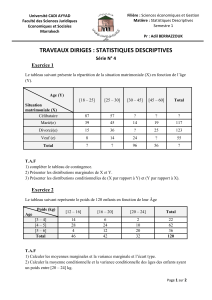
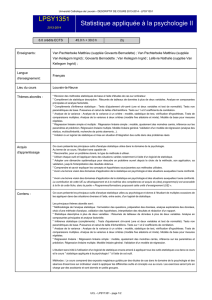
R-cours 7

Cours 7 : Rappels de cours et exemples sous
R
I- Régression linéaire simple
II- Analyse de variance à 1 facteur
III- Tests statistiques

I- Le modèle de régression linéaire simple:
théorie
Rappels On cherche à expliquer ou à prévoir les variations d’une variable Y
(variable dépendante) par celles d’une fonction linéaire de X (variable
explicative), i.e., à valider le modèle de RLS
Y aX b
ε
= + +
où est une variable aléatoire gaussienne de moyenne nulle et de variance
Pour cela on observe un n-échantillon de réalisations de X et de Y, sur
lesquelles on va chercher à voir si le lien est plausible,
i.e. si il existe a, b et
(validation)
Avec i.i.d. Gaussiennes et pas trop grand,
et à approcher les valeurs des paramètres a, b, et (estimation)
, 1,..., .
i i i
y ax b i n
ε
= + + =
²
σ
²
σ
²
σ
ε
i
ε
²
σ

I- Le modèle de régression linéaire simple:
théorie
Estimation des paramètres :
• Estimation de a et b : On commence par chercher le « meilleur » ajustement
linéaire sur nos données, au sens des moindres carrés :
=i
°
valeur estimée
ˆ
y ax b
= +
=i
°
valeur estimée
= i° résidu
et sont tels que est minimal. Ce sont les
coefficients de la régression (ou estimateurs des moindres carrés).
2
1 1
ˆ
ˆ
( )²
n n
i i i
i i
e y ax b
= =
= − −
∑ ∑
ˆ
a
ˆ
b
ˆ
ˆ
y ax b
i i
e y y
i i i
= +
= −

I- Le modèle de régression linéaire simple:
théorie
On montre que :
•
La droite d’ajustement s’appelle droite de régression ou des
1
1
( )( ) ˆ
ˆ ˆ
,
( )²
n
i i
in
i
i
x x y y
a b y ax
x x
=
=
− −
= = −
−
∑
∑
ˆ
ˆ
y ax b
= +
•
La droite d’ajustement s’appelle droite de régression ou des
moindres carrés.
• La valeur estime la valeur moyenne de Y lorsque X=xi (E(Y/X=xi)) .
C’est aussi la prévision de Y pour une observation telle que X=xi.
• Estimation de : La variance de l’erreur s’estime par
ˆ
y
i
2
1
²
2 2
n
i
i
e
SSR
s
n n
=
= =
− −
∑
ˆ
ˆ
y ax b
= +
²
σ

I- Le modèle de régression linéaire simple:
théorie
Validation du modèle sur les données :il faut que le modèle soit de
bonne qualité (bon pouvoir explicatif et prédictif)
• Analyse de la qualité du modèle : Décomposition de la variabilité
=somme des carrés des variations de y
2
( )²
i Y
SST y y ns
= − =
∑
=somme des carrés des variations expliquées
par le modèle
=somme des carrés des variations résiduelles
On montre que : SST=SSR+SSM
Au plus SSM est grand (ou SSR faible), au meilleur est l’ajustement.
2
ˆ
ˆ
( )²
i
Y
SSM y y s
= − =
∑
2 2
( 2)
i
SSR e n s
= = −
∑
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
1
/
66
100%