l'heuristique de minimisation de conflit
et distribué sur la base de idées des niches
écologiques. La même idée que celle de D
3G2A est
adoptée pour les CSOP pour donner lieu à une nouvelle
approche que nous appellerons opt-D3G2A
Ce papier présente cette approche et il est organisé
comme suit : nous commencerons par présenter le OPT-
D3G2A; le traitement préliminaires des CSOP pour
pouvoir être traiter par notre approche, le concept de
base, la structures des agents et la dynamique globale.
La section suivante présentera le mode expérimental et
détaillera les expérimentations et les résultats
expérimentaux. En fin une conclusion et des éventuelles
perspectives seront proposées.
2. L’algorithme génétique distribué
doublement guidé pour les CSOP
2.1. Traitement préliminaire du CSOP
2.1.1. Formalisation. Etant donné un CSOP (X,D,C,f),
nous définissons F la fonction fitness augmentée
(AFF) d’une fonction potentielle sp, comme suit
g(sp) = f(sp) + λ * Σ(CPi * Ii(sp)); (1)
avec
λ: Paramètre de régularisation qui mesure la
contribution des pénalités dans la solution

sp : solution potentielle
Ii(sp) : indicateur de la solution = 1 si ps satisfait
toutes les contraintes, 0 ailleurs.
CPi : pénalité de la solution, ce compteur est
incrémenté de 1 à chaque fois que le voisinage de la
solution ne présente pas d’amélioration après un
certain nombre de génération. Ce dernier est appelé le
détecteur d’optima locaux (LOD)
2.1.2. Relation entre CSP et AG. Il à noter, en première
abord, que la relation entre les CSP et les AG est la
même retenue dans [1,2,3]. Chaque chromosome
(respectivement gène) est équivalent a une solution
potentielle du CSP (respectivement variable). Aussi,
chaque allèle correspond à une valeur. Chaque
chromosome est rattaché à une template [14] composé
de poids noté par templatei,j. chacun d’entre eux
correspond à une gènei,j où i est le chromosome et j to
la position. δi,j représente la valeur de la fonction G de
ce gène. Ces poids seront mis à jours par l’opérateur de
pénalité. L’idée est en fait inspirée du travail de E. P. K.
Tsang [14,15]
2.1.3. Probabilité de guidage. Les algorithmes
génétiques appartiennent à la famille des méthodes de
recherche locale (méthodes incomplètes). L'un des
premiers mécanismes d'amélioration de la recherche
locale consiste à diversifier la recherche pour échapper
aux optima locaux. Le mécanisme le plus simple pour
diversifier la recherche est sans nulle doute l'ajout du
bruit durant le processus de recherche. Dans [12], la
recherche effectue un mouvement aléatoire avec une
probabilité p et suit le processus normal avec une
probabilité 1-p. En effet, on est parfois amené à
dégrader une solution afin d'échapper au piège des
optima locaux.
Figure 1. Un exemple de bassin d’attraction
d’optima locaux
Dans Figure. 1, un exemple de bassin d'attraction
d'optima locaux est présenté; dans un cas de
maximisation, S2, qui est un maximum local, est meilleur
que S1 Le déplacement de S2 à S1 est considéré
comme destruction de la solution mais donne plus de
chance au processus de recherche pour atteindre S3
qui est l'optimum global.
Dans les algorithmes génétiques classiques, la
mutation est utilisée pour créer de la diversité dans la
population et pour éviter ainsi la dégénérescence de la
population. Dans le cas des AG guidés [14,15],
l'opérateur de mutation s'appelle improprement puisqu'il
s'agit en fait d'un opérateur d'amélioration du
chromosome considéré (changement de l'allèle qui
sonne une meilleure valeur pour la fonction fitness). Or,
si une valeur d’un gène n'existe pas dans la population,
on n'a aucun moyen ultérieur de l'obtenir par
croisement. Il est donc nécessaire d'avoir, de temps à
autre, des mutations aléatoires permettant de générer
les valeurs des gènes manquantes éventuellement.
L'idée est, donc, de créer un opérateur pourvoyeur de
hasard que nous appellerons probabilité de guidage
Pguid.
2.2. Modèle multi-agent
Étant donnée la population initiale, celle-ci sera
subdivisée en sous-populations. Les individus d’une
même sous population ont tous des valeurs de la
fonction AFF dans le même intervalle. Ensuite chacune
des sous-populations sera affectée à un agent appelé
agent espèce. La spécificité de chacun de ces agents
est l’intervalle des valeurs de AFF
L'interaction entre ces agents espèce se traduit par
le fait que chacun d'eux exécute son propre algorithme
génétique guidé par l'heuristique de minimisation de
conflits et par le concept de template. Un agent
intermédiaire appelé Interface se charge, en outre de la
création de nouveaux agents espèces, s'il est nécessaire
et pour détecter la meilleure solution partielle qui a été
atteinte durant l’interaction entre les agents Espèces.
2.2.1. Description des agents. Tout agent a une
structure composé de ses accointances (les agents qu’il
connaît et avec lesquels il peut communiquer), sa
connaissance dynamique, sa connaissance statique et
une boîte aux lettres nommée mailBox.
L’agent Espèce possède comme accointances les
autres agents Espèces et l’agent Interface. ses
connaissance statique : les données du CSOP (les
variables, leurs domaines de valeurs et les contraintes),
sa spécificité (un intervalle de valeur pour la fonction
AFF) et les paramètres de son algorithme génétique
local (probabilité de mutation, probabilité de
croisement, probabilité de guidage nombre de
générations, LOD, λ, etc). En fin, ses connaissance
dynamique : c’est la population de chromosomes qui
Optimum local
Optim
um global

varie d’une génération à une autre (les chromosomes et
leurs templates correspondants, taille).
L’agent Interface a comme accointances tous les
agents Espèce, sa connaissance statique consiste aux
données du CSP, et ses connaissance dynamique :
meilleur chromosome (le chromosome qui présente la
meilleure solution partielle).
2.2. Processus génétique détaillé de chaque
agent Espèce
Ce processus est différent de l'AG canonique par
l'utilisation des templates et de l'heuristique de
minimisation de conflits. Il commence par déterminer le
mating-pool qui comprend des paires de chromosomes
qui sont aléatoirement sélectionnées en utilisant la
procédure mettre_en_paire. A partir de chaque paire de
chromosomes, l'opérateur de croisement produit un seul
chromosome fils. Le croisement de deux chromosomes
parents n'aura lieu que si on génère un nombre
aléatoire, entre 0 et 1 inférieur à la probabilité de
croisement fixée par l'utilisateur au début du traitement.
En utilisant la nouvelle structure de données
template, un fils généré hérite les meilleurs gènes, i.e.
les gènes les plus "fort", de ses parents. La probabilité
pour un chromosome parent chromosomep (p=p1 ou
p2), où Somme=templatep1,q+ templatep2,q pour propager
son gènep,q à son chromosome fils est égale à 1-
(templatep,q/somme) . Ceci confirme le fait que les gènes
les plus forts, i.e. qui possèdent le plus grande valeur
de AFF, possèdent plus de chance que les autres d'être
hérités par le chromosome fils.
Pour chacun des chromosomes sélectionnés suivant la
probabilité de mutation P
mut , on applique aussi la
probabilité de guidage Pguid. L'utilisation de l'heuristique
de minimisation des conflits par l'Espècei est un
processus aléatoire de probabilité Pguid.
Si on n’a pas à utiliser le guidage, on effectuera une
mutation classique, aléatoire. Dans ce cas, l'un des
gènes du chromosome sera choisie aléatoirement. Une
valeur choisit aléatoirement de son domaine lui sera
affectée et le chromosome résultat va prendre la place
du chromosome muté.
Le cas échéant, il s'agit de parcourir le template
correspondant au chromosome et de déterminer le gène
(variable) qui est impliqué dans le minimum de la
fonction AFF, ensuite, on va sélectionner une valeur
pour ce gène à partir de son domaine et finalement
l'instancier par cette valeur.
De même, si on détecte plusieurs gènes qui
possèdent la même valeur de template, alors on choisit
aléatoirement l'un d'eux. On s'intéresse donc au gène le
plus "faible" vu qu'on veut maximiser ses chances
d'être remplacé par une autre valeur qui améliore valeur
de AFF. Si on n'arrive pas à améliorer le chromosome,
dans le sens que la valeur de son AFF demeure
inchangée, alors on prend la nouvelle valeur, en vue
d'améliorer l'exploration et si la valeur de la fonction
AFF du chromosome en question est plus petite, alors
on garde l'ancien chromosome.
Donc, selon l'opérateur de guidage on peut
dégrader une solution en vue de donner plus de chance
à l'exploration. Et la mutation sera une mutation à la fois
guidée et aléatoire. Si le chromosome donne une valeur
de AFF appartenant au même intervalle, alors il sera
ajouté à la population des chromosomes fils et Espècei
poursuit son comportement. Si non, Espècei vérifie
dans sa liste d'accointance en vue de chercher Espècej
correspondant à la spécificité de ce chromosome. Si ce
dernier existe alors on va lui envoyer le chromosome en
question sinon ce chromosome va être envoyé à l'agent
interface (qui va créer un nouvel agent Espècej et va lui
affecter le chromosome et informer les autres agents).
Il faut signaler qu'il y a le cas particulier d'une
population mono-chromosomique: une population est
dite mono-chromosomique si elle contient un seul
chromosome. Le processus génétique que nous lui
appliquons commence directement par l'opérateur de
mutation, du fait que les procédures d'appariement et de
croisement s'appliquent seulement sur une population
qui contient au moins deux chromosomes. Cet état (une
population de taille très réduite) ne persiste pas, étant
donné que grâce aux transferts de messages qui sont
fréquents d'une espèce à une autre, une telle sous-
population augmentera de taille au cours des
générations.
OPT-D3G2A est base sur le NEO-DARWINISM [17]
les lois de la nature « The Preservation of favoured
races in the struggle for life ». En effet nous
augmenterons la probabilité de croisement des espèces
fortes (une grande valeur de AFF) et nous diminuerons
la probabilité de mutation des espèces faibles. Donc
Pcross and Pmut seront calculés en fonction de la valeur de
la fonction fitness AFF et du nouvel opérateur que
nous appellerons ε. Cet opérateur est une pondération
ayant des valeurs dans l’intervalle 0 à 1.
Dans le but d’enrichir plus notre approche, nous
allons donner plus d’autonomie aux agents Espèce. En
effet nous ajoutons un nouvel opérateur pour
l’algorithme génétique utilisé. Cet opérateur est le LOD
pour détecteur d’optima locaux. Ce dernier représente le
nombre de génération pendant lesquelles le voisinage
ne présente pas d’améliorations c’est a dire que le
processus de recherche est bloqué dans un optimal

local. En effet si la valeur inchangée de AFF est
inférieure ou égale à l’ancienne valeur stationnaire de
AFF, LOD doit être égal à 1. Sinon, LOD est un
paramètre global du processus d’optimisation et doit
être, dynamiquement mis à jours par chaque agent
Espèce.
Nous mentionnons, que chaque agent sauvegarde
la meilleure valeur de AFF pour les générations
suivantes. Non seulement ceci va déterminer le cas de
stationnarité mais aussi il va déterminer le meilleur
chromosome de la population. Ainsi, si la solution
demeure inchangée dans LOD génération, le sous-
processus d’optimisation sera considéré bloqué dans
un optimal local. D’où, tout chromosome ayant cette
valeur de AFF sera pénalisé, c'est-à-dire que le
compteur de pénalité, qui lui est relié, sera incrémenté
de 1. Après chaque génération, chaque agent doit
envoyer à l’agent Interface une copie du meilleur
chromosome. En conséquence, l’agent Interface
compare les solutions, présentées par les meilleurs
chromosomes des agents Espèce, avec celle qu’il
détient. Il n’y a que les meilleures solutions qui seront
retenues
3. Expérimentation
Nos expérimentations porte sur le problème de la large
configuration des processeurs qui consiste à configurer
n processeur dans un système multiprocesseurs. Dans
ce réseau de processeurs, chaque processeur a besoin
de communiquer avec tous les autres processeurs.
Mais, en adoptant à une communication globale entre
les processeurs où chaque paire de processeur possède
un lien directe, cela compliquera énormément le réseau
ce qui touchera sa performance et son coût. D'où le
problème de la configuration de processeurs (PLCP).
Un PLCP est un problème NP-complet de la vie réel qui
concerne la conception du réseau d'un ensemble fini de
processeurs où chaque processeur a le même nombre
fini de canaux de communication [18]. Le but de nos
expérimentations est de comparer notre approche à
l’algorithme génétique guidé centralisé. [18] ont prouvé
que AGG donne de bons résultats dans le cas de PLCP.
Les expérimentations ont été faites avec ACTALK
[4], un environnement de Programmation Concurrents
Basés sur des Objets (OBPC) et plus généralement une
plate-forme multi-agent, au-dessus du langage orienté
objet Smalltalk, servant d’outil de développement, de
tests et d’expérimentations des systèmes multi-agents.
Ce choix d’ ACTALK se justifie par son aspect
convivial, son caractère réflexif, la possibilité
d’effectuer de la programmation fonctionnelle ainsi que
de la programmation orientée objet, et la simulation du
parallélisme.
Dans nos expérimentations nous exécutons 30 fois
l’algorithme et nous prenons la moyenne sans
considérer le point aberrants. Concernant les
paramètres de GA, toutes les réalisations emploient un
certain nombre des générations (NG) égale à 10, une
taille de population initiale égale à 1000, une probabilité
de croisement égale à 0,5, une probabilité de mutation
égale à 0,2, une probabilité de guidage égale à 0.5, LOD
étant égal à 3, λ à 10 et une pondération ε égale à 0.6.
Afin d'avoir une comparaison rapide et claire de
l'exécution relative à deux approches, les performances
sont évaluées par ces deux mesures ; On fixe le temps
CPU et on détermine pour ce temps les valeur de la
fonction fitness générés par les deux algorithmes
appliqués sur les mêmes problèmes. Puis on fixe la
valeur de la fonction fitness et on détermine pour cette
les temps CPU générés par les deux algorithmes
appliqués sur les mêmes problèmes.
La première montre la complexité temporelle tandis
que la seconde reflète la qualité de la solution.
Dans ce qui suit on comparera les résultats de notre
approches avec les résultats de l’algorithmes génétique
centralisé de E.P.K Tsang[14] noté par AGG. Ce dernier
est un algorithme génétique centralisé et guidé.
3.1. Résultats expérimentaux
Dans ce qui suit nous allons considérer les deux cas de
16 et 32 processeurs.
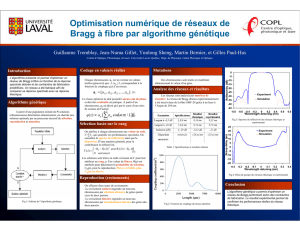
Figure 2. Temps CPU générés pour des valeur
fixe de AFF dans le cas de 16 processeurs
Les figures 2 et 4 illustre le point de vue temps
CPU, et montre que les résultats fournis par OPT-D3G2A
sont meilleurs par rapport à ceux donnés par AGG.
Nous mentionnons que l’écart entre les deux temps
devient plus important lorsqu’on augmente la valeur de
la fonction fitness. Ceci prouve que OPT-D3G2A
nécessite moins de temps pour résoudre un problème
donné.
0
50000
100000
150000
200000
250000
300000
350000
400000
450000
500000
1000 1500 2000 2500 3000
AFF
Temps CPU
OPT-D3G2A
AGG

Figure 3. Valeurs fixe de AFF générés pour des
Temps CPU fixes dans le cas de 16 processeurs
Figure 4. Temps CPU générés pour des valeur
fixe de AFF dans le cas de 32 processeurs
Figure 5. Valeurs fixe de AFF générés pour des
Temps CPU fixes dans le cas de 32 processeurs
Le point de vue valeur de la fonction fitness est
exprimé dans les figures. 3 et 5, le OPT-D3G2A atteint
toujours, pour un temps CPU fixe, une meilleure valeur
de la fonction fitness. Cette valeur est plus significative
pour temps CPU plus importants. Ceci exprime
clairement l’apport en terme de qualité de la solution
trouvée.
Dans la suite, nous présenterons un deuxième
modèle de comparaison entre les deux algorithmes. Il
s’agit de :
- Ratio temps CPU=temps CPU AGG / temps CPU OPT-
D3G2A.
- Ratio fitness= AFF OPT-D3G2A. / AFF AGG
Figure 6. Ratio temps CPU
La figure 6 montre bien que le ratio Temps CPU est,
toujours, supérieur à 1 pour les problèmes de plus en
plus complexe en terme de nombre de processeurs. Ce
ratio confirme l’apport de notre approche en terme de
complexité temporelle.
Figure 7. Ratio fitness
La dernière figure exprime le point de vue qualité de la
solution. En effet notre approche donne au pire des ces
une solution meilleur que celle donnée par AGG. La
solution devient remarquablement meilleure pour les
problèmes les plus difficiles.
4. Conclusion et perspective
Dans ce travail, nous avons développé un
algorithme génétique guidé distribué enrichi par un
nouveau paramètre appelé la probabilité de guidage.
Comparé à l’algorithme génétique centralisé guidé,
notre approche est, expérimentalement, prouvée,
meilleure en terme de complexité temporelle et en terme
de qualité de la solution trouvée.
L'amélioration est, en premier lieu, due à la
diversification qui augmente la convergence
d'algorithme en s'échappant du bassin d'attraction des
optima locaux. Et au guidage qui aide l'algorithme pour
atteindre des optima. En effet, notre approche donne
0
500
1000
1500
2000
2500
3000
3500
4000
4500
50000
100000
150000
200000
250000
300000
350000
400000
Temps CPU
AFF
OPT-D3G2A
AGG
0
500000
1000000
1500000
2000000
2500000
1000 1500 2000 2500 3000
AFF
Temps CPU
OPT-D3G2A
AGG
0
500
1000
1500
2000
2500
3000
3500
4000
4500
200000
500000
750000
1000000
1250000
1500000
1750000
2000000
Temps CPU
AFF
OPT-D3G2A
AGG
0
0,5
1
1,5
2
2,5
Ratio
temps CPU
8 12 16 20 32
nombres des processeurs
0
0,5
1
1,5
2
2,5
ratio AFV
8 12 16 20 32
nombre des processeurs
 6
6
1
/
6
100%