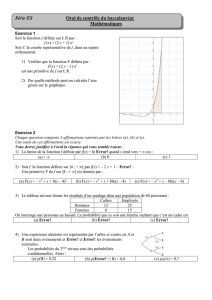
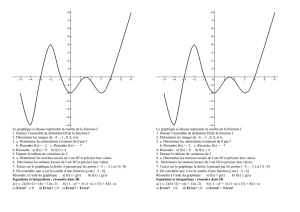
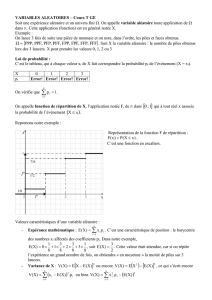
PROFILING SANS EXÉCUTION

PROFILING SANS EXÉCUTION
Mémoire de fin d’études
Master d’Informatique
Etudiant : BUI Nguyen-Minh
Sous la direction de :
Professeur Danny DUBÉ
Département d’informatique, Université LAVAL
Institute de la Francophonie pour l’Informatique
Novembre 2006

Remerciements
Je voudrais remercier professeur Danny Dubé au Département d’Infor-
matique et de Génie Logiciel à l’Université Laval pour tout ce qu’il a fait
pour moi pendant mon stage, même je n’étais pas très autonome. Je tiens
également à remercier tous les professeurs à l’IFI. Merci à mes parents et mes
amis.
1

Résumé
Dans cette mémoire, nous voudrions présenter une autre façon pour faire le
profiling. Les méthodes courantes, en général, elles ajoutent quelques mor-
ceaux de code sources et exécutent le programme pour calculer le profil d’un
programme. Par contre, notre méthode, elle n’exécute pas le programme mais
essaye de construire un système qui modèle l’exécution du programme puis
calcule le profil basé sur le résultat obtenu quand on résout le système. Cette
méthode se compose de deux phases. La première phase vise à calcul le résul-
tat abstrait en utilisant un système de contrainte. Dans la deuxième phase,
utilisant le résultat de la première phase, on construit et résout un système
d’équation pour obtenir un résultat plus détaillé. Pourtant, la méthode de
profiling sans exécution reste de nombreux de problèmes sur le processus
de la modélisation le programme, la solution le système, la convergence du
système et l’évaluation. Nous abordons aussi quelques idées générales sur le
langage fonctionnel et le langage de programmation Scheme.

Table des matières
1 Introduction 1
1.1 Profiling.............................. 1
1.2 Typesdeprofiling......................... 1
1.3 Sujetdestage........................... 2
2 Langage fonctionnel 3
2.1 Concepts.............................. 3
2.2 Particularité des langages fonctionnels . . . . . . . . . . . . . 3
2.2.1 Absence des effets de bord . . . . . . . . . . . . . . . . 3
2.2.2 Transparence référentielle . . . . . . . . . . . . . . . . 4
2.2.3 Peu de structures de contrôle . . . . . . . . . . . . . . 5
2.2.4 Fonctions comme objets de première classe . . . . . . . 6
2.2.5 Gestion de la mémoire de façon automatiquement . . . 6
2.3 Lambdacalcul........................... 6
2.3.1 Idées générales . . . . . . . . . . . . . . . . . . . . . . 6
2.3.2 La syntaxe du lambda calcul . . . . . . . . . . . . . . . 7
2.3.3 Alpha réduction . . . . . . . . . . . . . . . . . . . . . . 8
2.3.4 Beta réduction . . . . . . . . . . . . . . . . . . . . . . 8
2.4 Schème............................... 8
3 Pré-traitement 9
3.1 Langage à analyser . . . . . . . . . . . . . . . . . . . . . . . . 9
3.2 Analysedejetons......................... 11
3.3 L’algorithme en bref . . . . . . . . . . . . . . . . . . . . . . . 11
4 Analyse abstraite 13
4.1 Valeurs abstraites . . . . . . . . . . . . . . . . . . . . . . . . . 13
4.2 Idéegénérale ........................... 14
4.3 Génération des contraintes . . . . . . . . . . . . . . . . . . . . 14
4.4 Commentaires........................... 17
4.5 Unexemple ............................ 17
i

5 Analyse statique 19
5.1 Idéegénérale ........................... 19
5.1.1 Définitions......................... 19
5.2 Système d’équation . . . . . . . . . . . . . . . . . . . . . . . . 20
5.2.1 Règles pour calculer Πl:................. 20
5.2.2 Règles pour calculer Πx:................. 22
5.2.3 Règles pour calculer χlet Kl(l0): ............ 22
5.3 Vérifier les équations . . . . . . . . . . . . . . . . . . . . . . . 24
5.4 Résoudre le système d’équations . . . . . . . . . . . . . . . . . 29
5.5 Unexemple ............................ 31
6 Conclusion 34
ii
 6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
1
/
41
100%