Processus de Galton-Watson - Université Paris-Sud


n
ZR
eax2+bx+cdx

N
a0
a1a2a5
n
k
k pkk
k

X
N
R
[−1,1]
φX
φX: [−1,1] →R
s7→ X
n>0
P(X=n)sn.
φX
[−1,1]
s∈[−1,1]
X
k>0
P(X=k)sk
6X
k>0
P(X=k)=1<+∞.
s∈[−1,1]
φX(s) = X
n>0
snP(X=n) = E(sX).
φX
X
X Y N
φX=φYs∈[−1,1]

φX(s)−φY(s) = X
k>0
[P(X=k)−P(Y=k)]sk= 0
φX−φY0
P(X=k) = P(Y=k)k∈N
φX
k∈N
P(X=k) = φ(n)
X(0)
n!
E(X) = φ0
X(1)
V(X) = φ00
X(1) + φ0
X(1) −(φ0
X(1))2
φX1
C∞]−1,1[ s∈]−1,1[ φ0
X(s) = P
k>1
kP(X=k)sk−1
φ0
X(1) = X
k>0
kP(X=k) = E(X)
φ00
X(1) = X
k>0
k(k−1)P(X=k)
φ00
X(1) + φ0
X(1) −(φ0
X(1))2=X
k>0
P(X=k)k2−E(X)2=E(X2)−E(X)2
X Y
N
φX+Y=φXφY
s∈]0,1[ φX+Y(s) = E(sX+Y) = E(sXsY)
s > 0t7→ stt7→ etln(s)
R
X Y
sXsY
φX+Y(s) = E(sX)E(sY) = φX(s)φY(s)
φX+YφXφY
]0,1[ φX+Y=φXφY
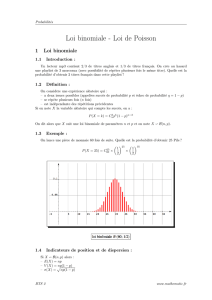
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
1
/
33
100%