N - Institut d`électronique et d`informatique Gaspard

Eric Laporte
Institut Gaspard-Monge
Université Paris-Est Marne-la-Vallée
France
http://www-igm.univ-mlv.fr/~laporte/
Etiquettes lexicales, grammaires

Tokenisation
Rappel et précision en recherche d'informations
Élaboration d'une requête
Grammaires locales
Informations lexicales
Etiquettes lexicales
Lexiques pour le traitement des langues
Ambiguïtés
Consultation
Structures de traits
Recherche de formes
Masques lexicaux
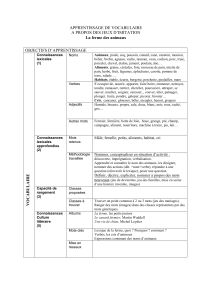
Objectifs

Tokenisation

Tokenisation (1/2)
Tokens : éléments simples d'un texte écrit
Passer d'une séquence de caractères à une séquence de tokens
Je vais fermer l'autre porte
/Je/vais/fermer/l/'/autre/porte/
Définition des tokens
Les mots délimités par des espaces ?
/l'autre/ /autre,/
Certains symboles
- peuvent gêner la comparaison entre mots
- peuvent avoir une importance en eux-mêmes
/l/'/autre/ /autre/,/
Tokens-mots et tokens-non-mots

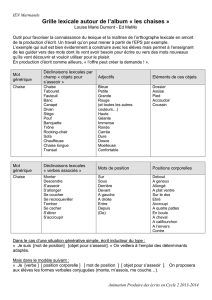
Tokenisation (2/2)
Définition par les délimiteurs
Simple
Fournit seulement les tokens-mots
Définition par les tokens
Fournit les tokens-mots et les tokens-non-mots
Permet de séparer 2 tokens sans délimiteur. Ex. :
60%, 1970s, G8
Dans les deux cas, expressions rationnelles
[^\w\s] un symbole de ponctuation
\w+ une séquence d'1 ou plusieurs caractères alphanumériques
\d+ une séquence d'1 ou plusieurs chiffres
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
1
/
55
100%